Zephyr 实时操作系统:进阶指南
在本课程中,我们将深入探讨 nRF Connect SDK/Zephyr 中的线程管理和数据传递。我们有两种执行上下文:线程上下文和中断上下文。每种上下文都有其特定的使用场景和时序影响。
我们将首先研究不同的执行原语,以及不同类型的线程和不同类型的中断如何共存。然后我们将更详细地了解线程的生命周期和调度器的工作原理。之后,我们还将介绍常用的数据传递技术,如消息队列和 FIFO。
课程结束时,您将对调度应用程序任务的各种选项及其不同的时间约束有扎实的理解。您还将熟练掌握如何在线程之间安全地传递数据以及可用的内核选项。
启动顺序与执行上下文
核心概念:任务的执行方式
在编写嵌入式应用程序时,代码中的不同任务需要以特定的方式来运行。这些方式被称为“执行原语 (execution primitive)”,常见的有以下几种:
可抢占线程 (preemptible thread):可以把它想象成一个普通的任务。当一个更紧急的任务(比如一个更高优先级的线程或一个硬件中断)出现时,这个线程会被系统强制暂停,让更紧急的任务先运行。
协作式线程 (cooperative thread):这种任务一旦开始运行,就会一直运行下去,直到它自己主动放弃 CPU 的使用权。它不会被同等优先级的其他任务打断。
工作队列 (work queue):可以理解为一个“任务处理池”。当有一些简短、零散的工作需要处理时,可以把这些工作打包好,扔进这个池子里。系统会有一个专门的线程来依次处理这些工作。这样做的好处是避免了为每一个小任务都创建一个完整线程的开销。
为任务选择合适的执行方式并设定正确的优先级至关重要。这能确保紧急的任务得到及时处理,同时又不会让非紧急的任务长时间霸占处理器,影响整个系统的响应。
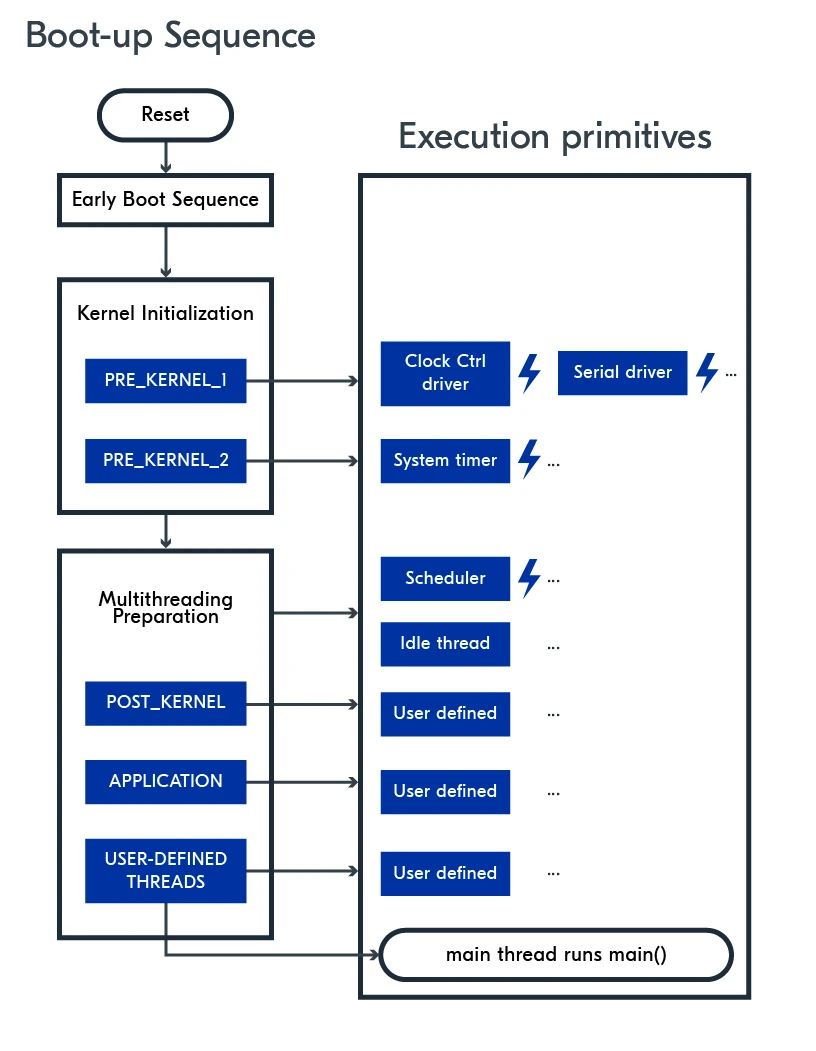
要掌握如何合理地安排任务,首先需要理解一个 nRF Connect SDK 应用程序从上电到运行的全过程,以及代码执行时所处的两种不同“环境”。
第一部分:应用程序的启动流程
一个 nRF Connect SDK 应用程序的启动过程可以分为几个清晰的阶段,就像盖房子一样,从打地基到内部装修,顺序井然。这里的 nRF Connect SDK 是一个开发工具包,其核心是 Zephyr 实时操作系统 (RTOS)。
阶段一:早期启动(准备 C 代码运行环境)
这是系统上电后的第一个阶段。它的唯一目标是进行最基础的硬件设置,让处理器能够开始执行 C 语言代码。这个过程对于嵌入式系统来说是标准流程,应用开发者通常不需要关心其中的细节。
阶段二:内核初始化(准备核心驱动)
在这个阶段,系统开始初始化各种设备驱动程序。这些驱动程序是在编译时就已经确定好的,因此被称为“静态设备”。这个阶段发生在操作系统内核的核心功能(如线程调度)启动之前,所以这里的初始化代码不能调用任何需要内核支持的函数(例如 k_sleep() 这样的延时函数)。
初始化的顺序由“运行级别 (run level)”严格控制,主要分为两个子阶段:
PRE_KERNEL_1级别:初始化最最基础的驱动。时钟控制驱动 (Clock Control driver):为系统提供“心跳”。时钟是所有其他硬件模块工作的基础。
串行驱动 (A serial driver):例如 UART 串口驱动。如果启用了调试功能,这个驱动会被初始化,以便能通过串口打印出启动信息和日志。
PRE_KERNEL_2级别:初始化依赖于上一阶段的基础驱动。- 系统定时器驱动 (System Timer driver):为操作系统提供一个精确的时间基准。内核后续提供的所有计时服务,比如线程休眠、定时器 API 等,都依赖于它。
重要提示:
这里列出的只是最核心的、保证 RTOS 运行所必需的设备。一个实际的应用程序会根据
prj.conf配置文件和板级配置,初始化更多的设备驱动。
阶段三:多线程准备(操作系统核心功能启动)
这是操作系统真正“活”起来的阶段。
POST_KERNEL级别:调度器 (scheduler) 初始化:操作系统的“交通指挥官”——调度器,在此时启动。它的职责是决定在任何时刻,哪个线程应该获得 CPU 的使用权。
系统线程创建:RTOS 会创建两个核心的系统线程:
主线程 (main thread):它的最终任务是去调用程序员编写的
main()函数。空闲线程 (idle thread):这是一个最低优先级的线程。当系统中没有任何其他任务需要运行时,调度器就会让空闲线程运行。它通常用来执行功耗管理,让芯片进入休眠状态以省电。
打印启动信息:此时,屏幕上会打印出熟悉的启动横幅,例如
*** Booting nRF Connect SDK v2.x.x ***。初始化依赖内核的服务:许多复杂的模块,如低功耗蓝牙 (Bluetooth Low Energy) 协议栈或日志系统,因为它们自身的初始化过程需要内核服务(比如创建自己的专用线程),所以必须在这个阶段进行初始化。
APPLICATION级别:初始化应用程序级服务:一些应用层面的库会在这里初始化。
启动用户线程:所有由程序员使用
K_THREAD_DEFINE()宏静态定义的线程会在此刻被创建并准备就绪。调用
main()函数:最后,主线程会调用我们熟悉的main()函数,应用程序的入口点。从这里开始,程序的控制权就交给了应用开发者。如果代码中没有定义main()函数,主线程会直接结束,调度器则会根据优先级选择下一个就绪的线程来运行。
第二部分:两种执行“上下文”——线程与中断
在程序运行时,代码总是在某一个特定的“执行上下文 (execution context)”中执行。可以把上下文理解为代码运行时所处的“环境”或“状态”。主要有两种上下文:线程上下文 和 中断上下文。理解它们的区别至关重要,因为在不同的上下文中,能做和不能做的事情有天壤之别。
可以打个比方:线程上下文就像是在办公室里按计划处理日常工作,而中断上下文则像是突然响起了火警警报,必须立刻放下手头的一切去处理紧急情况。
线程上下文 (Thread context)
这是什么?:这是应用程序代码运行的常规、正常的环境。无论是系统的主线程,还是用户自己创建的线程,都运行在线程上下文中。
如何触发?:由操作系统的调度器根据优先级和状态来决定哪个线程运行。这是一个受控的、可预测的过程。
特点:
可以被中断或更高优先级的线程“打断”(即抢占)。
可以执行耗时较长的复杂计算。
可以做什么?(几乎所有事)
调用操作系统提供的全部服务,例如内存分配、线程间通信等。
可以“等待”或“睡眠”(即阻塞),比如调用
k_sleep()函数,或者等待一个设备准备好数据。可以使用同步原语 (synchronization primitives),如互斥锁 (mutexes) 或信号量 (semaphores),来安全地协调多个线程对共享资源的访问。
中断上下文 (Interrupt context)
这是什么?:当一个硬件事件(例如,引脚电平变化、定时器超时、数据通过串口到达)发生时,CPU 会立即暂停当前正在执行的任何代码,转而执行一个预先定义好的特殊函数,即中断服务程序 (Interrupt Service Routine, ISR)。这个 ISR 运行的环境就是中断上下文。
如何触发?:由硬件异步触发,无法在代码中预测它何时发生。
特点:
它会立即“打断”(抢占)当前运行的线程。
执行必须极快。中断处理的目标是“快进快出”,因为它暂停了系统中的所有常规活动。长时间占用中断上下文会导致系统响应迟钝,甚至丢失其他更重要的中断。
Zephyr 支持中断嵌套,即一个低优先级的中断在执行时,可以被一个更高优先级的中断打断。
可以做什么?(非常有限)
执行对时间要求极高的、简短的操作(例如,从硬件寄存器读取一个字节,或者设置一个标志位)。
可以调用一小部分被明确标记为“可在 ISR 中安全调用”的内核函数。
绝对禁止做什么?
任何可能导致“等待”或“睡眠”的操作(即阻塞)。在中断上下文中,代码绝不能被阻塞。因为当中断被阻塞时,被它打断的线程也无法恢复运行,如果这个线程恰好是高优先级的,整个系统可能会因此“卡死”。
调用绝大多数为线程上下文设计的内核服务,比如
k_sleep()、获取互斥锁等。
线程的生命周期
线程 (thread) 是可运行代码的基本单元。在固件开发中,绝大多数代码都运行在线程之中。这些线程的来源各不相同,可能是由用户直接定义的线程,也可能是由实时操作系统 (RTOS) 创建的线程(例如系统工作队列的线程),或者是某个 RTOS 子系统(例如日志模块)或第三方库(例如 AT 指令监控库)创建的线程。
一个线程由什么组成?
一个完整的线程包含以下几个核心要素:
线程控制块 (Thread control block):它的数据类型是
k_thread。可以把它理解为每个线程的“身份证”或“档案”。RTOS 内部会为每一个线程维护一个这样的实例,用来记录和追踪该线程的所有信息,也就是它的元数据 (metadata)。栈 (Stack):每个线程都拥有自己独立的栈空间。栈用于存放函数调用时的局部变量、返回地址等信息。栈的大小必须根据该线程所执行任务的复杂程度来合理设置,设置过小会导致栈溢出,引发程序崩溃。
入口点函数 (Entry point function):这是线程的核心,也就是线程所要执行的具体功能代码。通常,这个函数内部会包含一个无限循环(例如
while(1)),因为一旦从这个函数返回,就意味着线程的生命周期结束了。创建线程时,可以向其入口点函数传递最多三个可选的参数。线程优先级 (Thread priority):它是一个有符号整数,用于决定线程的“类型”和重要程度。操作系统的调度器会根据这个优先级来决定如何为该线程分配 CPU 时间。
可选的线程选项:通过这个可选字段,可以为线程赋予一些特殊属性,使其在特定情况下得到特殊处理。
可选的启动延时:可以指定线程在创建后是立即开始运行,还是等待一段指定的时间后再运行。如果希望立即运行,可以传递
K_NO_WAIT(即延时为 0)。
如何创建一个线程?
创建线程通常有两种方式:使用宏 K_THREAD_DEFINE() 或使用函数 k_thread_create()。
无论使用哪种方式,都必须为线程静态地分配栈空间(截至 Zephyr RTOS v3.4.0 版本,尚不支持动态创建线程)。
使用
K_THREAD_DEFINE()宏时,它会自动处理栈的分配,开发者只需将期望的栈大小作为参数传递给这个宏即可。这是一种更便捷的方式。如果使用
k_thread_create()函数,则必须预先使用K_THREAD_STACK_DEFINE()宏来手动为线程分配好栈空间。
创建线程时,可以选择让它立即启动,或是在指定的延时后启动。一旦线程被启动,它就会被放入一个名为“就绪队列”的特殊列表中。
此外,还可以通过将启动延时设置为 K_FOREVER 来创建一个处于非活动状态的线程。这样的线程被创建后不会立即运行,需要之后通过调用 k_thread_start() 函数来显式地“唤醒”它,将其加入就绪队列。
定义:就绪队列 (Ready queue)
就绪队列是所有处于“就绪”状态的线程的集合。可以把它想象成一个“候车室”,里面的线程都已经准备好,随时可以运行。操作系统的调度器在决定下一个该由哪个线程占用 CPU 时,只会从这个队列中进行选择。
线程的状态与生命周期
一旦调度器从就绪队列中选择了某个线程来执行,该线程的状态就变为 运行 (Running)。线程会一直保持运行状态,直到发生以下几种情况之一:
线程进入“非就绪”状态 线程会因为各种原因暂停执行,进入以下几种状态:
休眠 (Sleeping):线程主动调用
k_sleep()或类似的函数,决定让自己“睡”一段时间。挂起 (Suspended):由另一个线程调用
k_thread_suspend()函数,强制将该线程暂停。等待 (Waiting):线程需要等待某个当前不可用的内核对象(例如,尝试获取一个已被其他线程占用的互斥锁或信号量)。
线程主动让出或被动抢占 CPU
让步 (Yielding):线程主动调用
k_yield()函数,自愿放弃 CPU,并把自己排到就绪队列的末尾,让其他同优先级的线程有机会运行。被抢占 (Preempted):当一个更高优先级的线程变为就绪状态时,调度器会立即暂停当前正在运行的线程(无论它是否愿意),让更高优先级的线程先运行。被抢占的线程会被放回就绪队列中。
线程的终止或中止
线程的执行最终会通过终止或中止的方式结束。
终止 (Termination):这是一种正常的结束方式。当线程的入口点函数执行完毕并返回时,线程就会被终止。这种情况通常发生在线程需要执行的是一次性的、非重复性的任务时。
中止 (Aborting):这是一种异常的结束方式。当中止发生时,线程会被立即停止。可能的原因包括:
线程遇到了致命的错误条件,例如解引用一个空指针,此时 RTOS 会自动中止该线程。
由另一个线程或线程自身调用
k_thread_abort()函数来刻意中止它。
调度器深度解析
调度器 (scheduler) 的任务非常直截了当:从“就绪队列 (ready queue)”(即所有准备好运行的线程的列表)中,挑选一个线程作为当前活动的 运行 (Running) 线程,并将 CPU 的使用权交给它。
Zephyr / nRF Connect SDK 中的调度器
调度器选择哪个线程来运行,是完全由一套确定性规则决定的。这些规则的核心就是每个线程的重要性——即优先级 (priority)。作为一个实时操作系统 (RTOS) 的调度器,它不关心“公平性”或者某个线程过去执行了多久。这意味着,作为固件开发者,必须通过为每个线程设置正确的优先级,来亲自决定如何让所有线程共享 CPU 资源。
上下文切换 (Context Switch)
要理解调度,首先需要理解一个核心概念:上下文切换。
可以把一个线程的“上下文 (context)”想象成一个工人正在工作时的“工作现场状态”。这个状态包括了 CPU 中所有寄存器里的当前值、线程自己栈里的数据等等。
线程在执行时,并不知道自己会在何时被调度器抢占(被另一个线程打断),或被中断服务程序 (ISR) 中断。设想一个场景:一个线程正准备执行一条指令,将两个寄存器(例如 R0 和 R1,值都为 0x05)中的数值相减。就在执行前的一瞬间,它被抢占了。在它被暂停期间,其他线程会运行,并且很可能会修改 R0 和 R1 寄存器的值。当原来的线程最终被重新调度回来执行时,如果它直接使用已经被改变了的寄存器值进行减法运算,结果显然是错误的。
为了防止这类错误,当一个线程被暂停后恢复执行时,它的“工作现场状态”必须和被暂停前的状态完全一致。RTOS 通过在抢占一个线程时保存其完整的上下文,并在其恢复执行前恢复其上下文来确保这一点。这个保存和恢复的过程,就叫做上下文切换。
关于上下文切换的说明
上下文切换因为涉及数据的复制,会消耗一定的 CPU 时间。因此,在固件开发中,应尽可能减少不必要的上下文切换。同时要记住,中断发生时,同样会发生上下文切换。
线程的类型
在 nRF Connect SDK 中,线程主要分为两种类型:可抢占线程 (Preemptable threads) 和 协作式线程 (Cooperative threads)。此外,还有一种特殊的协作式线程,称为 元中断线程 (Meta-IRQ threads)。
1. 可抢占线程 (Preemptable threads)
这是最常用的线程类型,适用于绝大多数用户应用场景。它们之所以被称为“可抢占”,是因为只要有一个更高优先级的线程准备就绪,调度器就可以随时暂停(即抢占)它们,让更高优先级的线程先运行。
- 识别方式:其优先级为一个非负数(大于或等于 0)。
2. 协作式线程 (Cooperative threads)
协作式线程的创建方式与可抢占线程相同,唯一的区别是赋予它的优先级是一个负数。
它的核心特点是:调度器不能抢占一个正在运行的协作式线程。这意味着,一个协作式线程一旦开始运行,就会一直霸占着 CPU,直到它自己主动放弃,例如通过调用 k_sleep() (休眠)、等待某个资源、或者调用 k_yield() (让步)。
主要用途:实现“调度器锁定 (scheduler locking)”。当把一个任务实现为协作式线程时,就可以确保在它运行期间,不会有其他任何线程来“插队”,从而天然地避免了多线程同步问题,无需使用互斥锁等同步机制。
重要提醒:中断仍然可以打断一个正在运行的协作式线程。但是,当中断服务执行完毕后,CPU 的控制权保证会返回给刚刚被打断的那个协作式线程。对于可抢占线程,则没有这个保证(因为在中断处理期间,可能有更高优先级的线程变为就绪状态)。
协作式线程常用于一些子系统、网络协议栈和设备驱动中,以实现互斥访问。在某些对性能要求极高的用户应用场景中,也可以使用它。
3. 元中断线程 (Meta-IRQ threads)
这是一种更加特殊的协作式线程,不建议用于普通的用户应用程序,但了解它有助于理解系统底层的工作方式。
元中断线程主要用于设备驱动中,处理中断的“下半部分 (bottom half)”工作。通常,中断服务程序 (ISR) 应该尽可能简短。如果中断后需要立即执行一些较为复杂的、但又非常紧急的线程级任务,该怎么办?如果使用普通线程,无法保证它能在中断结束后立即被调度。
解决方案就是使用元中断线程。将驱动的“下半部分”任务实现为一个元中断线程,可以保证在硬件中断服务程序 (ISR) 结束后,该线程会被立即触发执行,几乎没有延迟。例如,低功耗蓝牙协议栈就使用这种机制来保证实时性。
线程优先级详解
创建线程时,需要为其分配一个整数作为优先级。数值越小,优先级越高。
例如,优先级为 4 的线程比优先级为 7 的线程有更高的优先权。
同理,优先级为 -2 的线程比优先级为 4 和 7 的线程都有更高的优先权。
调度器正是根据优先级的正负来区分线程类型的:
负数优先级:协作式线程。
非负数优先级:可抢占线程。
默认情况下,系统定义的优先级范围如下:
可抢占优先级:由
CONFIG_NUM_PREEMPT_PRIORITIES定义,默认为 15 个级别(0 到 14)。main线程的默认优先级是 0。idle(空闲) 线程的默认优先级是 15。开发者不应使用这个最低优先级。如果使用日志模块的延迟模式,
logger(日志) 线程的优先级是 14。推荐用户线程使用的最低优先级是 14。
协作式优先级:由
CONFIG_NUM_COOP_PRIORITIES定义,默认为 16 个级别(-1 到 -16)。- 系统工作队列 (
System work queue) 线程就是一个优先级为 -1 的协作式线程。
- 系统工作队列 (
线程的优先级可以在其启动后被动态地修改。这意味着,一个可抢占线程也可能通过改变优先级变为协作式线程,反之亦然。
调度器锁定与中断禁用
在执行一些不希望被任何其他代码打扰的“关键代码区 (critical section)”时,需要特殊的保护机制。
调度器锁定 (Scheduler locking): 这是一种暂时“冻结”调度器的机制,防止在不同线程之间发生上下文切换。它能确保一段代码原子化地执行,不受其他线程的干扰。
对于协作式线程,这种锁定是其内在属性,自动生效。
对于普通的可抢占线程,可以通过调用
k_sched_lock()和k_sched_unlock()函数来手动锁定和解锁调度器。k_sched_lock()的效果相当于暂时将当前线程的优先级提升为协作式优先级。注意:调度器锁定并不能阻止中断的发生。
中断禁用 (Disabling interrupts): 如果一段代码既不能被其他线程抢占,也不能被中断打断,那么就需要使用终极保护措施:禁用中断。可以通过调用
irq_lock()和irq_unlock()函数来实现。在irq_lock()和irq_unlock()之间的代码,可以认为是绝对安全的,不会被任何外部事件打扰。
处理同优先级的线程
系统中可以有多个优先级完全相同的线程。当这些线程都处于就绪状态时,调度器如何选择呢?除了默认行为外,还有两种可选策略。
默认行为(先进先出,FIFO): 调度器会选择那个最早进入就绪队列的线程来运行。
时间切片 (Time slicing): 通过 Kconfig 选项
CONFIG_TIMESLICING启用。启用后,每个同优先级的线程都会被分配一个固定的运行“时间片”。当一个线程用完了它的时间片后,即使它还想继续运行,调度器也会强制将其抢占,并让下一个同优先级的线程运行。这为同优先级的线程提供了一种“雨露均沾”的公平调度机制。重要:时间切片只对同优先级的线程有效,不会影响高优先级线程对低优先级线程的抢占。最早截止期优先 (Earliest Deadline First, EDF): 通过 Kconfig 选项
CONFIG_SCHED_DEADLINE启用。这是一种更高级的调度策略。开发者必须为每个线程设置一个预估的“截止期限 (deadline)”。当多个同优先级的线程就绪时,调度器会选择那个截止期限最早(剩余时间最短)的线程来运行。
重调度点 (Rescheduling Points)
Zephyr 是一个默认使用无滴答内核 (tickless kernel) 的操作系统。传统的操作系统内核依赖一个周期性的硬件定时器中断(称为“系统滴答 (system tick)”)来触发调度。这种方式无论系统是否繁忙,都会固定地产生中断,从而造成不必要的功耗。
无滴答内核则取消了这种周期性的中断。它只在绝对必要的时候才进行重新调度。这些“必要时刻”被称为重调度点。任何可能导致就绪队列状态发生变化的操作,都会触发一个重调度点。例如:
一个线程调用
k_yield()主动让出 CPU。一个线程调用
k_sleep()进入休眠。一个正在等待信号量的线程,被另一个线程通过释放信号量而唤醒(其状态从未就绪变为就绪)。
一个正在等待数据的线程,接收到了它所需要的数据。
在时间切片模式下,一个线程用完了它的时间片。
数据传递
在理解了中断服务程序 (ISR) 和不同类型的线程如何构成一个 nRF Connect SDK 应用程序的逻辑构建块之后,接下来需要学习如何在这些块之间安全地交换数据。系统提供了多种数据传递机制,每种机制都有其特定的应用场景。本节将重点介绍两种最常用且能覆盖多种使用场景的机制:消息队列 (Message queue) 和 先入先出队列 (FIFO)。
消息队列 (Message Queue)
消息队列是一个线程安全 (thread-safe) 的数据容器,这意味着多个线程可以同时安全地访问它,而不会导致数据混乱。可以把它想象成一组固定大小、有编号的邮箱。
这个队列可以容纳预设数量的数据项(称为“消息”),这些消息可以是变量、结构体、指针或任何自定义的数据类型。队列能容纳的最大消息数量仅受系统可用内存的限制。
所有向队列中添加和移除数据的操作都由操作系统内核来负责,内核保证了这些操作的原子性和安全性。换言之,消息队列是一个内核对象 (kernel object),开发者无需担心其内部管理的复杂细节。
此外,消息队列还支持超时 (timeout) 机制。这个机制非常有用:
当一个线程尝试向一个已满的队列放入数据时,可以设置一个超时,让该线程进入休眠状态,直到队列中有空间可用。
当一个线程尝试从一个已空的队列获取数据时,可以设置一个超时,让该线程进入休眠状态,直到队列中有新的数据到来。
如果消息队列为空,可以有任意数量的接收线程同时等待。当一个新数据项被放入队列时,它会被交给等待的线程中优先级最高的那一个。同理,当消息队列已满时,这个规则也适用于等待发送的线程。
消息队列在内核内部是作为一个环形缓冲区 (ring buffer) 来实现的,其总容量(能存放多少个消息)和每个消息的大小都是在编译时静态定义的。消息的大小必须是数据对齐值的整数倍。如果数据大小不规则,可以通过填充数据或使用编译器属性(如 __aligned(4))来指定最小对齐。
虽然可以在中断服务程序中使用消息队列,但必须非常小心,确保不会触发长时间或阻塞的操作,并且绝对不能在中断中使用任何带超时的选项(例如 K_FOREVER)。
如何使用消息队列
确定消息的数据结构
这取决于具体的应用需求。需要注意的是,消息的数据类型是静态设置的,不能在运行时动态改变。可以将消息定义为一个简单的整数、一个字符串、一个结构体,或者在一个结构体内使用联合体 (union)。当不同类型的数据不会同时使用时,通过在结构体中使用联合体可以有效节省内存。
以下是一个在结构体中嵌套联合体的示例:
struct MyStruct {
int dataType; // 用来指明当前联合体中哪个数据是有效的
union {
int intValue;
float floatValue;
char stringValue[24];
} data;
};在这个例子中,可以根据 dataType 成员的值,来决定是访问 data.intValue,data.floatValue 还是 data.stringValue。
定义并初始化消息队列
可以使用宏 K_MSGQ_DEFINE() 一步完成定义和初始化。它需要四个参数:队列名称、单个消息的大小、队列能容纳的最大消息数量、以及内存对齐值。
下面的代码片段定义并初始化了一个名为 device_message_queue 的消息队列,它可以容纳 16 个消息,每个消息的大小是 4 字节 (uint32_t),对齐值为 4。
K_MSGQ_DEFINE(device_message_queue, sizeof(uint32_t), 16, 4);向消息队列写入一条消息
使用 k_msgq_put() 函数来写入消息。它需要三个参数:目标消息队列、一个指向待发送消息的指针、以及一个超时选项。超时选项决定了当队列已满时该如何处理:
K_FOREVER:发送线程将无限期地等待,直到队列中有可用空间(即有接收线程消费了一条消息)。K_MSEC(x):发送线程将等待指定的毫秒数。K_NO_WAIT:发送线程不等待,立即返回。这意味着如果队列已满,新的数据将不会被添加,直接被丢弃。
从消息队列读取一条消息
使用 k_msgq_get() 函数来读取消息。注意,调用此函数会将消息从队列中移除(这个操作也称为“弹出”消息)。这是推荐的使用方式,可以防止队列被填满。另一种方式是使用 k_msgq_peek() 函数,它只会读取消息,但不会将其从队列中移除。
无论哪种方式,消息都以先进先出 (First in, First out) 的方式被读取。k_msgq_get() 函数也需要三个参数:目标消息队列、一个指向本地变量的指针(用于存放读取到的消息)、以及一个超时选项,用于决定当队列为空时该如何处理。
建议用途:用于在线程之间异步地传递已知大小和数量的数据项。也可以谨慎地用于线程与中断之间的数据传递。
先入先出队列 (FIFO)
FIFO 也是一个内核对象,它提供了一个传统的先入先出 (First-In, First-Out) 队列结构。它允许线程和中断服务程序 (ISR) 向队列中添加或移除任意数量和不同大小的数据项。
与消息队列最大的不同在于,FIFO 更加灵活。在定义 FIFO 时,无需静态地指定其中能存放多少个数据项,也无需指定每个数据项的大小。作为代价,通常需要配合使用堆内存 (heap memory)(通过 k_malloc() 和 k_free())来动态地为数据项分配存储空间。FIFO 本身只保存这些数据项的地址(指针),因此 FIFO 中数据项的数量可以动态变化,其上限仅受堆内存大小的限制。
如何使用 FIFO
配置堆内存池的大小
这个值需要根据应用需求来设定。默认情况下,CONFIG_HEAP_MEM_POOL_SIZE 的值为 0。因此,必须在配置文件中将其设置为一个合适的值,以确保能容纳在任何给定时刻 FIFO 中可能存在的最大数据量。
# 在 prj.conf 文件中设置
CONFIG_HEAP_MEM_POOL_SIZE=4096注意:在嵌入式固件中使用堆和动态内存分配必须格外小心。开发者必须手动负责在数据使用完毕后,调用
k_free()将其占用的内存释放回堆中。如果忘记释放,就会导致内存泄漏 (memory leak),最终耗尽系统内存。
定义 FIFO
可以使用 K_FIFO_DEFINE() 宏来静态地定义一个 FIFO。
K_FIFO_DEFINE(my_fifo);与消息队列不同,定义时无需指定数据类型和大小。
定义数据项的类型
这里的关键点是,必须将数据项定义为一个结构体,并且该结构体的第一个成员必须是一个保留的 void 指针。
struct data_item_t {
void *fifo_reserved; // 这个成员专为 FIFO 内部使用,不能动
uint8_t data[256];
uint16_t len;
};这个指针是必需的,因为 FIFO 在内核内部是作为一个简单的单向链表 (linked list) 来实现的,这个成员就是用来存放指向下一个数据项的指针。
向 FIFO 添加一个数据项
使用 k_fifo_put() 函数添加数据项。通常的流程是:先从堆中分配内存,然后填充数据,最后放入 FIFO。
/* 创建要发送的数据项 */
struct data_item_t *buf = k_malloc(sizeof(struct data_item_t));
if (buf == NULL) {
/* 堆内存分配失败 */
return;
}
/* 填充数据项的内容,通常使用 memcpy() */
/* 将数据项放入 FIFO */
k_fifo_put(&my_fifo, buf);由于 FIFO 的容量只受堆内存限制,因此 k_fifo_put() 函数没有超时选项。必须谨慎设置堆的大小以满足应用需求。
从 FIFO 读取一个数据项
使用 k_fifo_get() 函数读取数据项。
/* 从 FIFO 获取一个数据项,如果为空则永久等待 */
struct data_item_t *rec_item = k_fifo_get(&my_fifo, K_FOREVER);
/* 处理接收到的数据... */
/* !!!处理完毕后,必须手动释放内存!!! */
k_free(rec_item);调用 k_fifo_get() 会将数据项从 FIFO 中移除。但是,它仅仅是移除了指针,并未释放指针所指向的内存。开发者必须在处理完数据后,手动调用 k_free() 来释放内存,否则将导致堆内存溢出。
建议用途:用于在线程之间异步地传递数量和大小都未知或可变的数据项。同样可以谨慎地用于与中断的交互。
重要提示
如果对在代码中使用动态内存分配有顾虑,也可以不将 FIFO 与堆内存配合使用,而是选择从一个静态分配的内存池中获取数据项的内存。此外,绝对不能将同一个数据项两次放入 FIFO,这会破坏 FIFO 内部的链表结构,导致未定义的行为。
总结
第一部分:核心思想:你的团队成员有几种工作方式?
你的团队里有不同类型的员工,他们处理任务的方式也不同。这对应文中的“执行原语”。
可抢占线程 (Preemptible thread) - 普通员工
是什么:这是你手下最常见的员工。他正在专心做报表(一个低优先级任务)。
特点:这时,老板(更高优先级的任务)突然走过来说:“停一下,先把这份紧急合同处理了!” 这位员工必须立刻放下手头的报表,去处理合同。合同处理完,他才能继续回来做报表。
“可抢占” 的意思就是:可以被打断。
协作式线程 (Cooperative thread) - 专注的技术专家
是什么:这位员工非常专注。他一旦开始调试一段代码,就会一直干下去,直到他自己觉得“OK,这个小阶段完成了,可以歇口气了”,他才会停下来。
特点:即使是同级别的同事找他,他也不会理会。他只会自己主动说“我好了,你们谁来?”。
“协作式” 的意思就是:不会被打断,除非自己愿意。
工作队列 (Work queue) - 任务清单和实习生
是什么:你有一堆零碎的小活儿:复印文件、订外卖、发邮件。你不想为每个小活儿都专门派一个正式员工(创建一个完整的线程开销很大)。
特点:于是你把这些小任务写在一张清单(工作队列)上,然后交给一个实习生(系统的工作线程)。实习生就按照清单一件一件地做。这样既完成了任务,又很省资源。
“工作队列” 的意思是:一个专门处理零碎任务的“任务池”。
第二部分:应用程序的启动流程:公司是如何开门营业的?
这就像一家新公司从装修到正式开业的全过程。
阶段一:早期启动 (拉电闸、通电)
目标:让大楼(芯片)通上电,让最基本的电路(处理器)能跑起来。
比喻:你作为开发者,基本不用管这个,这是物业电工(底层硬件)干的活。
阶段二:内核初始化 (装修和安装基础设施)
目标:在员工(线程)上班前,把办公室的基础设施装好。
PRE_KERNEL_1级(装最基础的):时钟控制:安装公司的总时钟,让所有部门时间同步。没这个,一切都乱套。
串口驱动:安装一个对讲机(串口),这样装修师傅(系统)可以喊话,告诉你“时钟装好了!”。
PRE_KERNEL_2级(装依赖性的):- 系统定时器:基于总时钟,给会议室装上一个精准的倒计时器。以后开会、定闹钟(线程休眠、定时任务)全靠它。
阶段三:多线程准备 (员工上班,公司开业)
目标:操作系统核心功能启动,准备迎接真正的业务。
POST_KERNEL级(管理层就位):调度器启动:公司的总监(调度器)上班了。他的工作就是决定现在该让哪个员工用唯一的会议室(CPU)。
创建系统线程:
主线程 (main thread):你的项目经理。他的最终任务就是去执行你写的项目计划书 (
main()函数)。空闲线程 (idle thread):保安。当所有员工都没事干的时候,保安(空闲线程)就开始巡逻,并把没人的办公室灯关掉(让芯片休眠省电)。
打印启动信息:公司门口的 LED 屏亮起,显示“*** 热烈庆祝本公司开业 ***”。
APPLICATION级(员工各就各位):启动用户线程:你手下的所有员工(你用
K_THREAD_DEFINE定义的线程)都到达工位,准备好随时听总监(调度器)的调遣。调用
main()函数:项目经理(主线程)打开你的项目计划书 (main()函数),项目正式开始!
第三部分:两种“执行环境”:线程 vs. 中断
你的员工总是在两种状态下工作:
线程上下文 (Thread context) - 日常办公状态
是什么:员工在自己工位上正常处理日常工作的状态。
特点:可以从容不迫地做复杂的工作(比如写一份策划案),中间可以去喝杯咖啡(
k_sleep()),可以等同事把文件传给你(等待资源),也可能会被老板叫去做更紧急的事(被抢占)。能做什么:几乎所有事。
中断上下文 (Interrupt context) - 火警警报状态
是什么:突然,整栋楼的火警响了(硬件中断)!
特点:不管你正在做什么,哪怕是跟客户通电话,都必须立刻挂掉,马上执行火警预案(中断服务程序 ISR)。
能做什么(非常有限):你只能做最关键、最快的事,比如按下最近的警报器、拿起灭火器。你绝对不能说“等我先泡杯茶再走”(不能阻塞/等待),因为这会耽误所有人的逃生时间,导致系统瘫痪。
核心区别:中断 > 一切。它会打断一切正常工作,且自身必须“快进快出”,不能有任何等待。
| 特性 | 线程上下文 (日常办公) | 中断上下文 (火警警报) |
|---|---|---|
| 触发方式 | 计划内的,由总监(调度器)安排 | 突发的,由外部事件(硬件)触发 |
| 执行时长 | 可以很长,做复杂任务 | 必须极短,只做最关键的事 |
| 能否等待 | 可以 (k_sleep, 等待锁) | 绝对禁止 |
| 优先级 | 被中断打断 | 打断所有线程 |
第四部分:线程和调度器:管理任务的艺术
线程的组成:一个员工 = 身份证 (
k_thread) + 自己的笔记本 (Stack) + 工作内容 (Entry point function) + 职级 (Priority)。线程的生命周期:
就绪 (Ready):员工在工位上,随时待命。
运行 (Running):被总监选中,正在使用会议室(CPU)。
非就绪 (Not Ready):
休眠 (Sleeping):主动去茶水间休息一下。
等待 (Waiting):在等打印机空出来。
终止 (Termination):任务完成,下班回家了。
调度器 (Scheduler):就是那个总监。他的规则很简单:
职位高(优先级数值小)的先干活。
如果职位一样高,就看谁先来排队。
他不讲公平,只要老板(高优先级线程)在,普通员工就永远别想用会议室。
上下文切换 (Context Switch):
比喻:会议室(CPU)只有一个,但有很多员工要用。员工 A 正在用白板写方案,突然被总监叫停,让给老板用。为了不让老板擦掉 A 的内容,秘书会拍一张高清照片(保存上下文),把白板上的所有内容都记下来。等老板用完,秘书再照着照片把白板恢复原样(恢复上下文),A 就可以继续写了。
代价:拍照和恢复都需要时间,所以频繁切换会降低效率。
第五部分:数据传递:线程间的“快递服务”
你的不同员工(线程)之间需要交换文件(数据)。有两种主流的快递服务:
消息队列 (Message Queue) - 公司内部邮局
比喻:公司有个内部邮局,里面有一排排固定大小的格子。你要寄一份文件,邮局工作人员会复印一份,然后放进收件人的格子里。收件人来取件时,拿到的是一份复印件。
特点:
安全省心:邮局(内核)帮你完成了所有复制和投递工作,你不用担心文件丢失或被别人拿错。
大小固定:格子的尺寸是事先定好的,太大的文件塞不进去。
内存管理:自动。你给的是原件,邮局帮你复印,你不用管复印件的纸张消耗。
何时使用:当你要传递的数据大小和格式都固定时,这是最简单、最安全的选择。
先入先出队列 (FIFO) - 共享信息板
比喻:办公室里有一块共享的信息板。你要传递一个大包裹(比如一个模型),你自己先找个储物柜(
k_malloc从堆内存分配空间)把包裹放进去,然后在信息板上写下“模型在 A-03 柜”(k_fifo_put放入指针)。收件人看到信息板上的通知(k_fifo_get获取指针),自己去 A-03 柜取出模型。特点:
灵活强大:可以传递任意大小的东西,因为你传递的只是“位置信息”(指针)。
需要手动管理:收件人用完模型后,必须亲自把储物柜清空并把钥匙还回去(
k_free释放内存)。风险:如果用完后忘记归还钥匙(忘记
k_free),储物柜就会被一直占用,最终所有储物柜都会被占满,公司就没地方放新东西了(内存泄漏)。
何时使用:当你要传递的数据大小不一或数量不定时,FIFO 提供了更大的灵活性,但代价是需要你承担内存管理的责任。
| 特性 | 消息队列 (内部邮局) | FIFO (共享信息板) |
|---|---|---|
| 传递内容 | 数据的复印件 | 数据的地址(指针) |
| 数据大小 | 固定 | 可变 |
| 内存管理 | 自动 (内核负责) | 手动 (开发者负责 malloc/free) |
| 使用复杂度 | 简单 | 复杂,有内存泄漏风险 |
实操
打开 VS Code,然后按照下图所示打开 nRF Connect 终端。
必须使用 nRF Connect 终端,因为这是已加载构建工具链(如 west)的环境。如果使用其他终端,会出现"命令无法识别"的错误提示。
在 nRF Connect 终端中输入命令 west manifest --path。将鼠标悬停在打印出的文件路径上,按住 Ctrl 键并左键单击即可打开该文件。
在您选择的 SDK 版本的 west.yml 文件中添加以下内容来包含该仓库。将以下信息添加到 # Other third-party repositories 部分的末尾。请确保保存文件的新更改。
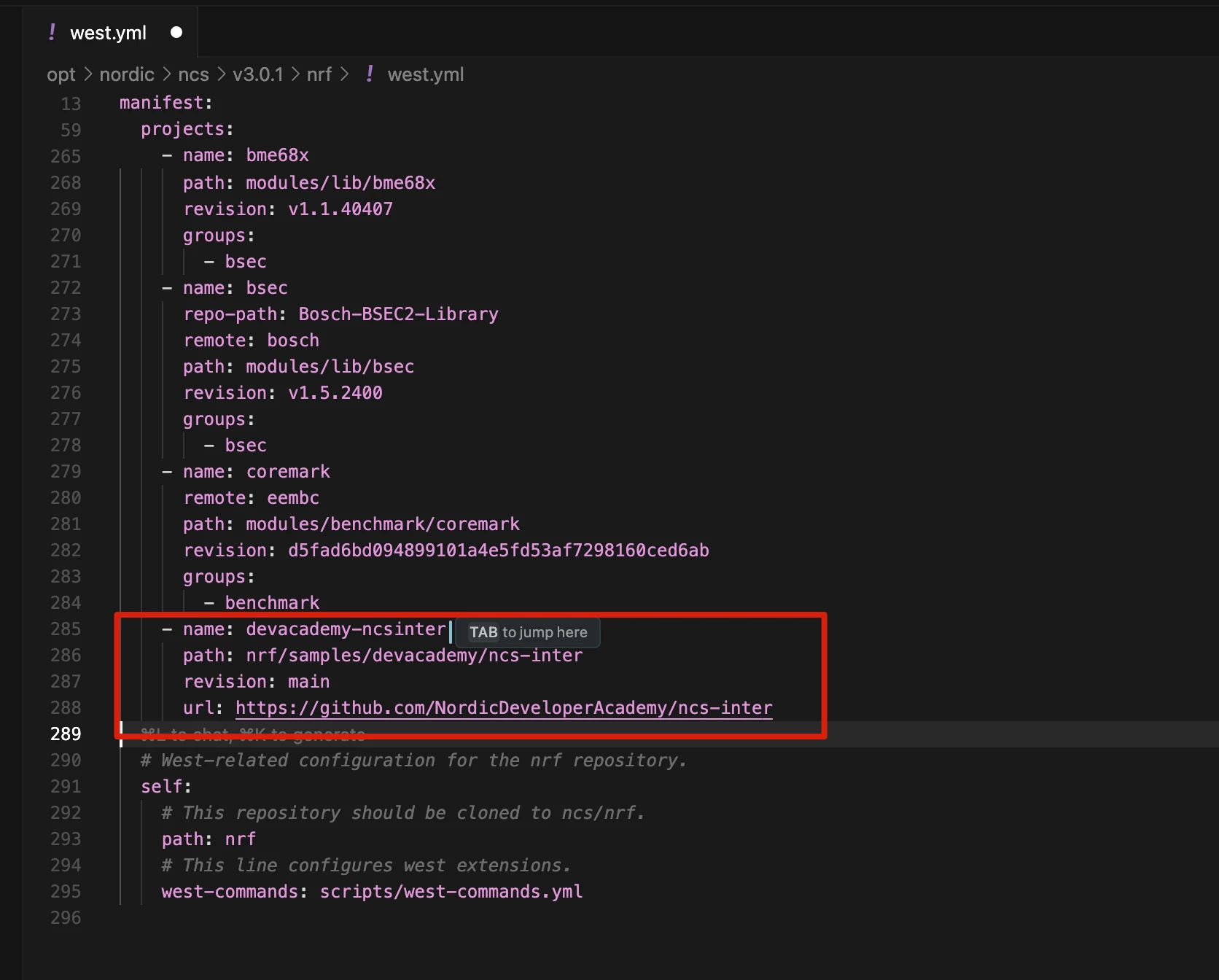
- name: devacademy-ncsinter
path: nrf/samples/devacademy/ncs-inter
revision: main
url: https://github.com/NordicDeveloperAcademy/ncs-inter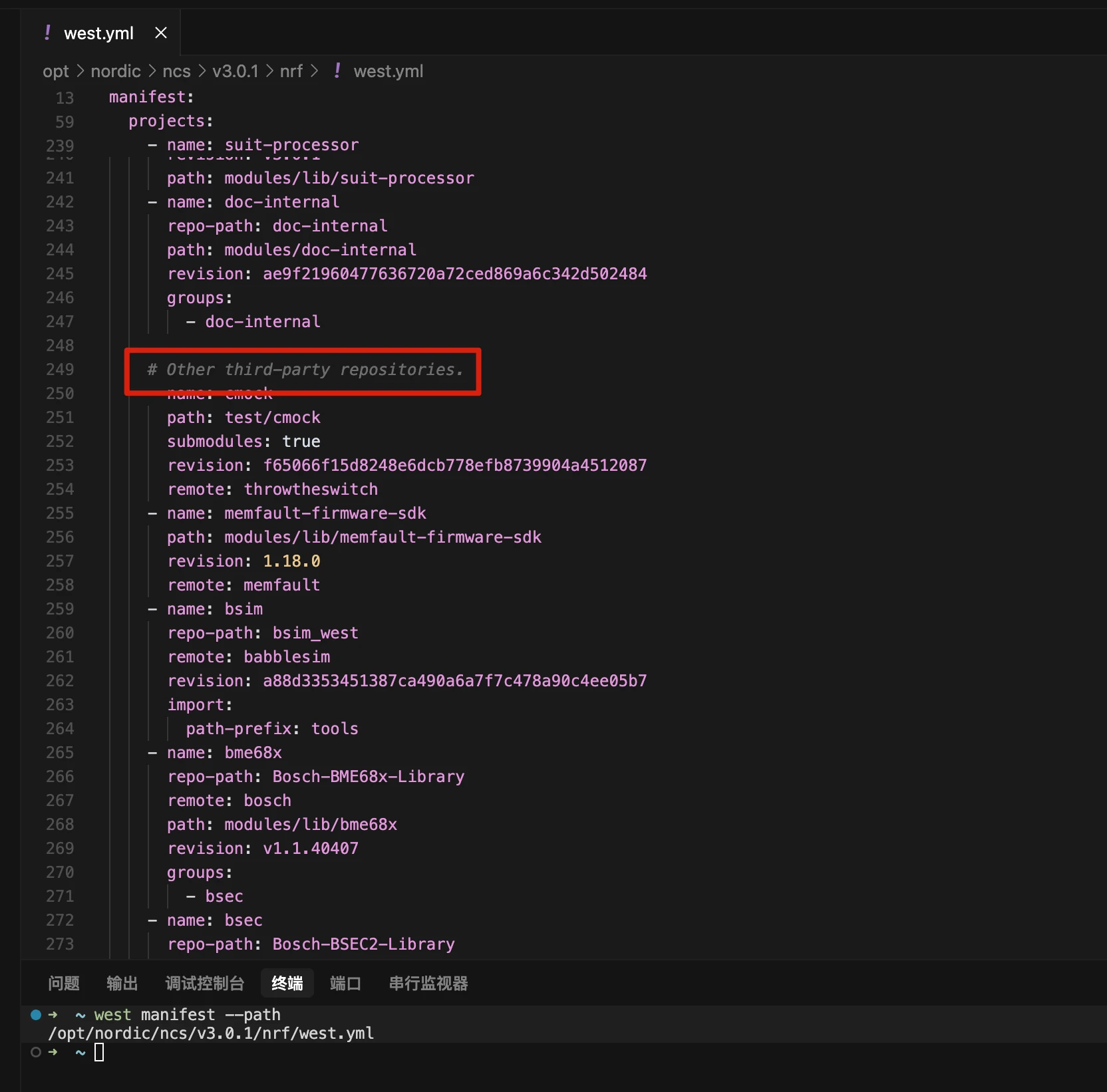
简单来说,
west.yaml文件是 nRF Connect SDK / Zephyr 项目的“蓝图”或“组件清单”。它告诉west工具(Zephyr 的元构建工具)这个项目由哪些软件仓库(Git Repositories)组成,以及每个仓库应该使用哪个确切的版本。
它的核心作用可以概括为以下几点:
1. 依赖管理 (Dependency Management)
2. 精确的版本控制 (Precise Version Control)
3. 可复现的开发环境 (Reproducible Development Environment)
输入 west update -x devacademy-ncsinter 获取课程代码库。
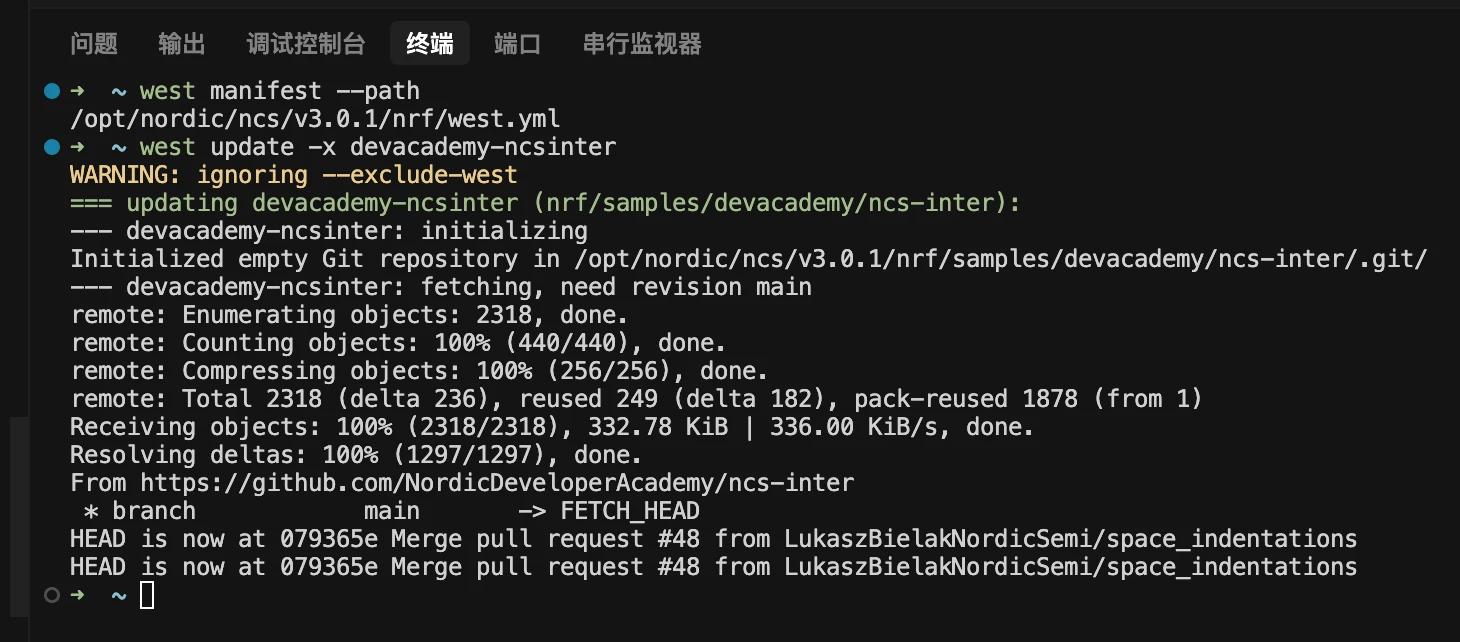
这样,课程练习(基础代码和解决方案)就存储在您本地的 <install_path>\nrf\samples\devacademy\ncs-inter 目录中,nRF Connect for VS Code 能够识别它们,因为它们包含正确的元数据文件 (sample.yaml)。
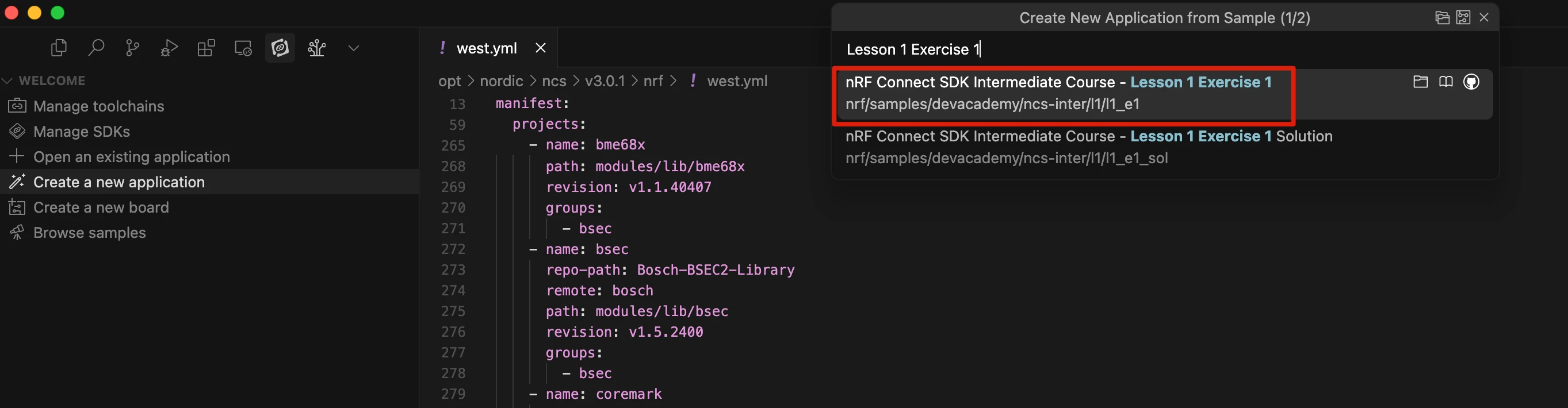
导航至 nRF Connect for VS Code 扩展,选择创建新应用 ,然后选择复制示例选项,如下图所示。
如果已安装多个版本,请选择你计划使用的 SDK 版本。
在从示例创建新应用窗口中,输入练习名称。本练习的名称为Lesson 1 – Exercise 1。请确保选择的是代码库(而非解决方案)如下图所示。
在本练习中,您将开发一个包含五个线程(生产者、消费者、主线程、日志记录、空闲)的应用程序,以及一个在中断上下文中每 500 毫秒周期性运行的函数(定时器)。该定时器将执行一个简单的任务:依次切换 LED0 和 LED1。
1. 创建一个定时中断:
设置一个定时器,每 500 毫秒触发一次。
每次触发时,让 LED0 和 LED1 轮流亮灭。
2. 编写 main 函数:
在
main函数里,完成两项准备工作:初始化 LED 灯的引脚。
启动上面那个 500 毫秒的定时器。
做完这两件事后,
main函数就直接结束返回。
3. 创建一个“生产者”线程:
优先级设置为 6。
每隔 2.2 秒运行一次。
每次运行时,生成一组假的传感器数据(x, y, z)。
把这组数据放进一个“消息队列”里。
4. 创建一个“消费者”线程:
优先级设置为 7(比生产者低)。
平时一直休眠,直到“消息队列”里有数据。
一旦有数据,它就醒来,从队列里取出数据。
然后,把取出的数据交给日志系统去打印。
5. 利用系统自带的线程:
日志线程:会自动接收消费者发来的数据,并通过串口(UART)打印到你的电脑上。
空闲线程:当你的生产者和消费者线程都在休眠时,这个线程会自动运行,让系统进入省电模式。
总结起来就是:一个定时器负责闪灯,一个线程负责定时生产数据并放入队列,另一个线程负责从队列里取出数据并打印,系统在没事干的时候自动省电。
#include <zephyr/kernel.h>
#include <zephyr/drivers/gpio.h>
#include <zephyr/logging/log.h>
/* The devicetree node identifier for the "led0" and "led1" alias. */
#define LED0_NODE DT_ALIAS(led0)
#define LED1_NODE DT_ALIAS(led1)
/* 2200 msec = 2.2 sec */
#define PRODUCER_SLEEP_TIME_MS 2200
LOG_MODULE_REGISTER(Less1_Exer1, LOG_LEVEL_DBG);
/* Stack size for both the producer and consumer threads */
#define STACKSIZE 2048
#define PRODUCER_THREAD_PRIORITY 6
#define CONSUMER_THREAD_PRIORITY 7
static const struct gpio_dt_spec led0 = GPIO_DT_SPEC_GET(LED0_NODE, gpios);
static const struct gpio_dt_spec led1 = GPIO_DT_SPEC_GET(LED1_NODE, gpios);
/* STEP 2.3 - Create the expiry function for the timer */
static void timer0_handler(struct k_timer *dummy)
{
/*Interrupt Context - System Timer ISR */
static bool flip= true;
if (flip)
gpio_pin_toggle_dt(&led0);
else
gpio_pin_toggle_dt(&led1); flip = !flip;
}
/* STEP 2.1 - Define the timer */
K_TIMER_DEFINE(timer0, timer0_handler, NULL);
/* STEP 3.1 - Define the data type of the message */
typedef struct {
uint32_t x_reading;
uint32_t y_reading;
uint32_t z_reading;
} SensorReading;
/* STEP 3.2 - Define the message queue */
K_MSGQ_DEFINE(device_message_queue, sizeof(SensorReading), 16, 4);
int main(void)
{
/* start periodic timer that expires once every 0.5 second */
k_timer_start(&timer0, K_MSEC(500), K_MSEC(500));
int ret;
if (!gpio_is_ready_dt(&led0)) {
return 0;
}
ret = gpio_pin_configure_dt(&led0, GPIO_OUTPUT_ACTIVE);
if (ret < 0) {
return 0;
}
ret = gpio_pin_configure_dt(&led1, GPIO_OUTPUT_ACTIVE);
if (ret < 0) {
return 0;
}
/* STEP 2.2 - Start the timer */
return 0;
}
static void producer_func(void *unused1, void *unused2, void *unused3)
{
ARG_UNUSED(unused1);
ARG_UNUSED(unused2);
ARG_UNUSED(unused3);
while (1) {
static SensorReading acc_val = {100, 100, 100};
int ret;
/* STEP 3.3 - Write messages to the message queue */
ret = k_msgq_put(&device_message_queue,&acc_val,K_FOREVER);
if (ret){
LOG_ERR("Return value from k_msgq_put = %d",ret);
}
acc_val.x_reading += 1;
acc_val.y_reading += 1;
acc_val.z_reading += 1;
k_msleep(PRODUCER_SLEEP_TIME_MS);
}
}
static void consumer_func(void *unused1, void *unused2, void *unused3)
{
ARG_UNUSED(unused1);
ARG_UNUSED(unused2);
ARG_UNUSED(unused3);
while (1) {
SensorReading temp;
int ret;
/* STEP 3.4 - Read messages from the message queue */
LOG_INF("Values got from the queue: %d.%d.%d\r\n", temp.x_reading, temp.y_reading,
temp.z_reading);
}
}
K_THREAD_DEFINE(producer, STACKSIZE, producer_func, NULL, NULL, NULL, PRODUCER_THREAD_PRIORITY, 0,
0);
K_THREAD_DEFINE(consumer, STACKSIZE, consumer_func, NULL, NULL, NULL, CONSUMER_THREAD_PRIORITY, 0,
0);在"操作"视图中点击"调试"按钮
这将为您的开发板刷入固件并启动调试会话。默认情况下,执行会在 main() 处中断。
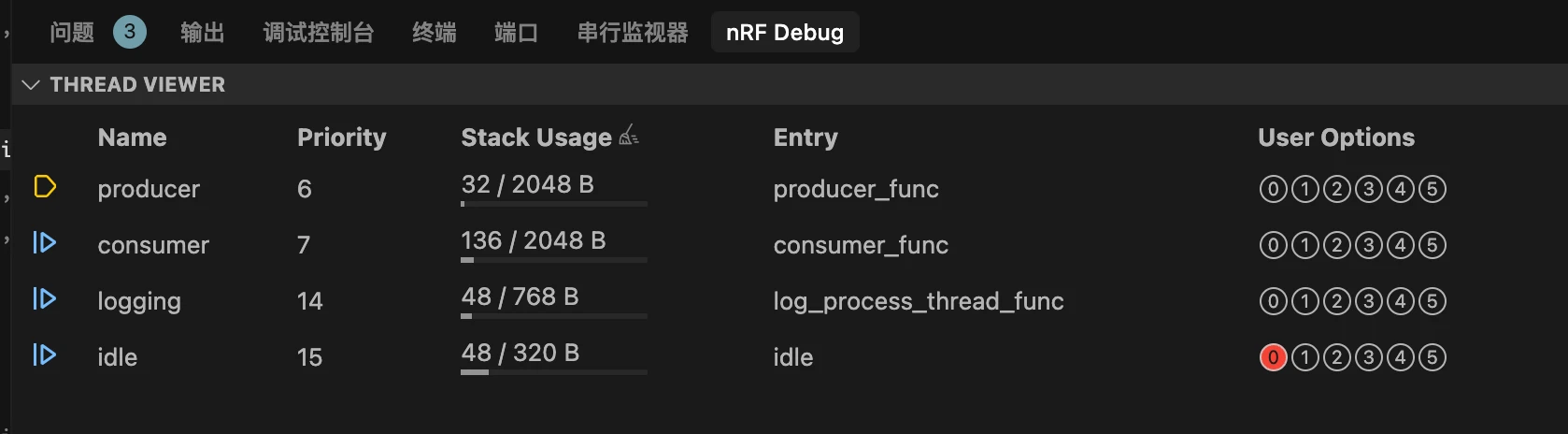
点击面板视图区域中的 nRF 调试以查看线程查看器 。
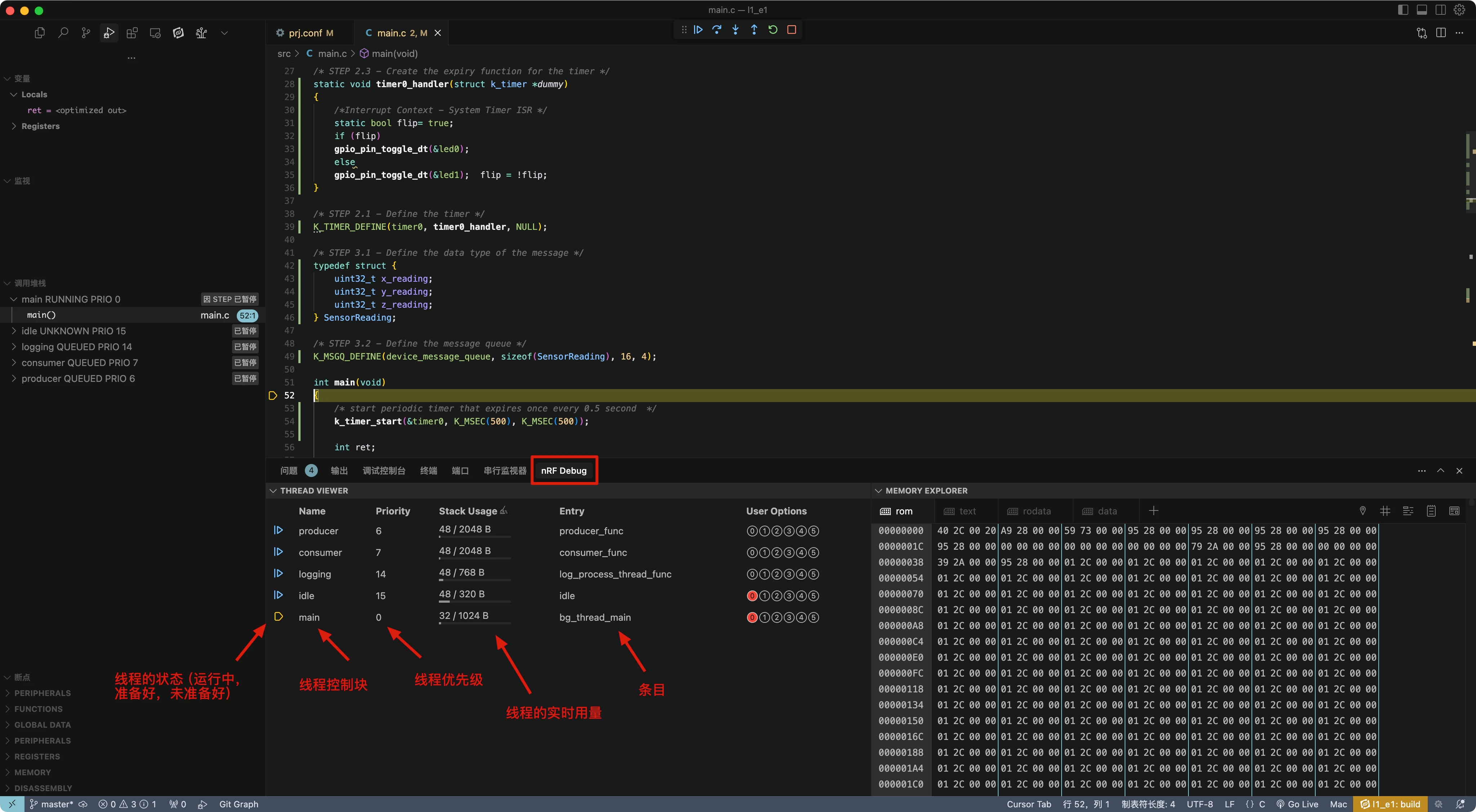
使用线程查看器,您可以获取应用程序中所有线程的关键信息,包括:
nRF Connect SDK 应用程序中的线程数量
每个线程的优先级
任意时刻每个线程的状态
每个线程分配的堆栈和实时堆栈使用情况。这对优化堆栈使用和定位可能的溢出问题非常有用
线程控制块
与每个线程关联的入口函数
每个线程的线程选项
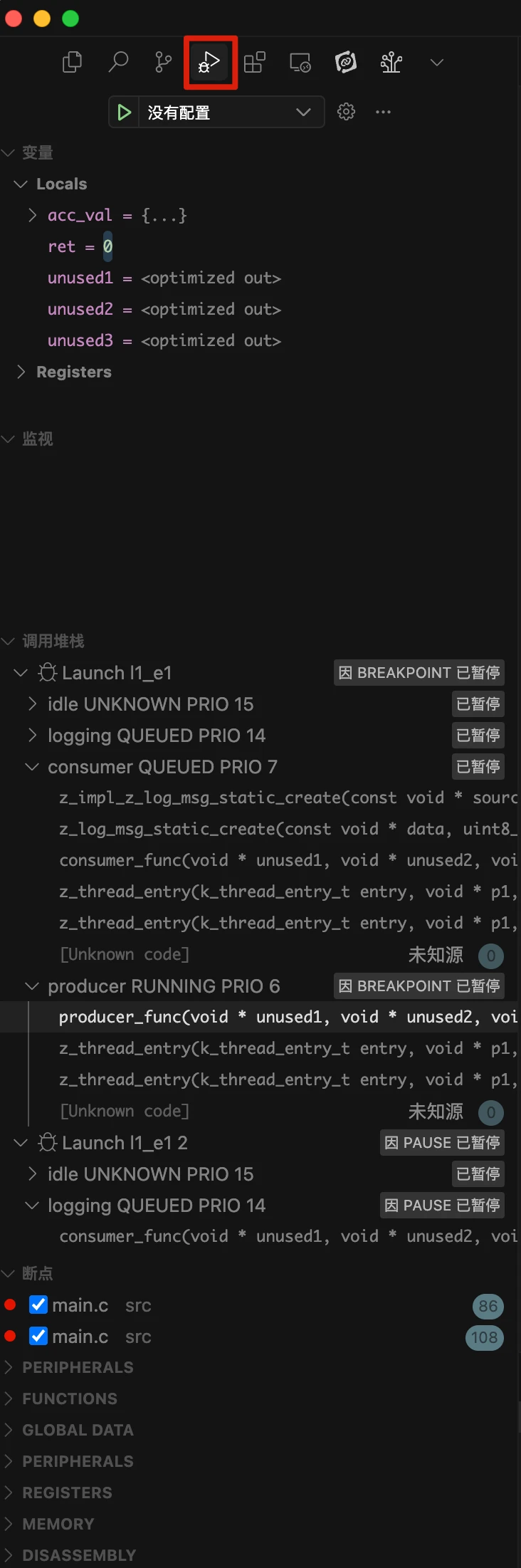
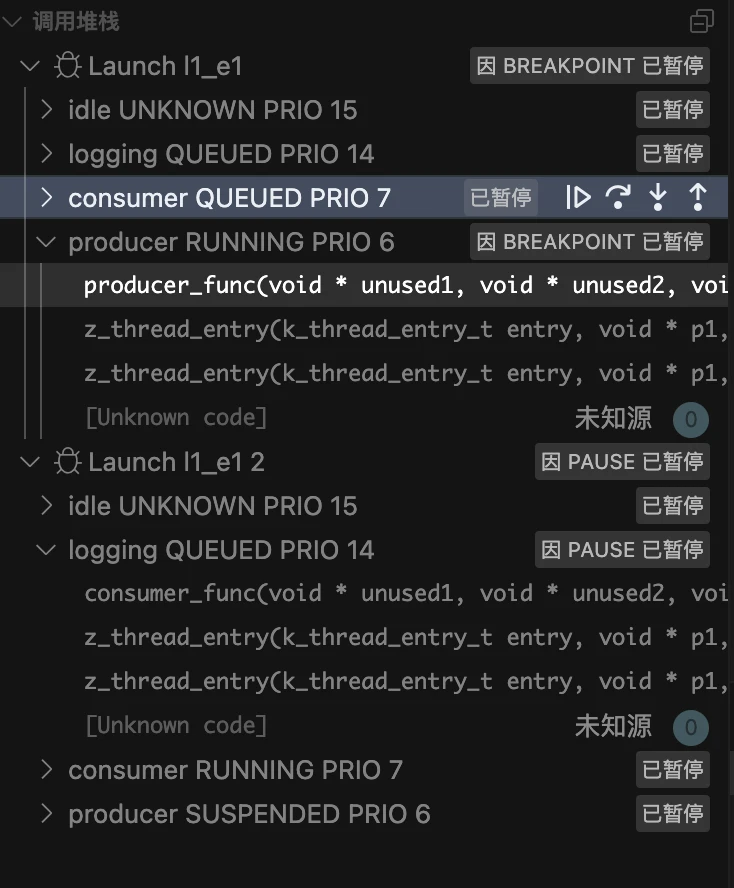
如上图截图所示,该应用程序有五个线程(主线程、生产者、消费者、日志记录、空闲),优先级分别为0、6、7、14和15。当前运行的线程是主线程,由黄色箭头符号指示。分配给每个线程的堆栈显示在线程查看器中,您还可以点击"启用跟踪(Enable Tracking)"按钮实时显示堆栈指针的堆栈使用情况以及最大堆栈使用量。
线程查看器中的所有条目均可点击。例如,点击线程条目会跳转到该函数的定义代码处,线程控制块同样适用此操作。
在生产者线程中的 k_msgq_put() 调用后设置一个断点,在消费者线程中的 k_msgq_get()调用后设置另一个断点。通过点击行号旁边的列来设置断点,如下图所示。
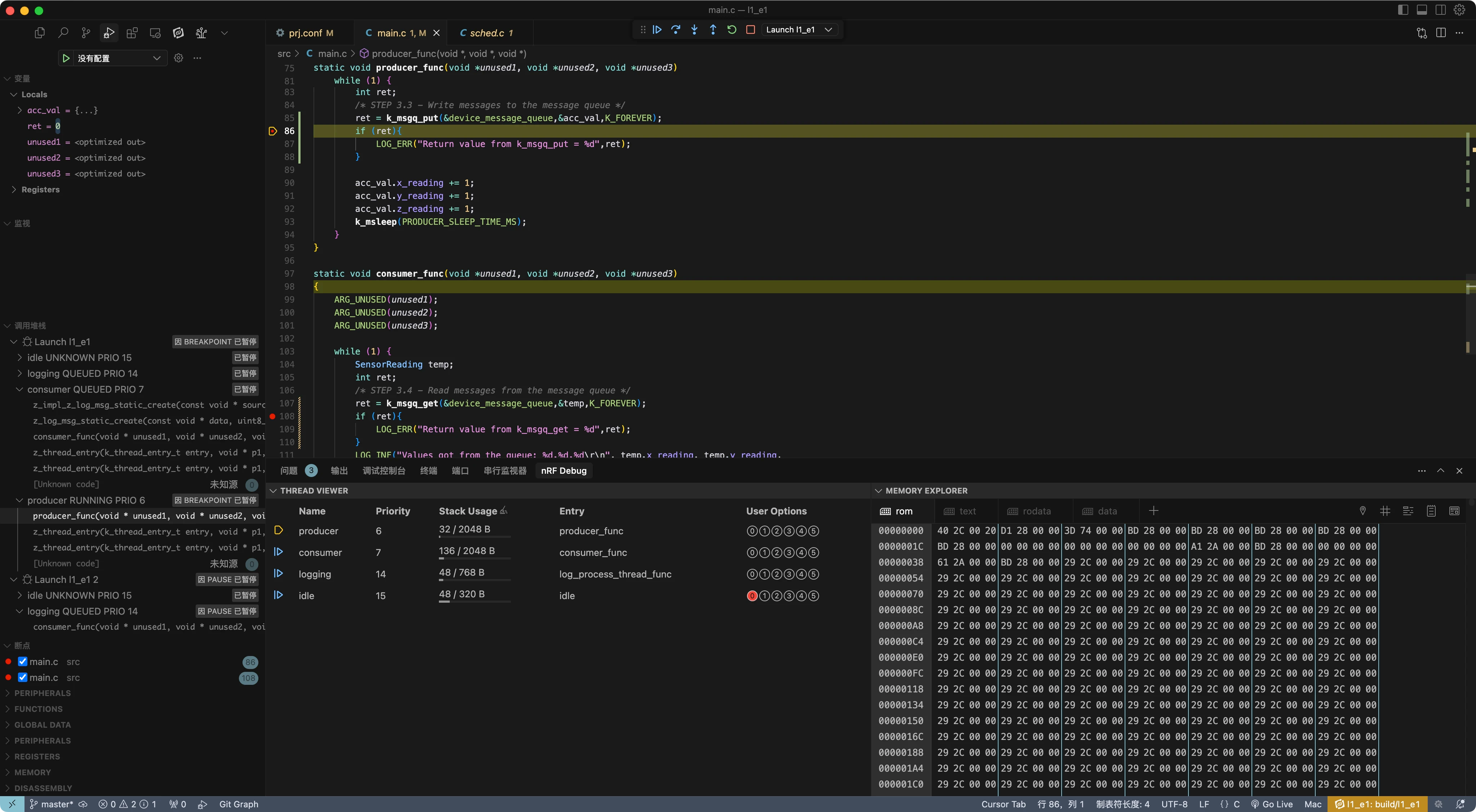
生产者线程中的断点会首先被触发,因为主线程结束后生产者线程会立即运行。这是由于当主线程终止时,生产者线程在就绪队列中具有最高优先级。
在"线程视图"中首先需要注意的是,主线程已因正常退出而终止不复存在。如黄色箭头所示,生产者线程现在是正在运行的线程。
调试与故障排除
能够快速高效地调试应用程序是每位开发者都应掌握的实用技能。本课程将介绍使用 nRF Connect SDK 开发应用程序时的一些实用调试技巧。首先我们会详细讲解 nRF Connect for VS Code 中可用的调试功能,分析构建错误和致命错误,并演示如何使用 core dump 和 addr2line 等工具进行调试。接着我们将探讨如何排查设备树问题,并简要介绍物理调试方法。
在 nRF Connect for VS Code 中进行调试
调试,在嵌入式开发领域,指的是识别、分析并解决软硬件问题的过程。这是一个反复迭代的过程,开发者通过分析代码或硬件,做出微小调整,然后再次测试应用程序。开发过程中遇到的常见问题包括语法错误、逻辑错误、内存泄漏、时序问题以及硬件相关问题。
nRF Connect SDK 提供了多种工具来辅助应用程序的调试。本节将介绍其中一些最实用的调试工具及其使用方法。
调试前的准备工作
为了能够顺利地调试 nRF Connect SDK 应用程序,在构建(编译)之前,必须对应用程序进行正确的配置。
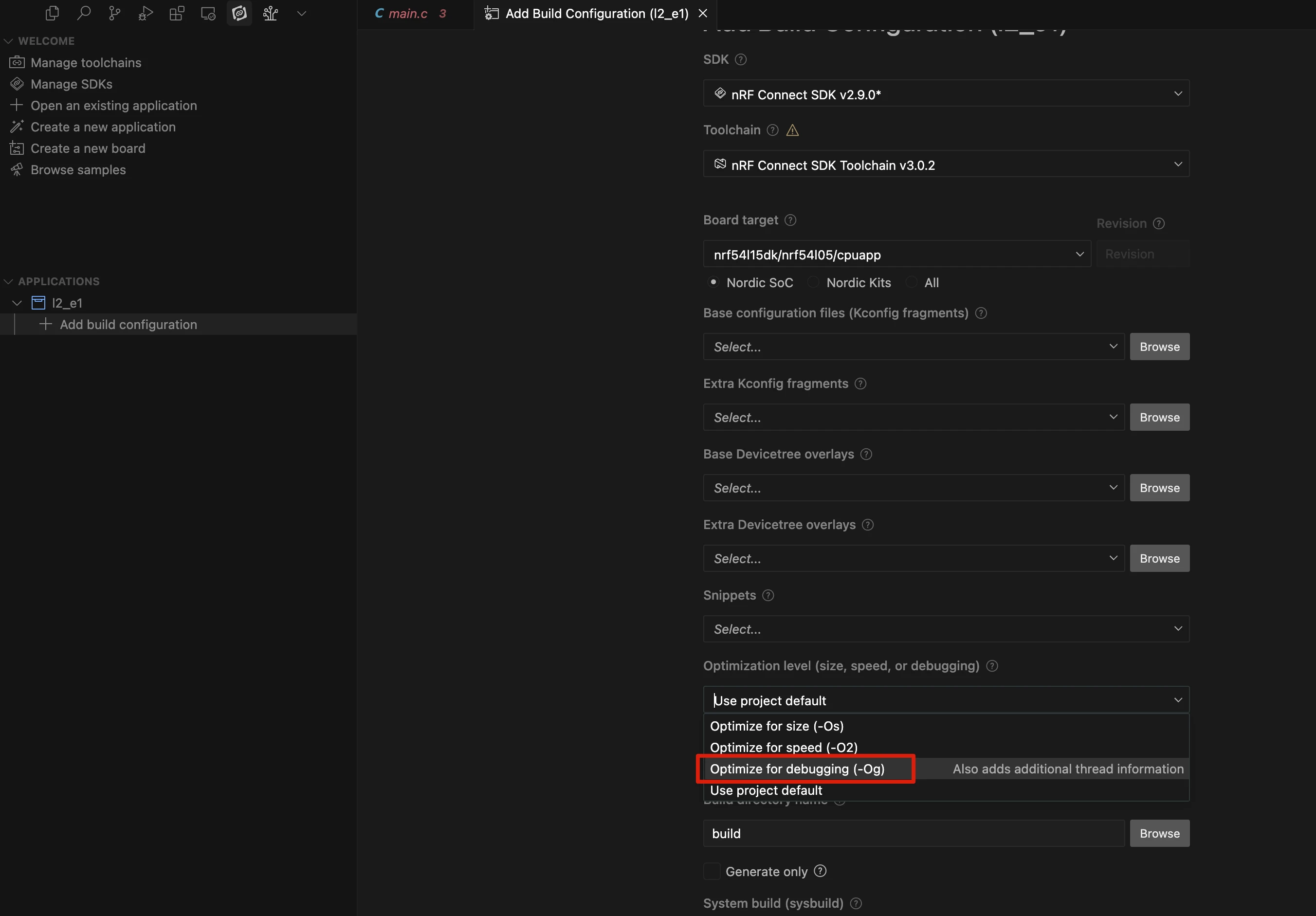
在构建配置菜单的“优化级别 (Optimization level)”中,选择 “为调试而优化 (Optimize for debugging)”。这个选项会在固件中加入额外的调试信息,使得构建完成后能够使用 VS Code 插件提供的增强调试功能。
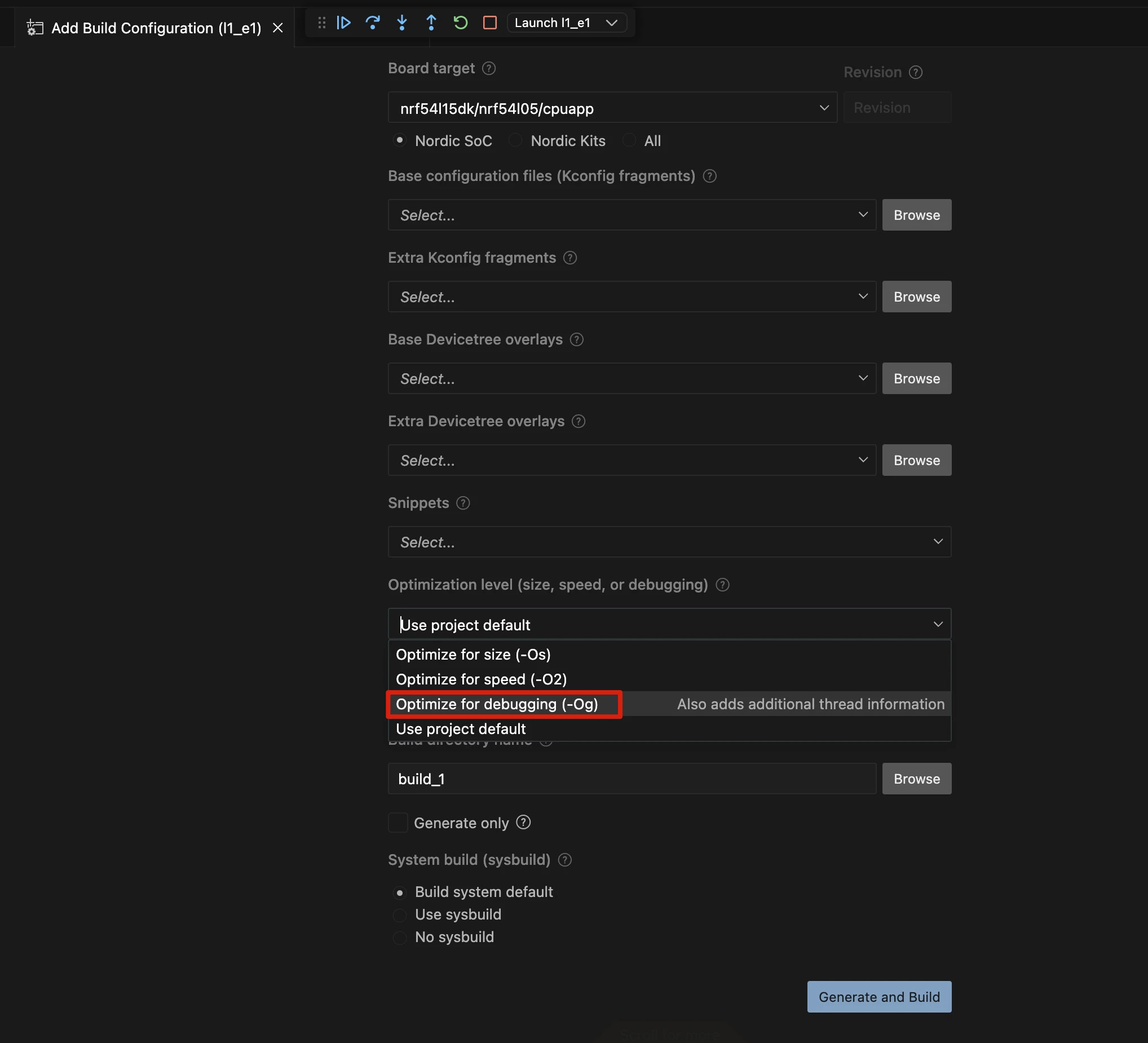
当设置此优化级别后,构建系统会自动启用以下 Kconfig 选项:
CONFIG_DEBUG_OPTIMIZATIONS:它的作用是限制编译器的优化程度,只保留那些不影响调试的优化。这可以防止代码因为过度优化而变得难以追踪,例如函数被内联或变量被优化掉。CONFIG_DEBUG_THREAD_INFO:为线程对象添加额外信息,以便调试器能够发现并识别出系统中的所有线程,这对于调试多线程程序至关重要。
其他一些在调试时非常有用的 Kconfig 选项:
CONFIG_I2C_DUMP_MESSAGES:启用后,可以打印出所有的 I2C 通信消息,便于调试 I2C 问题。CONFIG_ASSERT:它会在内核代码中启用__ASSERT()宏。当断言失败时(即程序运行到了一个理论上不应该出现的状态),系统会根据assert_post_action()函数的实现来采取行动,默认情况下是触发一个致命错误,使系统停机。
需要注意的是,启用调试优化会增加最终生成代码的体积。如果这导致了问题(例如固件超出了 Flash 大小),可以考虑仅手动启用必要的选项,例如 CONFIG_THREAD_NAME 或 CONFIG_DEBUG。
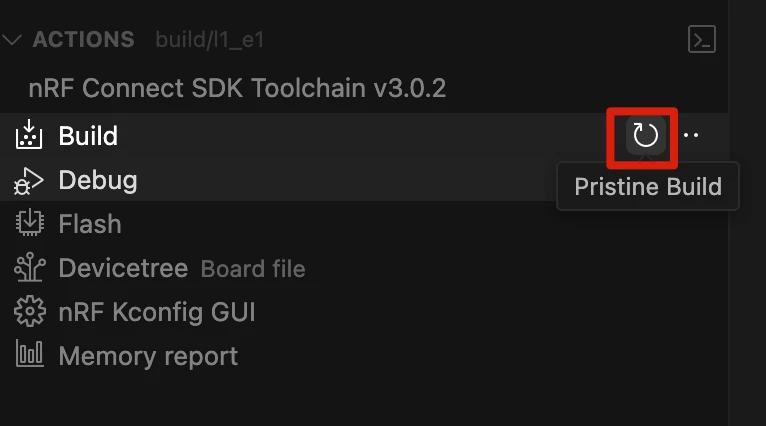
纯净构建 (Pristine Build)
构建系统在生成输出文件时,并不总是会在其输入文件发生变化时重新生成所有内容。有时,即使修改了配置文件,旧的设置可能仍然残留在构建目录中。作为排查编译问题的第一步,推荐手动删除旧的 build 文件夹,然后执行一次“纯净构建 (Pristine Build)”,以确保所有配置都能正确生效。
断点 (Breakpoints)
断点是代码中的一个标记位置。当程序执行到这个位置时,会暂停运行。这让开发者有机会检查程序在那个特定时刻的状态,例如查看变量的值或分析函数调用堆栈。
在 VS Code 中,除了常规断点,还可以设置条件断点 (conditional breakpoints),即只有当满足特定表达式时,断点才会触发。另一种有用的类型是日志点 (Logpoint),它不会暂停程序,而是在到达该行时打印一条日志信息到调试控制台,这是一种无需修改代码就能添加临时打印语句的便捷方法。
监控模式调试 (Monitor mode debugging)
调试器通常有两种工作模式:暂停模式 (halt mode) 和 监控模式 (monitor mode)。
暂停模式:是默认模式。当触发调试请求(如遇到断点)时,调试器会完全暂停 CPU 的运行。
监控模式:在这种模式下,调试器允许 CPU 在处理调试任务的同时,继续运行一些关键的核心功能。
对于像低功耗蓝牙或 PWM 这样对时间要求严格的应用,完全暂停 CPU 会破坏其正常的时序,导致功能异常或连接中断。监控模式正是为了解决这个问题而设计的。它通过让 CPU 进入一个特殊的调试中断来与调试器通信,而不是完全停机。
要启用监控模式,需要:
在
prj.conf文件中启用CONFIG_CORTEX_M_DEBUG_MONITOR_HOOK和CONFIG_SEGGER_DEBUGMON。在调试控制台中输入命令
-exec monitor exec SetMonModeDebug=1来启用调试器的监控模式。
调试器视图
VS Code 的 nRF Connect 插件提供了一系列强大的视图窗口,用于深入洞察程序的运行状态。
变量视图 (Variables View)
此视图显示当前作用域内的变量,并自动将其分为局部变量 (Local)、全局变量 (Global) 和静态变量 (Static)。变量的值只有在程序暂停时才会更新。
监视视图 (Watch View)
此视图用于持续追踪您特别选定的变量的值。您可以将代码中的任何变量或表达式添加到监视视图中,以便在每次程序暂停时都能方便地查看它们的变化。
外设视图 (Peripherals View)
当调试开始时,此视图会根据设备的 SVD (System View Description) 文件,以图形化的方式显示所有硬件外设的寄存器及其当前值。这对于监控和排查硬件相关的行为(例如检查某个 GPIO 的配置是否正确)极为有用。
调用堆栈 (Call Stack)
调用堆栈列出了应用程序中所有可用的线程,并指明了哪个线程当前正在运行。它还显示了每个线程的函数调用链,即为了到达当前执行点,函数之间是如何逐层调用的。调用堆栈是一种后进先出 (LIFO) 的数据结构,用于追踪函数之间的调用关系。
线程查看器 (Thread Viewer)
对于实时操作系统 (RTOS) 的开发,这是一个至关重要的视图。它专门用于显示应用程序中所有线程的详细信息,包括:
Name (名称):线程的名称。
Priority (优先级):线程的优先级。
Entry (入口点):线程的入口函数名。
Stack Usage (栈使用情况):显示线程已使用的栈字节数和总共分配的栈大小。
User Option (用户选项):与线程关联的二进制选项值。
此视图中的信息只有在调试器暂停时才会更新。
内存浏览器 (Memory Explorer)
此视图用于查看和分析设备上不同内存区域(如 Flash、RAM)的原始二进制内容。您可以用它来检查内存中的特定数据,或查看代码段的文本表示。
构建错误与致命错误
在嵌入式系统开发过程中,会在不同阶段遇到各种问题:构建应用程序时、测试时或运行期间。本文介绍了这些问题的故障排除方法,首先讲解构建错误,然后介绍应用程序运行时的致命错误。
构建错误处理
构建日志是排查构建问题的主要工具,可以通过按下 Ctrl+` 或者依次点击 View --> Terminal 来显示终端查看构建日志。需要注意的是,构建日志并不是存储在一个完整的文件中,而是分散在多个文件里:
|-Application Folder
|- Build Folder
|- CmakeFiles
|-CmakeError.log
|-CmakeOutput.log
|-Build.ninja
|-.ninja.build由于构建日志输出内容很长,建议从日志中的第一个错误开始查看,然后依次处理后续错误。值得注意的是,修复一个错误可能会导致出现多个新的错误,这是正常现象。
故障排除流程
第一步是寻找错误信息。在构建日志中查找以"error"或"warning"开头的行,这些行标识了需要关注的问题。错误比警告更关键,通常会阻止项目的成功编译。
第二步是仔细阅读错误信息。错误信息包含了出错的内容、位置,有时还会提供修复建议。找到出错的代码行后,需要打开相应位置的代码。
第三步是识别错误原因。编译过程中可能出现的错误原因包括:
代码问题是最常见的,比如语法错误或未定义变量。可以查阅 errno.h 文件来理解运行时函数返回的系统错误代码。常见的代码错误包括忘记分号、未定义变量、括号未闭合等。
配置问题涉及项目配置错误,比如 prj.conf 或设备树配置文件中的设置缺失或不正确。
缺少依赖关系意味着 Zephyr 无法找到引用的库或组件。
组件不兼容则是由于不兼容的组件或配置选项冲突导致的错误。
如果是 sysbuild 应用程序,需要检查两个镜像的 prj.conf 和设备树配置。
第四步是修复错误。根据错误性质,可能需要重新配置或重写项目。可以利用 DevZone、nRF Connect SDK 文档、Zephyr 项目文档和 Stack Overflow 等资源来找到正确的修复方法。
第五步是重新构建并重复以上过程。修复问题后,重新构建项目并检查构建日志输出。软件错误修复是一个迭代过程,修复一个错误可能会暴露其他错误。
致命错误处理
致命错误是指 Zephyr 内核被认为无法恢复的错误状态。当这种情况在运行时发生时,很难找出问题所在,因为可能难以重现。幸运的是,有一些工具可以帮助处理设备遇到致命错误的情况。
Addr2line 工具
Addr2line 是一个命令行工具,通过可执行文件中的地址和对应的调试信息来确定与该地址相关联的文件名和行号。这可以用来确定致命错误发生的位置。该工具是 GCC 包的一部分,随 nRF Connect SDK 一起安装。
使用这个工具需要提供两个信息:一个或多个要转换的地址,以及包含这些地址符号的二进制文件。
当应用程序遇到致命错误时,日志输出会打印出错指令地址,这就是要转换的地址。
要使用的二进制文件是 zephyr.elf 文件,位于已构建应用程序的 build/zephyr/zephyr.elf 路径下,它包含应用程序和内核库。
.elf(可执行可链接格式)文件包含元数据、符号信息、调试信息、内存分段、节和数据。内核可以将 .elf 文件加载到任何内存地址,并将符号调整为从内存地址的偏移量。相比之下,.hex 文件是二进制数据的文本表示,包含校验和地址,可以是稀疏的,意味着可以跳过未使用的内存位置。因此 .elf 文件比 .hex 文件包含更多信息。
例如,以下命令使用 zephyr.elf 可执行文件并将地址 0x000045a2 转换为其源代码位置。-e 标志用于指定二进制文件名:
addr2line -e build/zephyr/zephyr.elf 0x000045a2
输出将指定源代码位置的完整路径和代码行,类似于:
C:/ncs/v2.9.0/modules/hal/nordic/nrfx/drivers/src/nrfx_gpiote.c:668
其他有用的标志选项包括:
-a:在每个转换位置前显示地址
-f:显示包含每个位置的函数名称
-p:使输出更易于阅读
Core Dump(核心转储)
在 Zephyr 中,核心转储处理涉及在程序崩溃或遇到错误时捕获程序状态,使诊断和调试问题变得更容易。核心转储在嵌入式系统开发中特别有用。
当启用核心转储模块并发生致命错误时,CPU 寄存器和内存内容会被打印或存储,具体取决于后端配置。这些核心转储数据可以作为远程目标输入到定制的 GDB 服务器中,供 GDB(和其他 GDB 兼容的调试器)使用。调试器可以检查 CPU 寄存器、内存内容和堆栈。
核心转储支持在 Zephyr 中默认不启用。要使用核心转储,需要确保设备不会立即重启,并指定存储转储的位置。在 prj.conf 中添加相关配置来确保设备不重启。
对于存储核心转储,需要指定在闪存中存储核心转储的位置。Zephyr 提供了多种核心转储存储选项,包括闪存或外部存储设备。这在 prj.conf 文件中配置。可以选择日志后端存储或闪存分区存储。
如果启用闪存分区存储,必须在设备树中定义核心转储闪存分区,指定起始偏移地址和大小。偏移值会因不同目标设备而异。
GDB 服务器
GDB 服务器是一个计算机应用程序,使远程调试其他应用程序成为可能。之后可以在调试器中检查 CPU 寄存器、内存内容和堆栈。这通常包括以下步骤:
首先从设备获取核心转储日志。然后将核心转储日志转换为 GDB 服务器可以解析的二进制格式,可以使用相关脚本进行转换。接着使用核心转储二进制日志文件和 Zephyr ELF 文件作为参数启动定制 GDB 服务器。最后启动对应目标架构的调试器。
这样就可以通过核心转储来分析和调试致命错误,帮助开发人员快速定位问题并进行修复。
nRF Connect SDK 设备树故障排除指南
什么是设备树?
设备树是一种层次化的数据结构,用来描述硬件信息,比如开发板、芯片、模块等。设备树就像是硬件的"配置清单",从开发板上 LED 灯的 GPIO 引脚配置,到外设的内存映射地址,所有硬件相关的信息都记录在其中。
设备树有两个主要用途:向设备驱动模型描述硬件结构,以及为已定义的硬件提供初始配置参数。
常见设备树错误及解决方法
1. 缺少设备树头文件
与 Kconfig 符号不同,设备树的头文件 devicetree.h 需要手动添加到项目中。虽然某些头文件可能间接包含了设备树信息,但并非总是如此,所以最好主动包含这个头文件。
2. 出现 "Undefined reference to _device_dts_ord" 错误
当外设配置不正确时,会产生包含 error: '__device_dts_ord_ 的构建错误,这表明问题与设备树相关。
排查方法:
- 查看
build/zephyr/include/generated/devicetree_generated.h文件,这个文件能提供关于哪个外设导致设备树错误的信息。
3. 检查设备是否已启用
设备树只负责描述硬件,要启用外设的驱动程序,还需要在 prj.conf 文件中使用正确的 Kconfig 配置来启用外设。
例如,如果设备使用 I2C 通信,需要设置 CONFIG_I2C=y。
4. 检查缺失的绑定文件
如果构建时找不到设备树绑定文件,可能是因为节点的 compatible 属性定义不正确,或者绑定文件根本不存在。可以查看 Zephyr 的绑定索引来确认设备绑定是否存在,如果没有列出,可能需要自己创建。
5. 命名规范问题
在设备树覆盖文件中,需要遵循特定的命名规范:
在代码中引用设备树节点时:
设备树覆盖文件名必须使用小写字母
特殊字符需要转换为下划线
错误示例:
/* 错误做法: */
#define MY_CLOCK_FREQ DT_PROP(DT_PATH(soc, i2c@1234000), clock-frequency)
/* ^ ^
* @ 应该是 _ - 应该是 _ */正确示例:
/* 正确做法: */
#define MY_CLOCK_FREQ DT_PROP(DT_PATH(soc, i2c_1234000), clock_frequency)在设备树覆盖文件中设置属性时:
错误示例:
/* 错误做法;会产生设备树错误 */
&{/soc/i2c_12340000/} {
clock_frequency = <115200>;
};正确示例:
/* 正确做法。覆盖文件就是 DTS 片段 */
&{/soc/i2c@12340000/} {
clock-frequency = <115200>;
};6. 验证属性配置
如果在读取属性节点时遇到编译错误,需要检查并确认所有必需的属性都已设置。可以在绑定列表中查看必需的属性。
建议使用简单的条件判断语句来验证节点是否存在:
#if !DT_NODE_EXIST(DT_NODELABEL(NameOfYourNode))
#Error "NameOfYourNode not valid"
#endif这样可以在编译时就发现节点定义问题,避免运行时错误。
物理调试方法指南
当应用程序能够运行,设备也能正常启动,但某些功能仍然不正常时,需要进行物理调试。可能遇到的问题包括 UART 或 I2C/SPI 通信错误、自定义电路板性能不达预期,或者测试环境表现异常。
调试工具介绍
不同的问题需要不同的调试方法。射频性能问题与 UART 线路噪声问题的排查方式完全不同,没有万能的解决工具。但以下几种工具在大多数情况下都很有用:
数字逻辑分析仪(DLA):专门用于分析数字信号和逻辑状态。能以图形格式显示二进制数据,适合分析数字通信协议和逻辑层面的问题。
功率分析仪套件 II(PPK2):可以测量设备的电流消耗,这能提供关于设备状态的重要信息。
万用表:用于验证电压水平、电流或电阻值。当怀疑 PCB 上某些元件可能损坏时特别有用。
示波器:主要用于在时域内可视化和分析信号。在屏幕上以波形显示电压信号,横轴表示时间,纵轴表示电压,非常适合观察信号随时间的变化。
调试流程
当代码能够构建并成功烧录到设备,但功能异常时,通常按以下步骤排查:
设备是否使用正确的电压供电?
是否选择了正确的 COM 端口?
如果有连接线,是否连接正确?
使用 LED 进行调试
LED 调试是验证代码中某个函数或部分是否被执行的简单方法。也可以通过设置引脚电平并用 PPK、万用表或 DLA 测量来实现。当无法使用打印接口时,LED 或引脚电平能提供关于代码执行位置的有用信息。
示例代码:
static void start_scan(void)
{
struct bt_le_scan_param scan_param = {
.type = BT_HCI_LE_SCAN_PASSIVE,
.options = BT_LE_SCAN_OPT_NONE,
.interval = SCAN_INTERVAL,
.window = SCAN_WINDOW,
};
int err;
err = bt_le_scan_start(&scan_param,NULL);
if (err) {
gpio_pin_toggle_dt(&led); //如果函数失败则切换LED状态
return;
}
LOG_INF("Scanning successfully started");
}PPK 能够同时读取多达八个数字输入通道,在某些情况下比使用 LED 更方便。这意味着可以将 PPK 用作简单的低端逻辑分析仪。将数字输入连接到被测设备(DUT)的 I/O 引脚即可实现。要使用此功能,DUT 必须由 1.6-5.5V 的 VCC 电压供电。数字输入可以显示 DUT 在不同时间点执行的代码。
电源和电压问题
设备的电流消耗可以很好地指示是否存在问题。如果电流消耗与预期结果相差很大,就有理由进行调查。此时功率分析仪套件(PPK)或类似设备很有用。
需要注意的是,当调试器通过 USB 连接到计算机且逻辑连接(即使没有启动调试会话)时,设备无法进入睡眠模式。因此,要正确测量电流消耗,需要通过外部供电引脚为设备供电,而不是通过 USB。USB 接口还可能在测量中引入噪声。
低功耗晶振问题
检查是否设置了正确的晶振。如果使用没有外部 LFCLK 的自定义电路板,需要使用 Kconfig 标志激活低频时钟(LFCLK),因为开发板默认使用已启用的外部 LFCLK。
配置示例:
CONFIG_CLOCK_CONTROL_NRF_K32SRC_RC=y
CONFIG_CLOCK_CONTROL_NRF_K32SRC_500PPM=y #此配置并非对所有设备都有效nRF Connect for VS Code 调试器进阶练习
本练习将深入学习如何使用 nRF Connect for VS Code 中的调试器功能。在第一课练习基础上,将学习如何通过调试器直接与芯片外设进行读写操作,并探索高级调试方法,包括条件断点、使用 Cortex-M 调试监视器进行非停机调试等技术。
练习分为两个部分:首先使用 VS Code 调试功能中的外设视图来控制开发板的 LED;然后学习高级调试技术。
第一部分:外设交互操作
1. 打开练习代码
在 nRF Connect for VS Code 扩展中选择"创建新应用程序",然后选择"复制示例",搜索"Lesson 2 -- Exercise 1"。确保使用与当前 SDK 版本匹配的分支。
2. 添加构建配置
为设备创建新的构建配置。在优化菜单中选择"为调试优化"选项并构建配置。
3. 进入 VS Code 调试模式
在 nRF Connect 扩展中选择调试操作。
重要提示:从 nRF Connect SDK v2.8.0 开始,Sysbuild 成为默认构建系统。在调试选项可用之前,必须从应用程序视图中选择特定的应用程序镜像(而不是完整构建系统)。
4. 外设操作概览
应用程序在 main 循环开始处停止。现在将通过操作 GPIO 寄存器值来切换 LED 1。
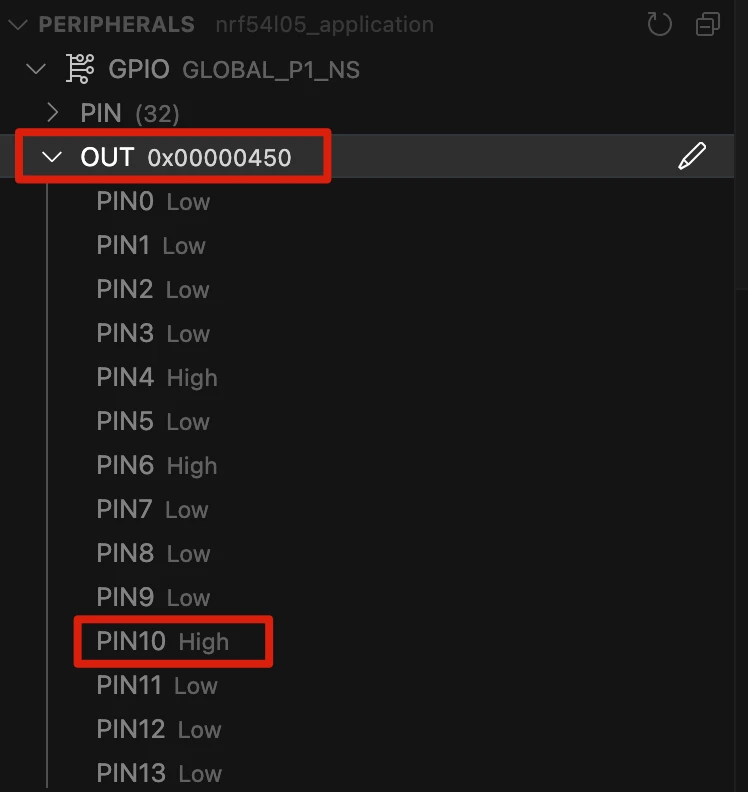
本练习使用 nRF54L15,但在其他设备上步骤相同,只是引脚编号不同。查看开发板底部可以看到哪个引脚连接到 LED1。在 nRF54L15dk 上,LED1 连接到 P1.10。
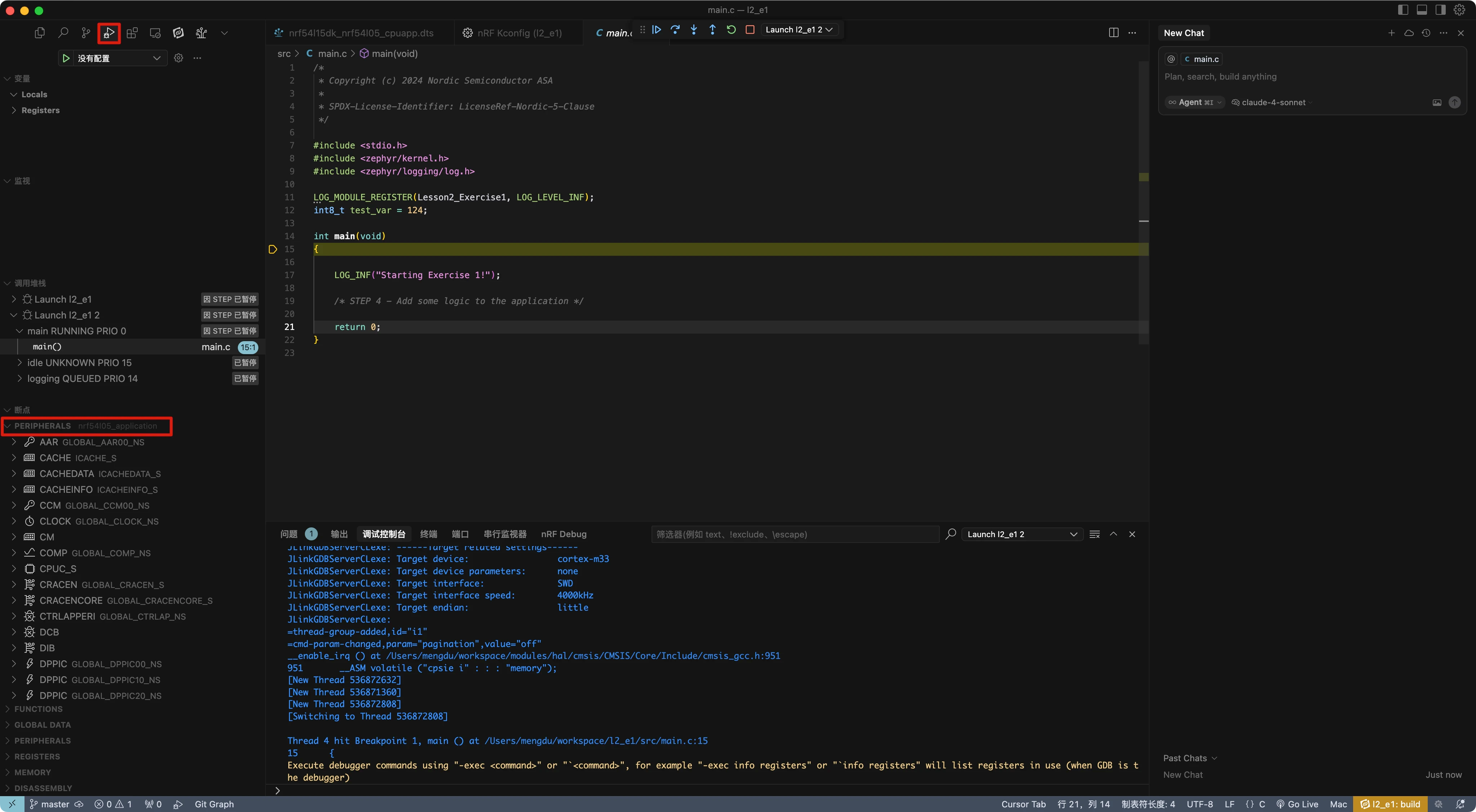
4.1 确定 LED1 连接的 GPIO 引脚
查看开发板底部,找到连接到 LED1 的引脚。在 nRF54L15 DK 上,LED1 连接到 P1.10。
4.2 探索 GPIO
在外设视图中找到 GPIO P0 或 P1 菜单,取决于要更改 P0.xx 还是 P1.xx。这里要更改 P1.10,所以展开 GPIO P1 菜单。
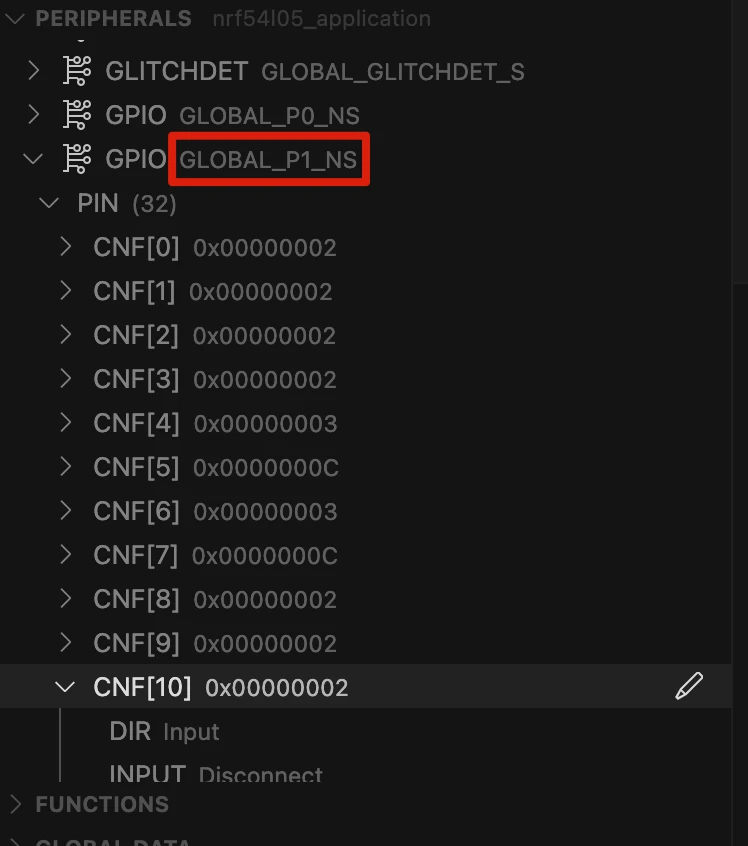
4.3 配置引脚
展开"DIR"子菜单,找到要更改的引脚(本例中是 PIN 10)。将引脚从输入模式改为输出模式。
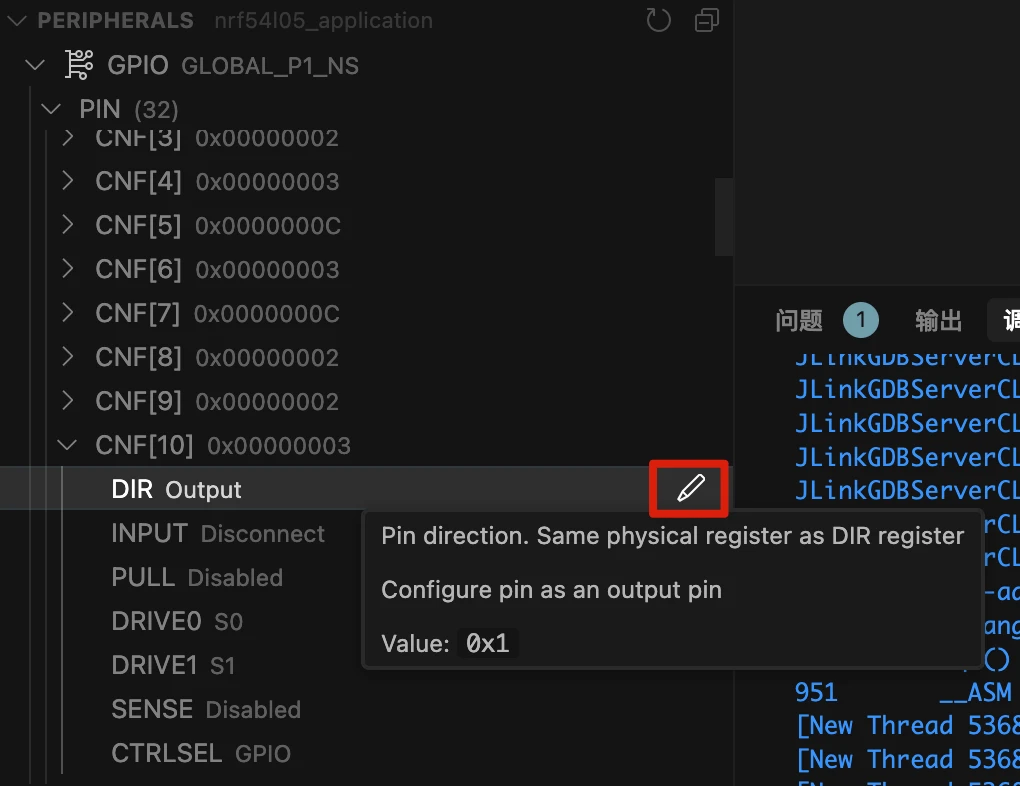
4.4 切换 LED
展开"OUT"子菜单,再次找到相同的引脚(本例中是 PIN 10)。将引脚从低电平改为高电平来切换 LED1。
第二部分:高级调试技术
5. 添加基本逻辑代码
在 main.c 中添加以下代码:
for (int i = 0; i < 10; i++)
{
test_var = test_var + 1;
LOG_INF("test_var = %d",test_var);
}6. 构建并烧录应用程序
连接到设备的串行接口,构建应用程序并烧录到设备。应用程序运行时会看到以下输出:
*** Booting nRF Connect SDK ***
Starting Exercise 1!
test_var = 125
test_var = 126
test_var = 127
test_var = -128
test_var = -127
test_var = -126
test_var = -125
test_var = -124
test_var = -123
test_var = -1227. 观察异常现象
这里有些奇怪:127+1 不应该等于 -128。让我们使用 VS Code 的调试功能来理解发生了什么。
7.1 添加条件断点
普通断点在某些情况下不是最佳选择。例如,遇到的整数溢出问题发生在循环内部,在条件(test_var == 127)之后出现。在循环内使用普通断点意味着每次迭代都要停止代码,需要手动按继续直到达到触发问题的条件。这在某些情况下可能不切实际或效率低下。对于这种情况,使用条件断点。
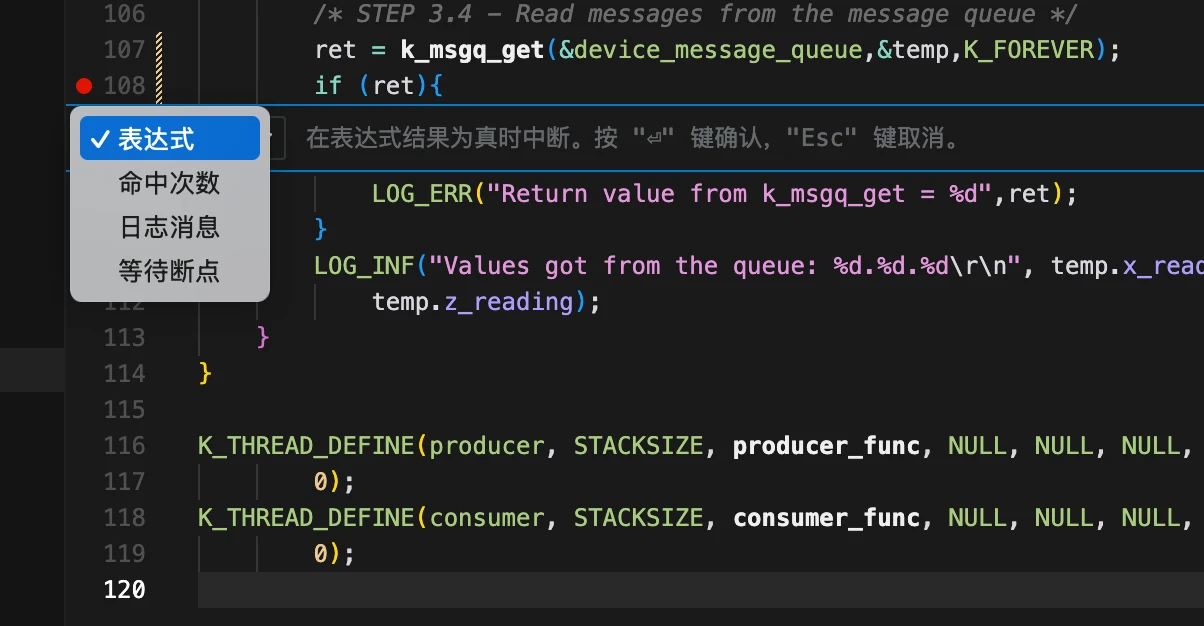
我们将添加表达式条件类型的高级条件断点,仅在表达式求值为真时触发。在这个例子中,条件是(test_var == 127)。
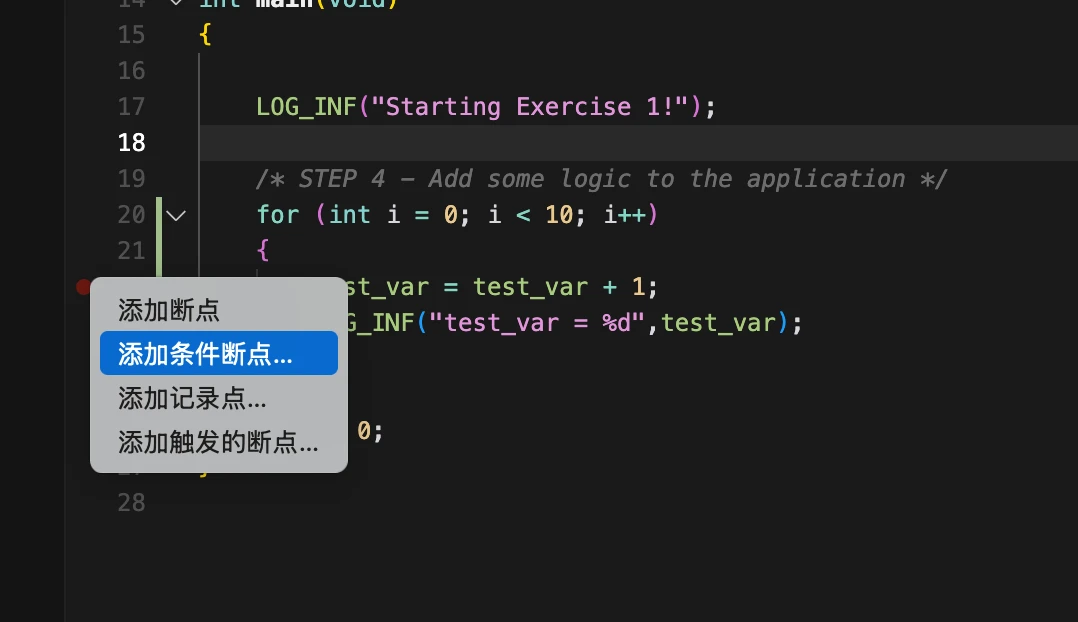
7.1.1 添加条件断点
在 test_var 递增的行旁边(行号列)右键单击,选择"添加条件断点"。
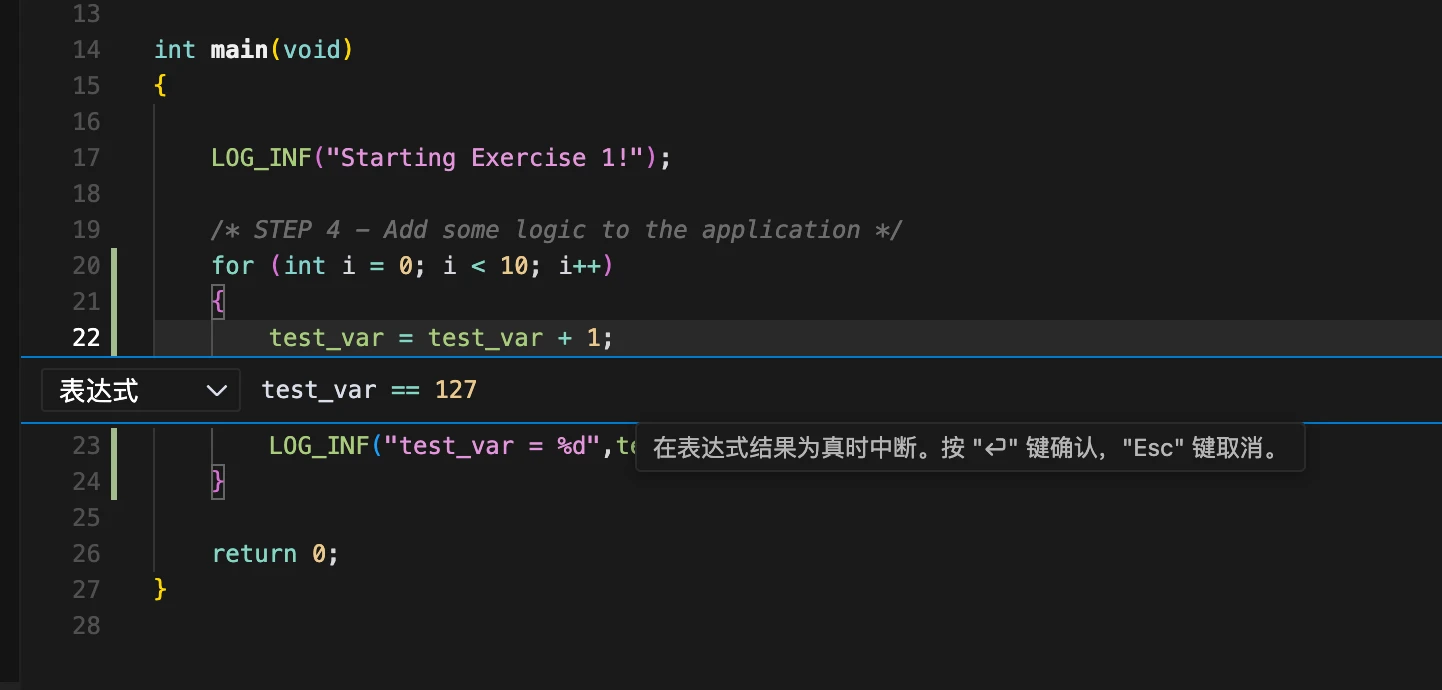
7.1.2 设置条件
在表达式字段中输入希望停止执行的条件(test_var == 127)。确保按回车键确认。
7.2 在 main() 函数添加普通断点进行对比
注意条件断点的图标与普通断点图标不同。

7.3 以调试模式运行应用程序
应用程序会在 main() 处停止,因为添加了普通断点。
7.4 打开内存探索器
打开 nRF Debug -> Memory Explorer -> Data,然后点击数据窗口右上角的"转到符号"图标。
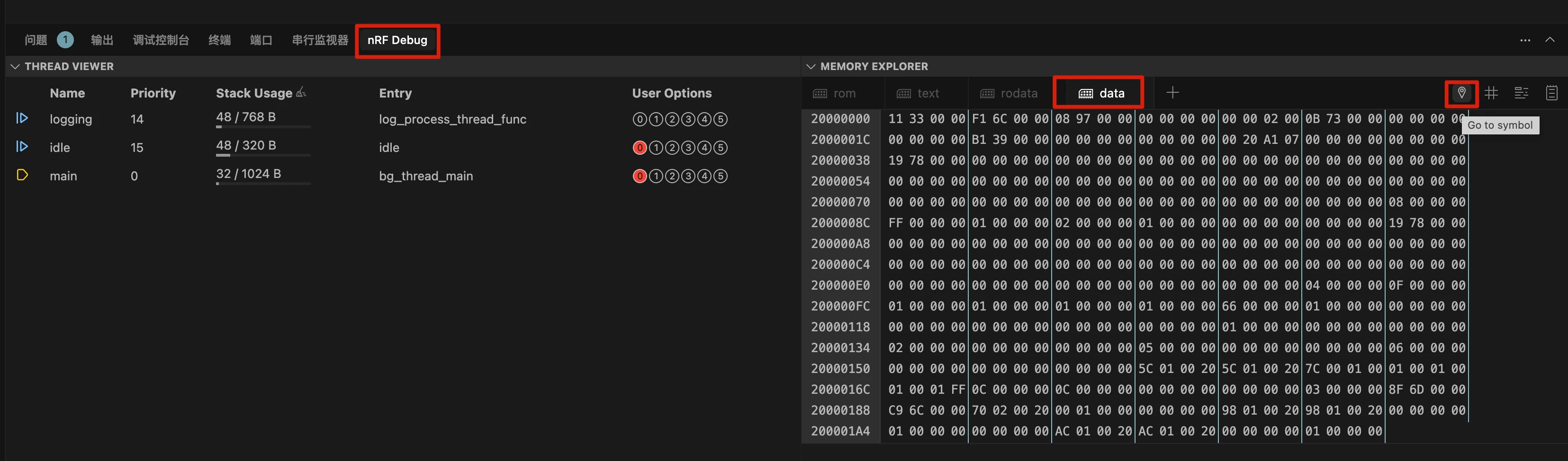
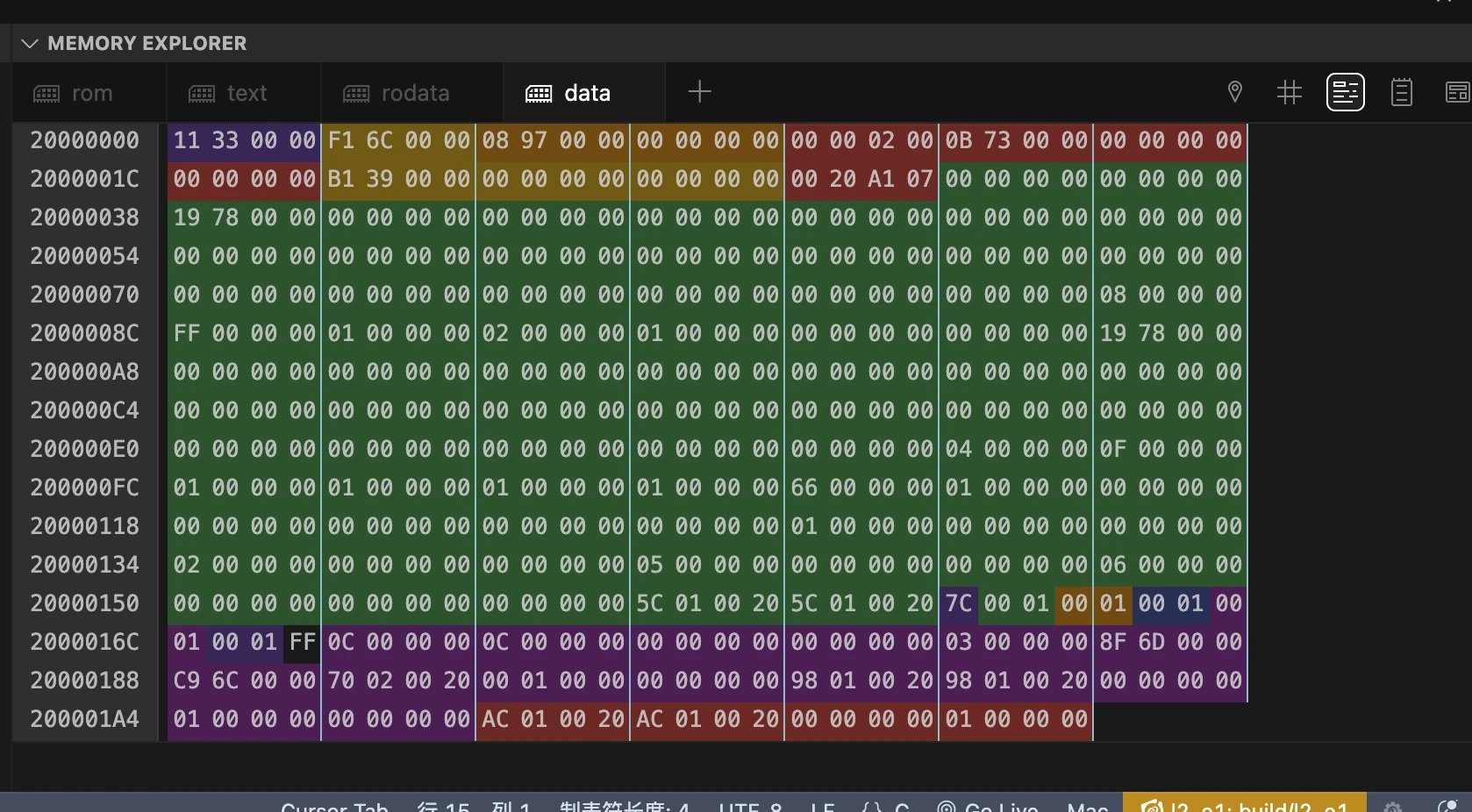
要获得与上图相同的彩色视图,请在菜单中选择显示符号图标,如下图所示。

7.5 检查全局变量
输入要在内存中检查的全局变量,本例中是 test_var。分配给该变量的内存区域将被高亮显示。
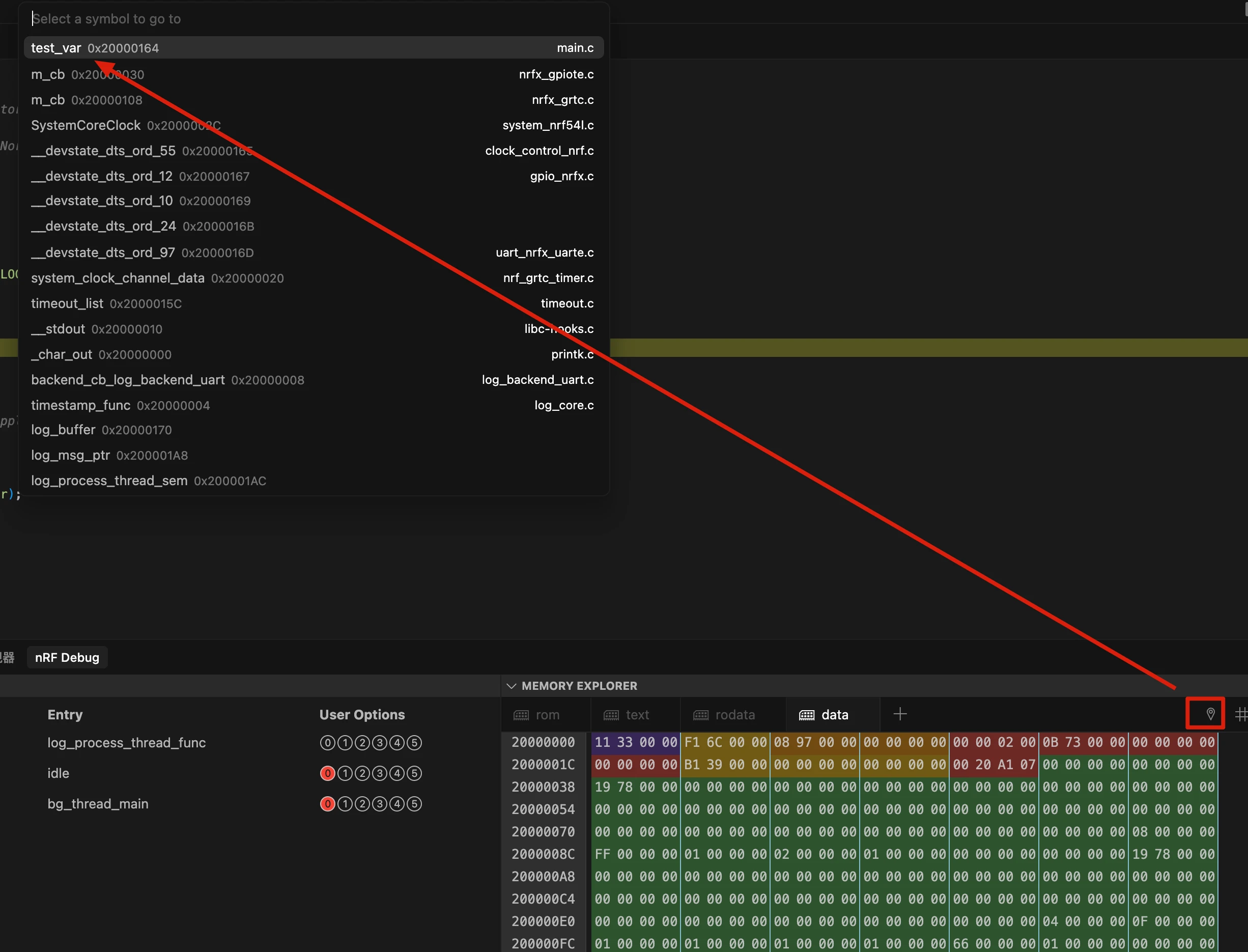
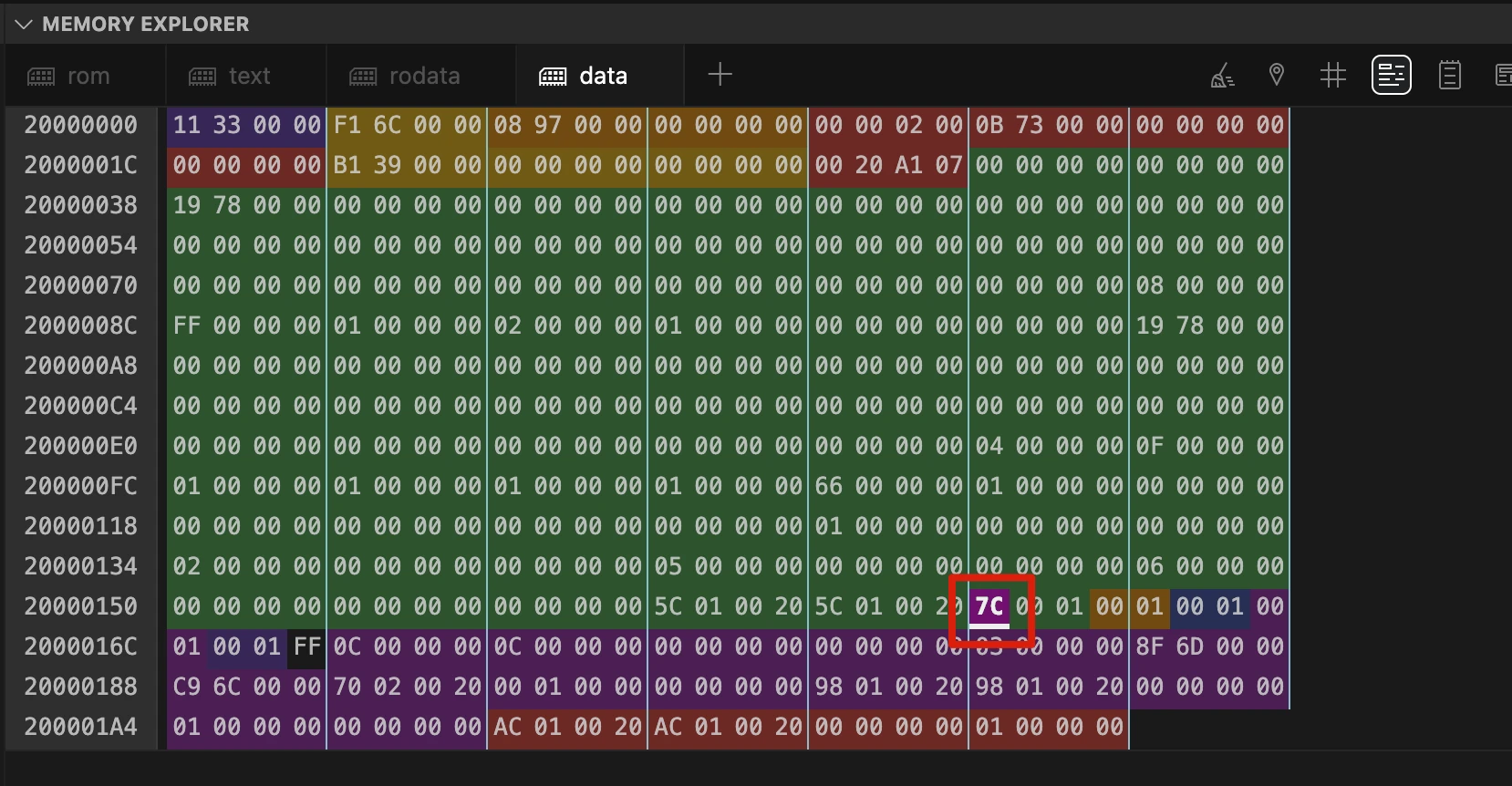
注意:"转到符号"功能仅适用于全局对象(全局变量、全局函数等)。对于局部对象,需要找出局部对象的地址并使用"转到地址"功能(# 符号)。
内存探索器显示目标对象(如变量 test_var)所在的内存区域。这对于检测越界内存写入非常有用。内存探索器还允许直接读写内存,就像操作外设一样。
7.6 继续执行到条件断点
按继续按钮(F5)运行应用程序到下一个断点,这是在整数溢出之前触发的条件断点。
注意分配给变量 test_var 的内存位置保存值 127(0x7F),可以看到变量的相邻内存地址。实际上可以将鼠标悬停在相邻单元格上,找出该区域中定位的对象。这在调试堆栈和大缓冲区溢出时非常有用。
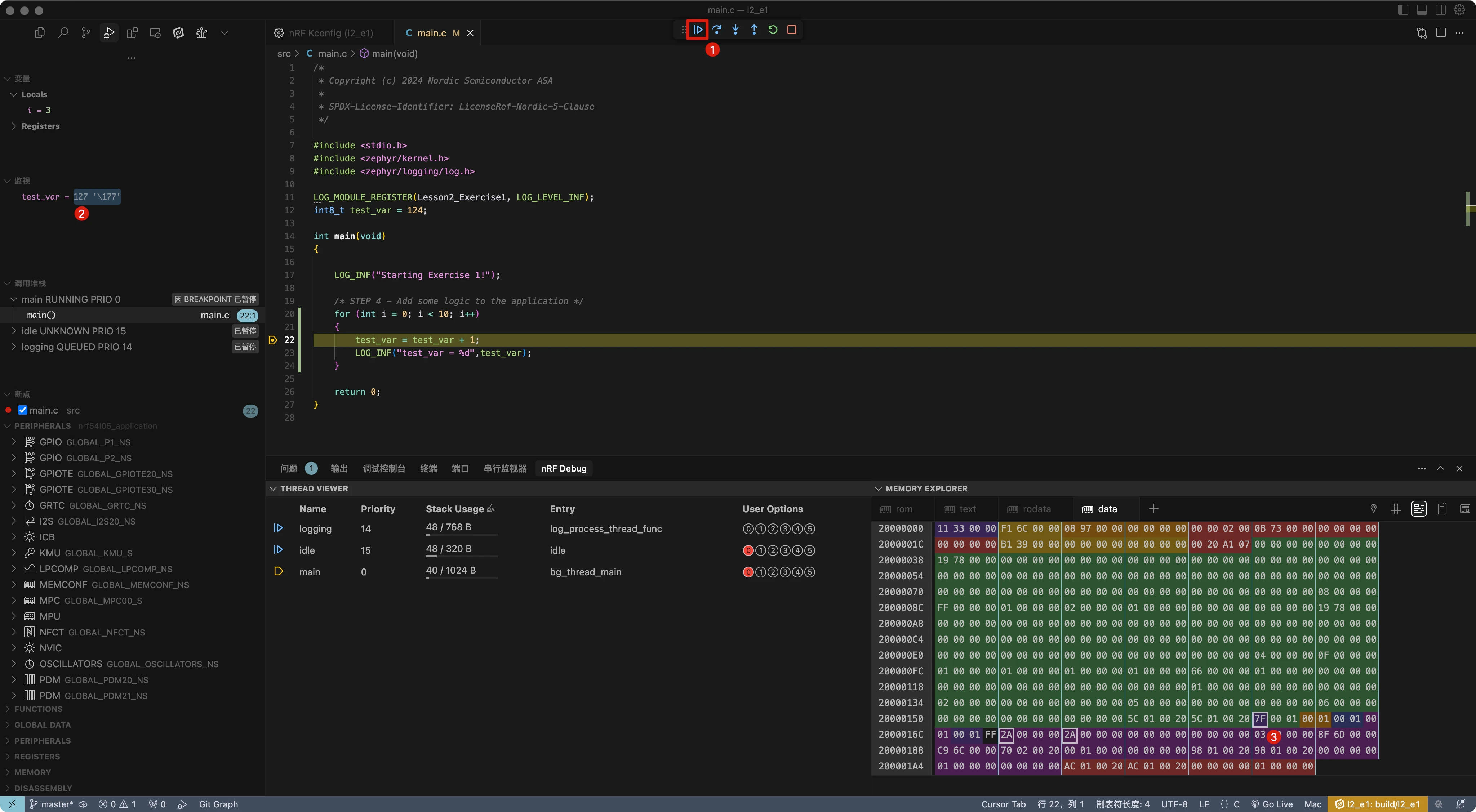
也可以右键单击变量名并选择"添加到监视",就像在第一课练习 1 中所做的那样。

7.7 单步执行观察溢出
按“逐过程”(F10)执行下一行。
test_var 定义为 int8_t 变量,这是宽度为 8 位的有符号整数类型。有符号 8 位整数的最小值是 -128,最大值是 127。当 test_var 的值为 127 时尝试再次递增,试图为 8 位整数添加过大的值,导致整数溢出。
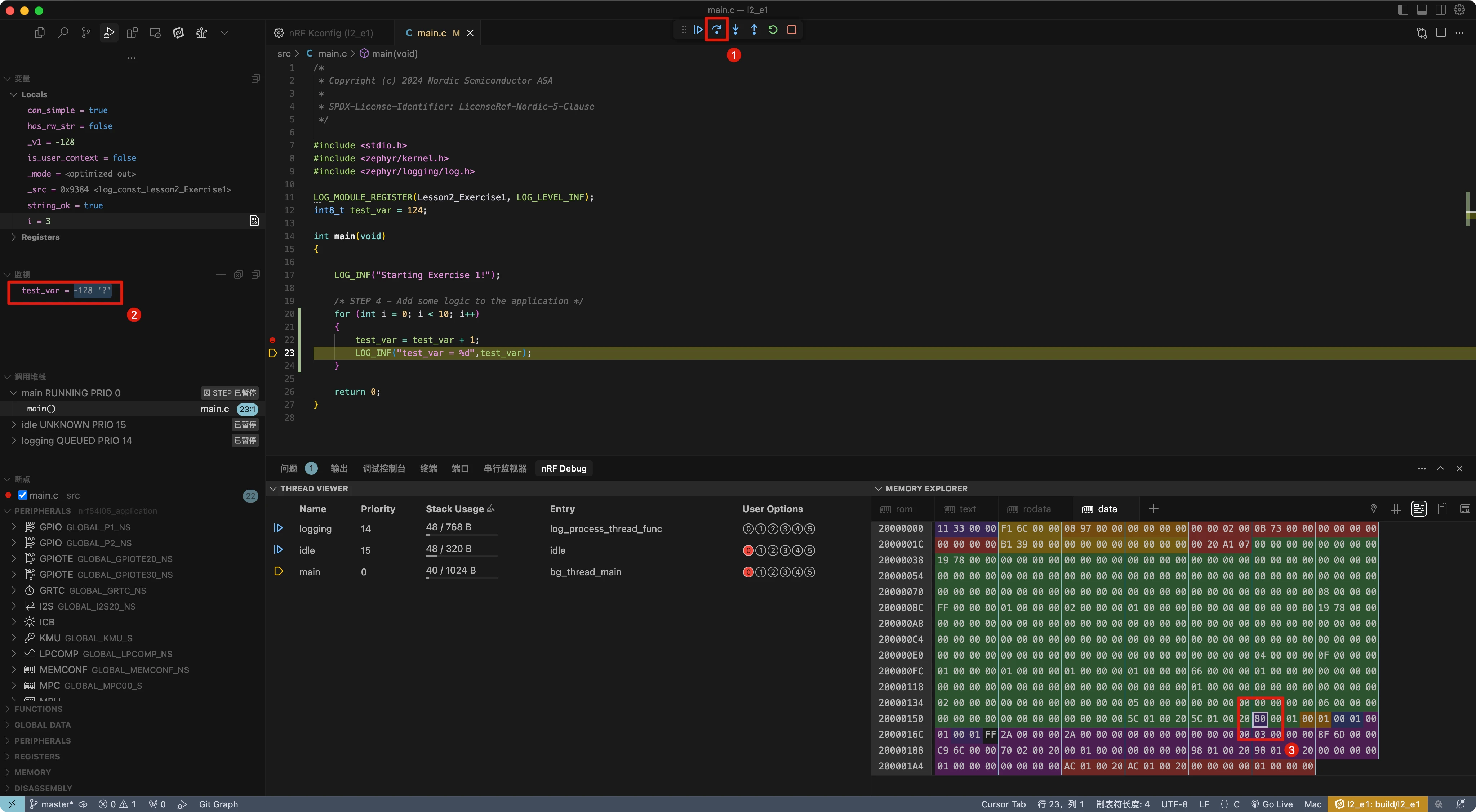
对于使用的编译器,行为是将变量翻转到最小值。请注意,根据 C 标准,整数溢出的结果是未定义行为,因此应该通过应用正确的编程技术在代码中防止此类情况(例如:在递增/递减之前检查 INT8_MAX 和 INT8_MIN)。
溢出和下溢错误可能导致应用程序中的意外结果,因此了解它们并采取措施防止它们很重要。在堆栈中也可能发生同样的情况,这称为堆栈溢出。当堆栈使用的内存超过分配给它的内存时,就会发生堆栈溢出。
核心转储和 addr2line 调试
本练习将学习使用核心转储(core dump)和 addr2line 工具来调试应用程序崩溃问题。首先配置应用程序启用核心转储功能,并选择日志后端将核心转储信息输出到终端。然后创建一个在按下按钮 1 时触发故障错误的函数,学习如何从致命崩溃中提取信息,使用 GDB 调试器和 addr2line 工具进行分析。
注意:如果不使用 VS Code 中的 nRF Connect 终端,请确保终端已安装 Python 3,并运行命令 pip install pyelftools 安装所需工具。nRF Connect 终端已预装这些工具。
在 nRF Connect for VS Code 扩展中选择"创建新应用程序",选择"复制示例",搜索"Lesson 2 -- Exercise 2"。
第一部分:核心转储调试
1. 启用核心转储和选择日志后端
1.1 通过配置启用核心转储
在 prj.conf 文件中添加以下配置:
CONFIG_DEBUG_COREDUMP=y
CONFIG_DEBUG_COREDUMP_BACKEND_LOGGING=y1.2 包含核心转储头文件
在 main.c 中添加:
#include <zephyr/debug/coredump.h>2. 添加按钮触发崩溃功能
需要确保应用程序在按下按钮 1 时发生故障错误。
2.1 定义触发故障的函数
定义 crash_function 函数,尝试解引用空指针,导致应用程序崩溃:
void crash_function(uint32_t *addr)
{
LOG_INF("Button pressed at %" PRIu32, k_cycle_get_32());
LOG_INF("Coredump: %s", CONFIG_BOARD);
#if !defined(CONFIG_CPU_CORTEX_M)
/* 空指针引用 */
*addr = 0;
#else
ARG_UNUSED(addr);
/* 在启用 TrustZone 的构建中解引用空指针可能导致系统崩溃,
* 因此改用未定义指令来触发 CPU 故障。
*/
__asm__ volatile("udf #0" : : : );
#endif
}2.2 在按钮处理函数中调用崩溃函数
在 button_handler() 中添加:
crash_function(0);3. 构建并烧录应用程序
重要提示:当前 coredump_gdbserver.py 存在一个错误,如果使用"为调试优化"构建会导致崩溃。
在串行终端中会看到类似以下的日志输出:
*** Booting nRF Connect SDK ***
*** Using Zephyr OS ***
[00:00:00.430,769] <inf> Lesson2_Exercise2: Press button 1 to get a fault error4. 按下按钮 1 触发崩溃
按下按钮 1 会触发 Zephyr 中的致命错误。由于配置了通过日志接口输出核心转储,核心转储信息会在终端窗口中输出。输出内容很长,以下是截断的示例,但需要完整的核心转储:
[00:00:03.576,141] <inf> Lesson2_Exercise2: Button 1 pressed
[00:00:03.576,171] <inf> Lesson2_Exercise2: Button pressed at 117183
[00:00:03.576,202] <inf> Lesson2_Exercise2: Coredump: nrf52840dk_nrf52840
[00:00:25.341,857] <err> os: ***** USAGE FAULT *****
[00:00:25.341,888] <err> os: Attempt to execute undefined instruction
[00:00:25.341,888] <err> os: r0/a1: 0x00000001 r1/a2: 0x00000000 r2/a3: 0x00000002
[00:00:25.341,918] <err> os: r3/a4: 0x20000218 r12/ip: 0x0000000c r14/lr: 0x000003eb
[00:00:25.341,918] <err> os: xpsr: 0x81000016
[00:00:25.341,949] <err> os: Faulting instruction address (r15/pc): 0x000003ea
[00:00:25.341,979] <err> os: >>> ZEPHYR FATAL ERROR 36: Unknown error on CPU 0
[00:00:25.433,898] <err> coredump: #CD:BEGIN#
...
[00:00:28.769,744] <err> coredump: #CD:END#5. 分析输出
输出告诉我们设备遇到了致命的未知错误,发生在中断处理期间的故障。内存地址是 0x000003ea,这个地址也可以在反汇编窗口中使用来查看错误发生的位置。
6. 复制核心转储到文件
将从 #CD:BEGIN 到 #CD:END# 的核心转储内容复制到项目文件夹中的 dump.log 文件。
7. 转换为二进制文件
运行位于 <install_path>/<version_directory>/zephyr/scripts/coredump/coredump_serial_log_parser.py 的 Python 脚本,将文本文件转换为二进制文件:
python <install_path>/<version_directory>/zephyr/scripts/coredump/coredump_serial_log_parser.py dump.log dump.bin8. 启动自定义 GDB 服务器
在同一目录中,使用 coredump_gdbserver.py 脚本启动自定义 GDB 服务器:
python /<install_path>/<version_directory>/zephyr/scripts/coredump/coredump_gdbserver.py build/l2_e2/zephyr/zephyr.elf dump.bin -v会看到类似以下的日志输出:
[INFO][gdbstub] Waiting GDB connection on port 1234...9. 启动 GDB 会话
在项目文件夹中打开新的终端实例,输入以下命令启动 GDB 会话:
ncs_install_path/PathToToolChain/opt/zephyr-sdk/arm-zephyr-eabi/bin/arm-zephyr-eabi-gdb build/l2_e2/zephyr/zephyr.elf10. 连接到调试实例
启动 GDB 实例后,输入以下命令连接到调试实例:
target remote localhost:123411. 查看崩溃前的回溯
运行回溯命令 bt 查看崩溃前的程序堆栈:
(gdb) bt
#0 func_3 (addr=0x0 <thread_print_cb>) at ../src/main.c:61
#1 func_2 (addr=0x0 <thread_print_cb>) at ../src/main.c:67
#2 crash_function (addr=0x0 <thread_print_cb>) at ../src/main.c:72
#3 button_pressed (dev=<optimized out>, cb=<optimized out>, pins=<optimized out>) at ../src/main.c:44
#4 0x00000000 in ?? ()可以看到按钮按下函数调用了 crash_function,然后调用 func_2,再调用 func_3,最终导致致命崩溃。
第二部分:使用 addr2line 调试
12. 记录故障指令地址
查看按下按钮 1 后的日志输出,记录故障指令地址 0x000003ea。
13. 找到工具链中的 addr2line 路径
addr2line 应用程序包含在 nRF Connect SDK 安装中,位于工具链目录:
ncs_install_path/toolchain_version/opt/zephyr-sdk/arm-zephyr-eabi/bin/arm-zephyr-eabi-addr2line14. 使用故障地址运行 addr2line
对于非 Sysbuild 构建:
Linux/OSX:
/toolchains/<toolchain_version>/opt/zephyr-sdk/arm-zephyr-eabi/bin/arm-zephyr-eabi-addr2line -e build/zephyr/zephyr.elf 0x000003eaWindows:
\toolchains\<toolchain_version>\opt\zephyr-sdk\arm-zephyr-eabi\bin\arm-zephyr-eabi-addr2line.exe -e build/zephyr/zephyr.elf 0x000003ea输出类似:
<install_path>\lesson2\l2_e2_sol\build/../src/main.c:61这表示导致故障的指令位于 main.c 第 61 行。查看第 61 行可以找到:
__asm__ volatile("udf #0" : : : );这展示了 addr2line 工具如何用于找出应用程序崩溃的位置,帮助进一步调试。
核心转储使用场景
在产品开发阶段,通常可以通过调试器访问固件调试,这在所有 Nordic 开发套件中都很常见。因此本地调试是排除固件故障的推荐方法。然而,在接近生产时,自定义硬件很可能缺乏内置调试器。在这种情况下,核心转储等技术对调试很有用。
核心转储使用设备内存存储崩溃时的设备状态,基本上是包含寄存器状态、堆栈跟踪、内存内容等的内存快照。
使用核心转储时需要了解存储空间要求。它最适合无法直接调试访问的现场部署设备。这些核心转储可以在设备重启时传输到远程进行分析。nRF Connect SDK 与 Memfault 原生集成,核心转储可以通过 Wi-Fi、蜂窝网络或蓝牙 LE(通过网关)传输到云端进行可视化和分析。
使用核心转储的情况:
调试现场问题
无法物理访问设备
需要事后分析
使用本地调试的情况:
开发阶段
需要交互式控制
测试特定代码路径
性能优化
最佳实践:实施两种方法
开发时使用本地调试
生产时考虑核心转储功能
设备树调试练习
本练习的目标是修复与设备树相关的构建错误,让应用程序能够成功构建。
打开练习代码
在 nRF Connect for VS Code 扩展中选择"创建新应用程序",选择"复制示例",搜索"Lesson 2 -- Exercise 3"。这是一个简单的应用程序,每次按下按钮 1 时会打印一条消息。
1. 构建应用程序
构建应该会失败,并给出类似以下的错误:
error: '__device_dts_ord_11' undeclared here (not in a function); did you mean '__device_dts_ord_15'?
85 | #define DEVICE_NAME_GET(dev_id) _CONCAT(__device_, dev_id)
| ^~~~~~~~~
...
lesson2/Exercise3/src/main.c:15:40: note: in expansion of macro 'GPIO_DT_SPEC_GET'
15 | static const struct gpio_dt_spec led = GPIO_DT_SPEC_GET(LED0_NODE, gpios);2. 在错误消息中找到 ID
构建日志显示存在设备错误,可以从 __device_dts_ord_11 看到问题。这里的"11"是节点标识符,可以说明出现故障的设备树实例。有了这个节点标识符,可以在 <build>l2_e3/zephyr/include/generated/zephyr/devicetree_generated.h 文件中查找错误消息中的 ID。
3. 调查构建失败的原因
在 devicetree_generated.h 文件中可以看到以下内容:
/*
* Generated by gen_defines.py
*
* DTS input file:
* /home/rusi/Documents/ncs-inter/lesson2/Exercise1/Lesson2_exercise1/build/zephyr/zephyr.dts.pre
*
* Directories with bindings:
* /home/rusi/ncs/v2.5.0/nrf/dts/bindings, $ZEPHYR_BASE/dts/bindings
*
* Node dependency ordering (ordinal and path):
* 0 /
* 1 /aliases
* 2 /analog-connector
* 3 /chosen
* 4 /connector
* 5 /entropy_bt_hci
* 6 /soc
* 7 /soc/interrupt-controller@e000e100
* 8 /soc/timer@40009000
* 9 /sw-pwm
* 10 /buttons
* 11 /soc/gpio@50000000
* 12 /buttons/button_0
* 13 /buttons/button_1
* 14 /buttons/button_2
* 15 /buttons/button_3
* 16 /cpus
* 17 /cpus/cpu@0
* 18 /cpus/cpu@0/itm@e0000000
* 19 /leds
.....错误消息表明问题与设备 ID 11 相关。在这种情况下,可以看到它是 /soc/gpio@50000000。接下来应该查看这个模块并提出以下问题:
设备是否已启用?
要启用设备,"status" 属性应该等于 "okay",并且所有必需的属性都应该填充。这可以通过查看位于 <build>/zephyr/zephyr.dts 的编译后设备树来验证。
检查设备驱动程序是否在 Kconfig 中启用。 在这种情况下,需要验证 CONFIG_GPIO=y 是否设置。
4. 通过启用 gpio0 修复问题
现在错误应该很清楚了。在 zephyr.dts 中可以看到,gpio0 被禁用了:
gpio0: gpio@50000000 {
compatible = "nordic,nrf-gpio";
gpio-controller;
reg = <0x50000000 0x200
0x50000500 0x300>;
#gpio-cells = <2>;
status = "disabled";
port = <0>;
};在所选设备的覆盖文件中,可以看到以下内容:
&gpio0 {
status = "disabled";
};要修复应用程序,需要通过将构建目标的覆盖文件更改为以下内容来启用 gpio0:
&gpio0 {
status = "okay";
};5. 完全重新构建应用程序
由于对覆盖文件进行了更改,需要执行完全重新构建。现在应用程序应该能够成功构建了。
总结
从裸机环境转移到使用设备树时,设备树可能会让人感到困惑,但这个练习应该为解决开发过程中可能遇到的潜在错误提供一些线索。
关键的调试思路是:
从构建错误中找到设备树节点 ID
在生成的设备树文件中查找对应的设备路径
检查设备是否启用(status = "okay")
检查相关驱动是否在 Kconfig 中启用
修改设备树覆盖文件解决问题
这种系统性的排查方法能够帮助快速定位和解决设备树相关的构建问题。
添加自定义开发板支持
在 nRF Connect SDK 和 Zephyr 环境中,板级定义是指描述特定开发板或硬件平台硬件特性及行为的一组配置与初始化文件。
nRF Connect SDK 内置支持多种开发板,包括开发套件、原型平台和参考设计。同时它还支持通过设备树覆盖文件及 Kconfig 片段灵活定制现有板级定义。
但某些情况下,您可能需要为全新设计的硬件平台创建独立命名的完整板级定义。这通常适用于基于 Nordic 芯片自主设计原理图和 PCB 的产品方案。此类方案被称为自定义开发板 ,因其默认不包含在 nRF Connect SDK 中。
nRF Connect SDK 中的板卡定义教程
本课程介绍如何在 nRF Connect SDK 中使用硬件模型 v1 和 v2(分别称为 HWMv1 和 HWMv2)定义板卡。
本练习内容涵盖使用 HWMv2 的 nRF Connect SDK,这是所有新设计的推荐方式。
在使用 nRF Connect SDK 开发应用程序时,板卡概念是开发的核心。基于 Zephyr RTOS 构建的 nRF Connect SDK 强调可移植性,使开发能够在不同硬件平台上运行的应用程序变得更加容易。
什么是板卡?
在这里,板卡指的是要针对的特定硬件平台——无论是 Nordic 开发套件还是自定义 PCB。板卡抽象允许以最少的更改将应用程序从一个平台移植到另一个平台。例如,可以相对容易地将应用程序从 nRF52840 DK 转换到 nRF54L15 DK,甚至转换到自定义板卡。
与传统嵌入式开发不同,传统方式在 C 头文件中定义硬件,而 nRF Connect SDK 使用设备树和 Kconfig 将硬件配置与应用程序代码解耦。
nRF Connect SDK 中的板卡结构
在 nRF Connect SDK 和 Zephyr 的上下文中,板卡本质上是包含一组配置和元数据文件的文件夹,这些文件描述硬件。
包括:
设备树文件 -- 描述硬件,包括 SoC、外设配置等。
Kconfig 文件 -- 指定板卡所需的软件配置选项。
YAML(.yml)文件 -- 包含元数据,如板卡名称、SoC、版本和变体。
可选 C 文件 -- 包括硬件所需的特殊初始化程序。
可选文档 -- 提供板卡特定的文档。
这些组件一起构成了板卡定义,它指定:
SoC 配置 -- 使用的确切 SoC(如 nRF54L15 QFAA)、时钟频率、内存配置和其他硬件特定细节。
外设配置 -- UART、SPI、I2C、GPIO 和其他外设的设置。
内存配置 -- 用于应用程序、内部存储、引导加载程序和其他软件组件的闪存/RAM 大小和内存分区。
引脚映射 -- 引脚与其对应功能之间的映射(SoC 有多个引脚,可以配置为不同功能,如 GPIO、UART、SPI)。
时钟和中断配置 -- 确保整个系统的准确时序。
驱动程序配置 -- 定义硬件驱动程序的参数,如传输设置、时钟设置等。
特殊初始化程序 -- 处理独特的板卡要求,如配置特殊引导加载程序配置、硬件多路复用器配置或特殊 PMIC 功能。
虽然这听起来可能令人生畏,但 SDK 已经提供了大部分配置——特别是对于 CPU、SoC 和架构。
硬件支持层次结构(HWMv2)
nRF Connect SDK 使用与 Zephyr 相同的硬件支持层次结构,分为层次,从最具体到最不具体组织。层次结构从最具体的层(板卡)开始,向更通用的层移动,如 SoC、SoC 系列、SoC 家族、CPU 核心,最后是架构。
板卡 -- 带有 SoC 和外设的特定硬件规格
SoC -- 板卡 CPU 所属的确切片上系统(由 nRF Connect SDK/Zephyr 提供)
SoC 家族 -- 类似 SoC 的广泛群组(由 nRF Connect SDK/Zephyr 提供)
SoC 系列 -- 紧密相关 SoC 的较小子集(由 nRF Connect SDK/Zephyr 提供)
CPU -- 架构中的 CPU(由 nRF Connect SDK/Zephyr 提供)
架构 -- 指令集架构(由 nRF Connect SDK/Zephyr 提供)
从 nRF Connect SDK v2.7.0 开始,硬件模型 v2(HWMv2)现在是板卡定义的默认系统。它取代了较旧的 HWMv1 系统,后者在涉及多个 SoC、核心或架构的现代硬件设置方面存在困难。
为什么使用 HWMv2?
HWMv1 是为单目标板卡(一个 SoC,一个 CPU)设计的,这使其不足以应对多核心或多 SoC 系统。
因此,HWMv2 作为 nRF Connect SDK 和上游 Zephyr 中定义板卡的改进和可扩展系统而诞生。
使用 HWMv2,板卡不再位于架构下,而是位于其供应商下。原因是单个板卡可以有多个架构。
HWMv2 在 Sysbuild 中提供可重用性,这意味着可以选择以更耦合的方式为 MCUboot 或网络核心等生成额外镜像。
板卡、SoC、家族、系列、架构、CPU 集群、变体和版本都有新的通用描述格式。新的通用描述基于 YAML(.yml 或 .yaml),这为定义板卡奠定了灵活且可扩展的系统基础。
要理解 HWMv2 中的这些层次,考虑包含两个 SoC 的 nRF9160 DK:
nRF9160(nRF91 系列的一部分,Cortex-M33)
nRF52840(nRF52 系列的一部分,Cortex-M4)
自定义板卡的板卡文件(浅蓝色框中)是需要自己编写的,而深蓝色框是由 SDK 提供的。
Nordic SoC 的架构将是 ARM 或 RISC-V(用于 nRF54 系列上的协处理器)。
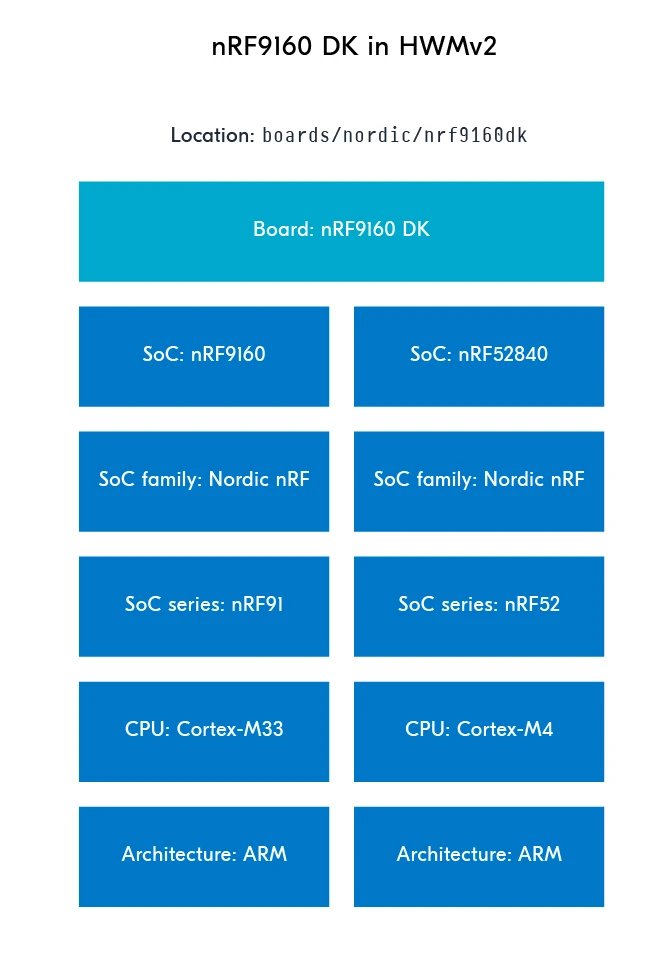
关于驱动程序的说明
虽然板卡文件定义内部 SoC 硬件,但外部组件(如传感器)需要驱动程序。驱动程序通过设备树中的 compatible 属性声明。驱动程序不在板卡文件夹中,而是在 nRF Connect SDK(nrf/drivers/sensor)和 Zephyr(zephyr/drivers/sensor)内有专门的位置。
nRF Connect SDK 已经包含丰富的驱动程序集合。带有外部传感器的板卡示例包括 micro:bit v2、Thingy:53、Thingy:91 和 Thingy:91 X。
创建自定义板卡
本主题将探讨创建自定义板卡文件的不同选项以及自定义板卡命名的指导原则。
将介绍在 HWMv2 中定义自定义板卡所需的必需和可选文件,以及如何创建板卡版本。将逐一研究这些文件并了解它们的作用。
板卡术语(HWMv2)
在硬件模型版本 2 中,每个板卡都有一个唯一的板卡名称(有时称为板卡 ID)。
nRF Connect for VS Code 扩展中的"创建新板卡"图形界面会要求提供板卡名称和人类可读的名称。人类可读的名称可以包含空格或大写字母(如 My nRF54L DK、DevAcademyL3E1),用于显示目的和文档。板卡名称通常是人类可读名称的小写、下划线分隔版本(如 my_nrf54l_dk、devacademyl3e1)。
定义
人类可读名称(full_name) 是板卡的描述性名称,可以包含空格和大写字母。全名用于显示目的和文档,使用户更容易识别板卡。
板卡名称 通常是人类可读名称的小写、下划线分隔版本,所有空白字符都替换为下划线。板卡名称唯一且描述性地标识特定系统,但不包括实际构建镜像可能需要的附加信息。
命名自定义板卡时,需要给板卡一个唯一的名称。在 nRF Connect 终端中运行 west boards 查看已使用的名称列表;不能使用已经使用的名称命名自定义板卡。
以下是输出示例:
esp32c3_042_oled
96b_aerocore2
nrf52840dongle
nrf5340dk
nrf54l15dk
thingy53
nrf52_sparkfun注意:在 HWMv2 中,板卡名称末尾不再需要 SoC 的名称。相反,这在板卡定义的文件之一(board.yml 文件)中明确指定。
除了板卡名称外,板卡还有一个或多个板卡限定符。
让我们检查 HWMv2 中使用的板卡术语,以基于 nRF5340 SoC 的 Ezurio BL5340 DVK 为例。
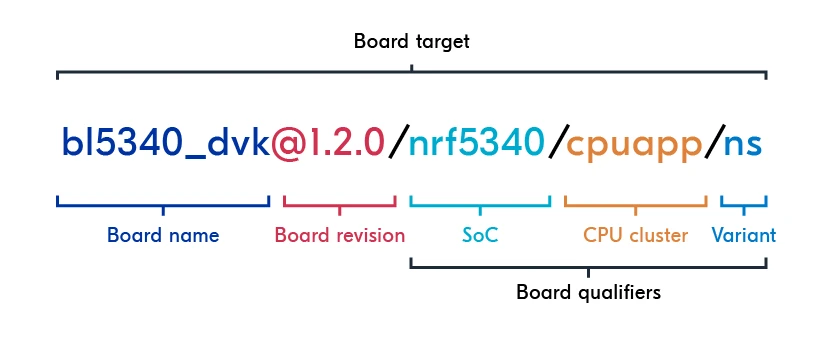
板卡目标:可以提供给任何 Zephyr 构建工具(如 west)的完整字符串,用于为特定硬件系统编译和链接镜像。单核 SoC 的板卡通常有一个板卡目标,而多个 SoC 或多核 SoC 的更高级板卡将有多个板卡目标。
板卡名称:不带空格的板卡名称。
板卡版本(可选):用于捕获新硬件版本中的新变化(新原理图、新 PCB)。
板卡限定符:跟在板卡名称(可选地是板卡版本)后面的额外令牌集合,用正斜杠 / 分隔。
SoC:板卡上使用的特定 SoC。
CPU 集群:由 SoC 层定义。如果 SoC 没有任何集群,则省略此项。
变体:在板卡限定符的上下文中,变体指定 SoC 和 CPU 集群组合的构建的特定类型或配置。变体概念的常见用途包括为支持 Trusted Firmware-M 的平台引入安全和非安全构建,或选择构建中使用的 RAM 类型。变体的另一个用途是用于硬件的不同构建(不是版本)。例如,如果有一个包含传感器的板卡和另一个不包含传感器的完全相同的板卡。
考虑一个人类可读名称为 DevAcademy L3E1 的板卡,基于 nRF52833 SoC。板卡将有板卡名称 devacademyl3e1,板卡目标 devacademyl3e1/nrf52833。板卡可以有一个可选版本,可以指定为 [email protected]/nrf52833,它可以有一个可选变体 [email protected]/nrf52833/sense。
注意:CPU 集群由 SoC 层定义,nRF52833 SoC 没有任何集群。
自定义板卡的位置
在深入了解构成自定义板卡定义的板卡文件之前,需要知道将文件放在哪里。
使用自定义板卡时,有三个主要选项来放置板卡定义文件。每个选项都有自己的优势和限制:
树外(专用目录):在这种方法中,板卡文件存储在 nRF Connect SDK/Zephyr 树之外的单独目录中。需要配置构建系统来定位和使用这些外部板卡文件。这种方法非常适合希望保持板卡定义私有的闭源项目。这是本课程重点关注的方法。
上游到 Zephyr:如果正在开发开发套件、模块、参考设计或打算与 Zephyr 社区共享的原型平台,请选择此选项。它也适用于开源产品。提交到上游的板卡定义必须包含文档,并经过 Zephyr 维护者的审查和批准过程。
在应用程序的 boards 文件夹内:此选项适用于快速原型制作或调试。可以将板卡文件直接放在应用程序文件夹内的 boards 子目录中。这是临时或实验性工作的便捷方法。
板卡文件
考虑基于 nRF52833 SoC 的新开发套件 DevAcademy L3E1。此板卡的板卡名称将是 devacademyl3e1。
创建自定义板卡定义时,记住 SDK 提供从架构到 SoC 的硬件层文件。因此,只需要填充板卡层。板卡层包含这四个必需文件。
boards/<vendor>/devacademyl3e1
├── board.yml
├── Kconfig.devacademyl3e1
├── devacademyl3e1.dts
└── devacademyl3e1-pinctrl.dtsi术语 <vendor> 作为供应商名称的占位符。
必需文件
让我们仔细看看板卡层中的四个必需文件。
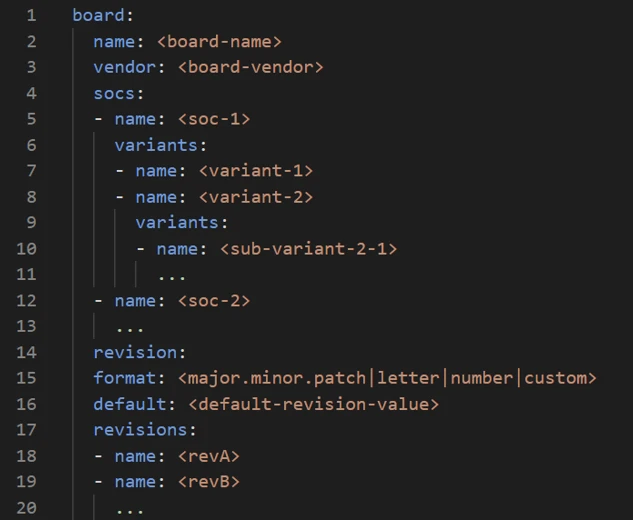
1. board.yml
board.yml 文件是硬件模型 v2(HWMv2)中引入的必需组件。每个板卡文件夹必须包含一个 board.yml,它作为定义板卡关键属性的中央配置文件。
板卡名称:定义板卡名称。
SoC 选择:必须指定至少一个 SoC。
版本:可选;用于定义特定硬件版本。
变体:用于特殊配置,如启用 TF-M 或使用不同的 CPU 核心。
虽然技术上可以使用单个 board.yml 在一个文件夹中定义多个板卡,但这不是常见用例。
当使用扩展工具并输入板卡名称、SoC、SoC 变体和供应商时,board.yml 文件会自动生成。在大多数情况下,不需要手动编辑它。
以下是 board.yml 文件通常的样子。也可以在 board.yml 中包含 full_name: 来指定板卡的人类可读名称。
board.yml 示例
单板卡目标:nRF52840 dongle 基于 nRF52840 SoC,这是一个没有 CPU 集群的单核设备。
四板卡目标:nRF54L15 有由 SoC 层定义的两个 CPU 集群,cpuapp 和 cpuflpr。board.yml 定义了一个新变体 xip,与 cpuflpr 关联。它还定义了另一个与 cpuapp 关联的变体 ns(启用 TF-M)。因此,总共有 4 个板卡目标。
带版本的双板卡目标:nRF9161 DK 没有由 nRF9161 SiP 定义的 CPU 集群。有一个变体 ns。它还定义了两个版本:0.9.0(默认)和 0.7.0。

2. Kconfig.devacademyl3e1
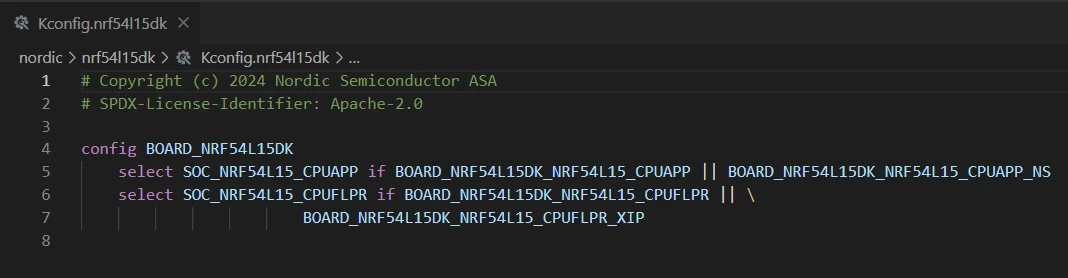
此文件有特定且重要的目的:它选择板卡使用的 SoC。通过这样做,它从架构到 SoC 拉入适当的硬件层文件。它还为板卡定义了一个 Kconfig 符号,这是以 BOARD_ 为前缀的板卡名称。
它包含 select 语句:
单板卡目标只需要 select
多核 SoC 或多 SoC 板卡需要 select … if 语句
以下是一些示例:
下面是我们将在练习 1 中开发的 devacademyl3e1(单板卡目标)的示例,它基于 nRF52833 QIAA。
config BOARD_DEVACADEMYL3E1
select SOC_NRF52833_QIAA这是 nRF54L15 DK(四板卡目标)的另一个示例。文件根据从构建系统触发的规范化板卡目标选择适当的 SoC 支持层。
3. devacademyl3e1.dts
板卡级设备树文件是用设备树格式编写的硬件描述。它表示板卡的原理图,详细说明其物理组件和连接。
它包括连接器和任何其他硬件组件,如 LED、按钮、传感器或通信外设(USB、BLE 控制器等)。内存分区也在此文件中完成。将大量依赖 nRF Connect for VS Code 扩展提供的自动化,包括设备树可视编辑器,来帮助填充此文件。
如果板卡有多个板卡限定符(即不同的板卡目标或变体),需要为每个板卡目标创建单独的板卡级设备树文件。可以将板卡级设备树文件结构化为多个文件,以提高可读性和可维护性。
4. devacademyl3e1-pinctrl.dtsi
此文件定义板卡外设的引脚映射。
如果板卡有多个板卡限定符(即不同的板卡目标或变体),需要为每个板卡目标创建单独的引脚映射文件。
可选文件
现在已经介绍了板卡层中的四个必需文件,让我们看看可选文件。
以下是包含所有必需文件、可选文件和特殊用例文件的板卡层:
boards/<vendor>/devacademyl3e1
├── board.yml
├── Kconfig.devacademyl3e1
├── devacademyl3e1_<qualifiers>.dts
├── devacademyl3e1_<qualifiers>-pinctrl.dtsi
├── devacademyl3e1_<qualifiers>_defconfig
├── Kconfig.defconfig
├── board.cmake # 用于闪存和调试
├── CMakeLists.txt # 特殊情况下需要
├── c_files.c # 特殊情况下需要
├── doc # 可选
│ ├── devacademyl3e1.png
│ └── index.rst
├── Kconfig # 可选,用于创建板卡 Kconfig 选项菜单
├── devacademyl3e1_<qualifiers>.yml # 测试运行器(Twister)可选
├── devacademyl3e1_<qualifiers>_<revision>.conf # 支持硬件版本需要
├── devacademyl3e1_<qualifiers>_<revision>.overlay # 支持硬件版本需要
└── dts # 可选
└── bindingsdevacademyl3e1_defconfig
devacademyl3e1_defconfig 文件是一个 Kconfig 片段,它按原样合并到为指定板卡构建的任何应用程序的最终构建中。
以下是工具生成的默认 devacademyl3e1_defconfig 文件(因 SoC 而异)。
# Copyright (c) 2024 Nordic Semiconductor ASA
# SPDX-License-Identifier: Apache-2.0
CONFIG_ARM_MPU=y
CONFIG_HW_STACK_PROTECTION=y除了默认的 Kconfig 符号外,需要手动包含希望为板卡构建的所有应用程序启用的任何其他 Kconfig 符号。
对于我们的板卡 DevAcademy L3E1,它是一个开发套件,所以我们想要添加 UART、RTT 和 GPIO 支持。因此,将附加以下内容:
# Enable RTT
CONFIG_USE_SEGGER_RTT=y
# enable GPIO
CONFIG_GPIO=y
# enable uart driver
CONFIG_SERIAL=y
# enable console
CONFIG_CONSOLE=y
CONFIG_UART_CONSOLE=y注意:<boardname>_defconfig 是按原样合并到为指定板卡构建的任何应用程序最终构建中的 Kconfig 片段,必须启用最低限度。应用程序配置(prj.conf)有责任配置所需的内容。
如果板卡有多个板卡限定符(即不同的板卡目标或变体),需要在文件名中指定限定符(如 devacademyl3e1__defconfig),以便在将某个限定符传递给构建系统时生效。
Kconfig.defconfig
Kconfig.defconfig 文件为 Kconfig 选项定义板卡特定的默认值。此文件的内容包装在对应于特定板卡目标的 if /endif 块中。此文件由工具自动生成,通过设置仅在为特定板卡构建时应用的默认值来补充 defconfig 文件。
让我们看看具有单个板卡目标 devacademyl3e1/nrf52833 的板卡示例。
if BOARD_DEVACADEMYL3E1
config BT_CTLR
default BT
endif # BOARD_DEVACADEMYL3E1CONFIG_BT_CTLR Kconfig 选项(启用对 SoC 原生蓝牙 LE 控制器实现的支持)仅在应用程序选择 CONFIG_BT 时启用。
如果板卡有多个板卡目标,可以为不同的板卡目标设置多个 if/endif 块。
例如,在 nRF54L15 DK 的 Kconfig.defconfig 文件中。
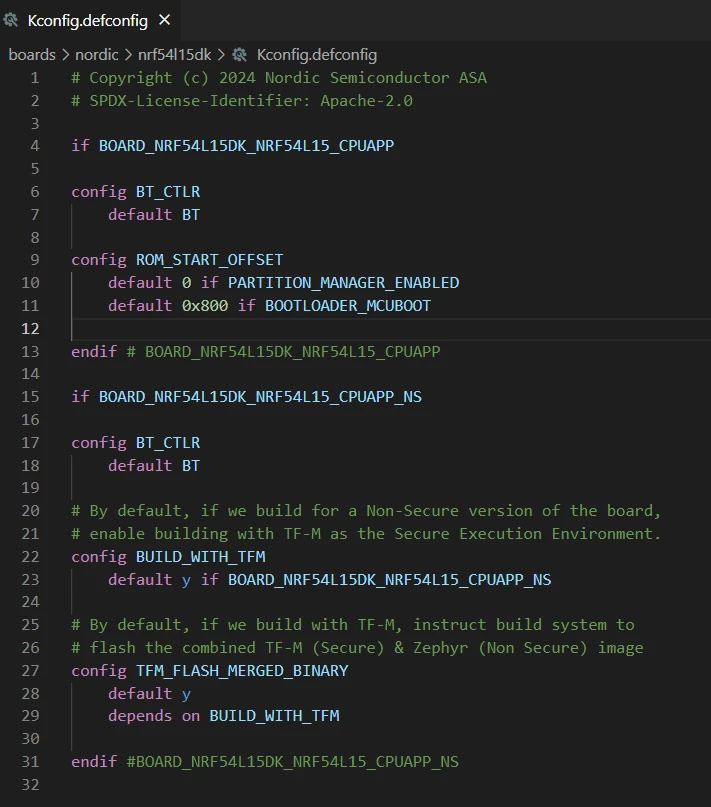
剩余的可选文件包括:
board.cmake:用于为板卡添加闪存和调试支持。
CMakeLists.txt:用于包含应在内核前或内核后执行的源文件。例如,如果硬件需要自定义多路复用器配置或需要以特定方式配置,可以添加到此文件中。这在 nRF52840 Dongle 中完成,其中 board_nrf52840dongle_nrf52840_init() 在内核之前的 PRE_KERNEL_1 执行。注意扩展不会创建 CMakeLists.txt 文件;如果需要,需要手动创建。
doc/index.rst, doc/devacademyl3e1.png:板卡的文档和图像,仅在将板卡贡献给 Zephyr 时需要。
Kconfig:允许创建特定于板卡的自定义 Kconfig 菜单。
devacademyl3e1.yml:包含 Zephyr 测试运行器(Twister)使用的杂项元数据的 YAML 文件。如果板卡有多个限定符,需要为每个限定符设置 .yml。
板卡版本
当为板卡创建新的硬件版本时,如更改原理图或新的 PCB 布局,不需要创建全新的板卡定义。相反,可以简单地在同一板卡文件夹中添加版本特定文件 devacademyl3e1_.conf 和 devacademyl3e1_.overlay,并更新 board.yml 以包含版本。
请记住,如果板卡有多个板卡限定符,需要为受影响的限定符指定 .conf 和 .overlay 文件,如 devacademyl3e1__.conf、devacademyl3e1__.overlay。
devacademyl3e1_.conf:此处指定的可选 Kconfig 设置将合并到板卡的默认 Kconfig 配置中。
devacademyl3e1_.overlay:可选设备树覆盖将与板卡级 devacademyl3e1.dts 设备树文件覆盖。
board.yml:revision: 属性控制 Zephyr 构建系统如何匹配用户为板卡构建应用程序时指定的 <board_name>@<revision> 字符串。
注意:创建新的自定义板卡时,总是一个好主意查看 SDK 定义的与自定义板卡相同 SoC/SiP 的板卡以获得灵感。SDK 中已经提供了大量开发套件、原型平台和参考设计,可以作为良好的起点。
它们在两个位置可用:<install_path>/zephyr/boards/nordic/ 和 <install_path>/nrf/boards/nordic/
参见 Zephyr 板卡移植指南。
总结
这篇教程教你如何为你自己设计的电路板(自定义板卡)创建一套“说明书”(配置文件),好让 nRF Connect SDK 这个开发工具能够认识并使用你的硬件。
核心思想拆解
想象一下:
你手里的物理电路板 (PCB) 是一个组装好的“乐高模型”。
而这篇教程教你写的“板卡定义文件”,就是拼装这个模型的“图纸和说明书”。
你的应用程序代码不会直接操作硬件,而是通过读取这份“说明书”来了解硬件长什么样,有什么功能。这样做最大的好处是可移植性:将来你换一块电路板,只需要换一份“说明书”就行了,应用程序代码基本不用改。
这篇教程主要讲了三件事:
1. 硬件是如何被“分层”描述的? (HWMv2 层次结构)
nRF Connect SDK 非常聪明,它不要求你从零开始描述所有东西。它把硬件描述分成了好几个层次,就像套娃一样。
最顶层:板卡 (Board)
- 这就是你唯一需要自己创建的“说明书”。你只需要描述你这块板子特有的东西,比如“我这块板子上有两个芯片,分别是 nRF9160 和 nRF52840”。
下面的所有层:SoC、CPU、架构等
这些都是 Nordic 和 Zephyr 官方已经为你准备好的“标准零件说明书”。
比如,你一旦在你的说明书里指定了使用
nRF9160这个芯片,SDK 就会自动把nRF91系列、Cortex-M33CPU、ARM架构等所有相关的标准信息全部包含进来。你完全不需要操心这些底层细节。
核心要点: 你只需要“搭积木”,告诉 SDK 你用了哪些“标准零件”(SoC),SDK 就会帮你处理好剩下的所有复杂细节。
2. 创建一份“说明书”需要哪些文件?
要为你自己的板卡创建一份最基本的“说明书”,你只需要准备 4 个必需文件:
board.yml(板卡的身份证)- 作用: 这是最核心的元数据文件。它记录了这块板卡叫什么名字、由哪个厂商制造、上面用了哪个/哪些 SoC。
Kconfig.boardname(芯片选择文件)- 作用: 它的任务很简单,就是根据你的选择,告诉编译系统:“嘿,这块板子用的是
nRF52833_QIAA这个型号的芯片,快去加载它的标准配置!”
- 作用: 它的任务很简单,就是根据你的选择,告诉编译系统:“嘿,这块板子用的是
boardname.dts(板卡的电路图)作用: 这是最重要的文件。它用一种叫“设备树”的文本格式,描述了板子上除了SoC之外的所有东西,比如:
连接了几个 LED 灯,分别接在哪个引脚上。
有几个按钮,接在哪个引脚上。
板子上外挂了什么传感器。
内存是如何划分的。
boardname-pinctrl.dtsi(引脚功能表)- 作用: 专门用来定义芯片的引脚具体用作什么功能(比如 P0.13 用作 UART 的 TX,P0.14 用作 RX 等)。它是上面
dts文件的补充。
- 作用: 专门用来定义芯片的引脚具体用作什么功能(比如 P0.13 用作 UART 的 TX,P0.14 用作 RX 等)。它是上面
核心要点: 你只需要创建这 4 个文件,就能定义一个最基本的自定义板卡。其他提到的文件都是可选的,用于更高级的功能(如默认配置、特殊初始化代码、调试等)。
3. 如何命名和使用你的板卡?
教程还花篇幅讲了命名规则,简单来说:
板卡名称 (
board_name): 给你的板卡起一个简单、唯一的内部代号,比如my_custom_board。板卡目标 (
board_target): 这是你编译时实际使用的完整名称。它可能更复杂,比如my_custom_board/nrf52833,用来告诉编译器不仅要用my_custom_board的配置,还要针对nrf52833这个核心来编译。如果你的板卡有多个核心,就会有多个板卡目标。
多核硬件与 TF-M 开发板文件
Nordic 的 SoC 产品线经历了一次重要的架构升级:
| 系列 | CPU | 架构 | 可编程核心数 | TrustZone |
|---|---|---|---|---|
| nRF52 | Cortex-M4 | Armv7-M | 1 | 否 |
| nRF54L | Cortex-M33 + Nordic FLPR | Armv8-M + RISC-V | 2 | 是 |
| nRF53 | Cortex-M33 | Armv8-M | 2 | 是 |
| nRF91 | Cortex-M33 | Armv8-M | 1 | 是 |
关键变化:从 Armv7-M 的 Cortex-M4 升级到 Armv8-M 的 Cortex-M33,最重要的是引入了 TrustZone 技术。
TrustZone:硬件级安全分离的守护者
Trusted Firmware-M (TF-M) 是专为 Arm M 系列架构设计的安全处理环境蓝图。把它想象成一个"安全管家"——它在芯片中划分出一个绝对安全的区域,专门保护敏感数据和代码。
TrustZone 的工作原理
TrustZone 技术在硬件层面强制实现了两个独立的执行环境:
安全处理环境 (SPE):运行 TF-M,拥有完整的系统访问权限
非安全处理环境 (NSPE):运行用户应用,受到安全环境的监管和保护
这就像在同一栋楼里设置了两个独立的安全区域:一个是银行金库(安全环境),一个是普通办公区(非安全环境)。金库有独立的门禁和监控,办公区的人无法直接访问金库资源。
两种构建策略的选择
基于 TrustZone 技术,我们有两种应用构建方式:
策略一:安全分离模式
构建目标:<board_target>/ns
应用运行在非安全环境中
TF-M 自动在安全环境中构建和运行
最终产生两个镜像:安全镜像 + 非安全镜像
两个镜像会被合并成一个完整的固件
策略二:无安全分离模式
构建目标:<board_target>
应用拥有完整的系统访问权限
构建单一镜像,无安全分离机制
nRF54L 系列:ARM + RISC-V 混合架构
这是最有趣的架构,集成了两种不同的处理器:
Cortex-M33 应用核心
构建目标:
<board_target>/cpuapp(TF-M 禁用)<board_target>/cpuapp/ns(TF-M 启用)
RISC-V 协处理器 (FLPR)
Fast Lightweight Peripheral Processor 专门处理时间关键任务:
构建目标:
<board_target>/cpuflpr(从 SRAM 运行,推荐方式)<board_target>/cpuflpr/xip(从 RRAM 运行)
重要提示:构建 FLPR 目标时,应用核心构建必须包含相应的覆盖配置来启用 FLPR 核心。
板级定义文件的 TF-M 配置
必需的四个关键文件
为支持 TF-M,自定义板级目录需要包含以下配置:
1. 元数据文件 board.yml
board:
name: devacademyl3e2
vendor: nordic
socs:
- name: nrf9151
variants:
- name: 'ns' # 非安全变体2. 统一的 Kconfig 配置文件
Kconfig.defconfig 需要检测构建目标并相应调整 Flash 配置:
if BOARD_DEVACADEMYL3E2_NRF9151 || BOARD_DEVACADEMYL3E2_NRF9151_NS
config FLASH_LOAD_SIZE
default $(dt_chosen_reg_size_hex,$(DT_CHOSEN_Z_CODE_PARTITION))
depends on BOARD_NRF9151DK_NRF9151 && TRUSTED_EXECUTION_SECURE
if BOARD_NRF9151DK_NRF9151_NS
config FLASH_LOAD_OFFSET
default $(dt_chosen_reg_addr_hex,$(DT_CHOSEN_Z_CODE_PARTITION))
endif
endif3. 两个独立的默认配置文件
安全版本 (devacademyl3e2_nrf9151_defconfig):
CONFIG_ARM_TRUSTZONE_M=y # 启用 TrustZone非安全版本 (devacademyl3e2_nrf9151_ns_defconfig):
CONFIG_ARM_TRUSTZONE_M=y # 启用 TrustZone API
CONFIG_TRUSTED_EXECUTION_NONSECURE=y # 标识为非安全固件4. 设备树文件配置
公共配置文件 (devacademyl3e2_nrf9151_common.dtsi):
包含引脚控制配置
包含 Nordic 默认分区配置:
#include <common/nordic/nrf91xx_partition.dtsi>
安全版本设备树 (devacademyl3e2_nrf9151.dts):
/ {
chosen {
zephyr,sram = &sram0_s; // 安全 SRAM
zephyr,flash = &flash0; // 完整 Flash
zephyr,code-partition = &slot0_partition;
};
};非安全版本设备树 (devacademyl3e2_nrf9151_ns.dts):
/ {
chosen {
zephyr,sram = &sram0_ns_app; // 非安全 SRAM
zephyr,flash = &flash0;
zephyr,code-partition = &slot0_ns_partition; // 非安全分区
};
};
/* 禁用 TF-M 默认使用的 UART1 */
&uart1 {
status = "disabled";
};内存分区的安全考量
Flash 布局策略
安全镜像:位于
flash0起始位置(或 MCUboot 的slot0)非安全镜像:位于专门的
slot0_ns分区
SRAM 分配原则
安全域:使用
sram0_s非安全域:使用
sram0_ns
重要提醒:在使用多镜像构建时,设备树中的分区信息会被分区管理器覆盖。这部分内容将在后续的引导加载器和 DFU/FOTA 课程中深入讨论。
通过这样的配置架构,开发者可以在享受 TrustZone 硬件安全特性的同时,灵活地针对不同的应用场景选择合适的安全策略,实现既安全又高效的嵌入式系统开发。
自定义单核开发板
单核 Nordic SoC 的自定义板级支持创建——以 nRF54L15 为例,通过 nRF Connect SDK 的板级配置工具,从零开始构建一个功能完整的自定义板级定义,涵盖 GPIO、UART、I2C、SPI 等外设的完整配置流程。
实战背景:从开发板到产品板
设计假设
我们要为一个基于 nRF54L15 DK 的简化版硬件创建板级支持。这个新板子保持了 DK 的核心功能,但移除了 Arduino 接口——可以理解为一个"紧凑版开发板"。
创建流程:九步完成自定义板级支持
第一步:建立工作目录
创建独立的板级定义根目录 xiao_nrf,这样可以将自定义板级文件与 SDK 原生文件隔离管理。

第二步:使用 SDK 创建工具
nRF Connect SDK 提供了图形化的板级创建向导:
关键配置参数
板级名称(Board name):
xiao_nrf54l15(构建目标标识符)描述名称(Description):
XIAO nRF54L15(人类可读名称)厂商名称(Vendor name):
seeed(无空格的公司标识)SoC 型号(SoC):
nRF54L15-QFAA(精确的芯片型号和封装)板级根目录(Board root):指向第一步创建的目录
重要提示:SoC 型号选择必须与实际硬件完全匹配,包括具体的封装变体(QIAA、CIAA 等)。
第三步:配置构建系统搜索路径
方法一:VS Code 扩展设置
通过 File -> Preferences -> Settings -> Extensions -> nRF Connect -> Board Roots 添加自定义板级根目录。

方法二:构建时指定
另一种方法是在构建时指定。通过向构建系统传递 -DBOARD_ROOT 参数来指定自定义开发板信息的位置。
west build -b <board_target> -- -DBOARD_ROOT=<path_to_boards>核心配置文件详解
Kconfig 默认配置(xiao_nrf54l15_nrf54l15_cpuapp_defconfig)
这个文件定义了所有基于该板级构建的应用的默认配置:
# 启用 Zephyr 的串行驱动程序框架,这是使用 UART、UARTE 等外设的基础
CONFIG_SERIAL=y
# --- 控制台相关配置 ---
# 启用控制台子系统,允许内核打印日志、调试信息等
CONFIG_CONSOLE=y
# 将控制台的输出重定向到 UART 串口
CONFIG_UART_CONSOLE=y
# --- 电源管理相关配置 ---
# 启用设备级电源管理,允许系统在空闲时关闭未使用的外设以节省功耗
CONFIG_PM_DEVICE=y
# 启用 Nordic nrfx HAL 中的电源驱动,用于管理芯片的低功耗模式和稳压器
CONFIG_NRFX_POWER=y
# 启用 GPIO(通用输入/输出)驱动程序框架,是操作引脚所必需的
CONFIG_GPIO=y
# --- CPU 内存与堆栈保护 ---
# 启用 ARM 的 MPU(内存保护单元),用于划分内存区域并设置访问权限,是实现堆栈保护等高级功能的基础
CONFIG_ARM_MPU=y
# 启用硬件堆栈保护。利用 MPU 机制来检测堆栈溢出,防止程序跑飞
CONFIG_HW_STACK_PROTECTION=y
# 禁用空指针异常检测。不使用特定的机制来捕获对 NULL 指针的访问
CONFIG_NULL_POINTER_EXCEPTION_DETECTION_NONE=y
# --- 缓存管理 ---
# 启用缓存管理 API,允许软件对 CPU 缓存进行操作(如刷新、失效)
CONFIG_CACHE_MANAGEMENT=y
# 启用对外部缓存的支持(如果硬件存在)
CONFIG_EXTERNAL_CACHE=y
# 使用 Nordic 的 GRTC(全局实时计数器)作为系统定时器(SysCounter)的源
CONFIG_NRF_GRTC_START_SYSCOUNTER=y
# --- 稳压器(Regulator)配置 ---
# 启用稳压器驱动框架,用于控制板载的 LDO 或 DC/DC 等电源芯片
CONFIG_REGULATOR=y
# 设置固定稳压器的初始化优先级为 45(数值越小,优先级越高,越早被初始化)
CONFIG_REGULATOR_FIXED_INIT_PRIORITY=45设备树配置策略
基础设施启用(xiao_nrf54l15_nrf54l15_cpuapp.dts)
&clock {
status = "okay";
};
&uart20 {
status = "okay";
};
&uart21 {
status = "okay";
};
&i2c22 {
status = "okay";
};
&gpio1 {
status = "okay";
};
&gpio2 {
status = "okay";
};
&gpiote20 {
status = "okay";
};
&gpiote30 {
status = "okay";
};LED 配置(xiao_nrf54l15_common.dtsi)
LEDs 连接到 GND,因此需要配置为 GPIO_ACTIVE_HIGH:
leds {
compatible = "gpio-leds";
led0: led_0 {
gpios = <&gpio2 0 GPIO_ACTIVE_HIGH>;
label = "LED 0";
};
};按键配置(带上拉电阻)
按键连接到地,需要内部上拉电阻和低电平有效:
buttons: buttons {
compatible = "gpio-keys";
usr_btn: usr-btn {
gpios = <&gpio0 0 (GPIO_PULL_UP | GPIO_ACTIVE_LOW)>;
label = "USR";
zephyr,code = <INPUT_KEY_ENTER>;
};
};外设配置的分层架构
UART 串口配置
主设备树文件配置(xiao_nrf54l15_common.dtsi)
&uart20 {
current-speed = <115200>;
pinctrl-0 = <&uart20_default>;
pinctrl-1 = <&uart20_sleep>;
pinctrl-names = "default", "sleep";
};引脚控制文件(xiao_nrf54l15-pinctrl.dtsi)
&pinctrl {
/omit-if-no-ref/ uart20_default: uart20_default {
group1 {
psels = <NRF_PSEL(UART_TX, 1, 9)>;
};
group2 {
psels = <NRF_PSEL(UART_RX, 1, 8)>;
bias-pull-up;
};
};系统选择节点配置(xiao_nrf54l15_nrf54l15_cpuapp.dts)
chosen {
zephyr,code-partition = &slot0_partition;
zephyr,sram = &cpuapp_sram;
zephyr,flash = &cpuapp_rram;
zephyr,console = &uart20;
zephyr,shell-uart = &uart20;
nordic,rpc-uart = &uart20;
};设计思想:
chosen节点的属性用于配置系统级或子系统级的默认值,通过DT_CHOSEN()宏被各个软件模块引用。
I2C 配置示例
&i2c22 {
pinctrl-0 = <&i2c22_default>;
pinctrl-1 = <&i2c22_sleep>;
pinctrl-names = "default", "sleep";
clock-frequency = <400000>;
};SPI 配置示例
&spi00 {
pinctrl-0 = <&spi00_default>;
pinctrl-1 = <&spi00_sleep>;
pinctrl-names = "default", "sleep";
};样本兼容性:别名配置的重要性
为什么需要别名?(xiao_nrf54l15_common.dtsi)
nRF Connect SDK 和 Zephyr OS 的示例代码使用固定的设备树别名来引用硬件资源。正确的别名配置确保现有示例无需修改即可在自定义板上运行。
aliases {
led0 = &led0;
buttons = &buttons;
dmic20 = &pdm20;
sw0 = &usr_btn;
watchdog0 = &wdt31;
};验证测试:五个关键功能点
1. 串口控制台测试
目标:验证 UART 和调试输出
方法:构建 Hello World 示例
期望输出:
*** Booting nRF Connect SDK ***
Hello World! seeed/xiao_nrf54l152. GPIO 交互测试
目标:验证按键和 LED 功能
方法:构建 Button 示例
期望行为:按下按键 1,LED 1 点亮
3. PWM 功能测试
目标:验证 PWM 驱动和 LED 调光
方法:构建 PWM LED 示例
期望行为:LED 渐明渐暗的呼吸效果
4. 蓝牙功能测试
目标:验证无线通信能力
方法:构建 BLE UART Service 示例
注意:蓝牙节点在 SoC 设备树中已默认启用
5. 总线通信测试
目标:验证 I2C 和 SPI 接口(需要外部组件)
设计原则总结
配置分离原则
功能配置:在主设备树文件中启用外设和设置参数
引脚映射:在独立的 pinctrl 文件中定义引脚分配
默认选项:在 Kconfig 文件中设置构建默认值
兼容性考虑
别名完整性:确保所有常用别名都有对应的实际节点
引脚冲突避免:仔细检查引脚分配,避免多个外设使用同一引脚
电气特性匹配:根据硬件连接方式正确配置上拉、下拉和极性
通过这样系统化的配置流程,可以快速创建一个功能完整、高度兼容的自定义板级支持,为后续的产品开发提供可靠的硬件抽象基础。
脉宽调制(PWM)
脉冲宽度调制(PWM)是一种通过数字控制信号来操控模拟设备的常用技术。利用这种类模拟的数字信号,我们可以控制从电机、照明到电源控制与转换等多种设备。本课程将讲解 PWM 控制的基础知识,并深入探讨如何通过改变信号的有效占空比,以及在 nRF Connect SDK 的 overlay 文件中添加不同兼容节点,来配置 PWM API 以实现不同功能。
脉冲宽度调制(PWM)
PWM(脉宽调制)技术精髓——通过精确控制脉冲信号的宽度比例来调节平均功率输出,实现从数字信号到模拟效果的转换,广泛应用于电机控制、LED 调光和信号生成等场景。
PWM 的本质:时间就是力量
什么是 PWM?
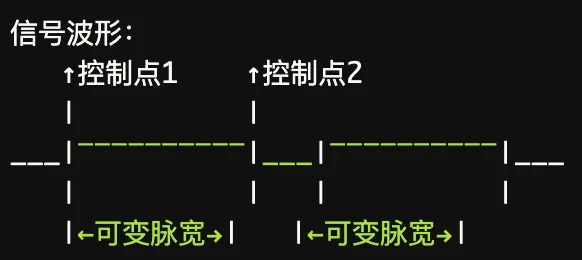
想象一下老式的电灯调光开关——不是通过改变电压来调光,而是通过极快地开关电源来控制亮度。PWM 就是这个原理的数字化实现:通过控制信号在"高电平"和"低电平"之间切换的时间比例,来调节设备接收到的平均功率。
关键参数理解
周期 (Period) = 高电平时间 + 低电平时间
频率 (Frequency) = 1 / 周期
幅度 (Amplitude) = 最大电压 - 最小电压
占空比 (Duty Cycle) = 高电平时间 / 周期 × 100%形象比喻:如果把 PWM 比作一个会眨眼的灯泡,那么"占空比"就是眨眼周期中"睁眼时间"的比例。占空比越高,平均亮度越亮;占空比越低,平均亮度越暗。
占空比:功率控制的核心
占空比的实际效果
| 占空比 | 信号状态 | 平均输出效果 | 应用场景 |
|---|---|---|---|
| 0% | 始终低电平 | 完全关闭 | LED 熄灭 |
| 25% | 1/4 时间高电平 | 25% 功率 | LED 暗光 |
| 50% | 1/2 时间高电平 | 50% 功率 | LED 中等亮度 |
| 75% | 3/4 时间高电平 | 75% 功率 | LED 较亮 |
| 100% | 始终高电平 | 满功率 | LED 最亮 |
数学本质
平均电压 = 最大电压 × 占空比
例如:在 3.3V 系统中,50% 占空比产生的平均电压为 3.3V × 0.5 = 1.65V
Nordic nRF52840 的 PWM 架构优势
硬件特性概览
nRF52840 PWM 模块提供了强大且灵活的信号生成能力:
4 个独立通道:每个通道可以独立配置占空比和极性
独立控制:各通道间互不影响,可同时驱动多个不同设备
灵活极性:支持正极性和反极性输出
精确计数器:基于向上或向下计数器实现精确时序控制
多通道应用示例
// 同时控制四个 LED 的不同亮度
PWM_Channel_0: 25% 占空比 -> LED1 暗光
PWM_Channel_1: 50% 占空比 -> LED2 中等亮度
PWM_Channel_2: 75% 占空比 -> LED3 较亮
PWM_Channel_3: 100% 占空比 -> LED4 最亮PWM 输出模式:单边控制 vs 双边控制
单边控制 PWM
特点:只能控制上升沿或下降沿的位置
适用场景:大多数基础应用,如 LED 调光、电机速度控制

双边控制 PWM
特点:可以同时控制上升沿和下降沿的位置
适用场景:需要精确波形控制的高级应用,如音频信号生成、精密电机控制
Zephyr PWM API
在 nRF Connect SDK 中,有两种访问 PWM 模块的方式:
Zephyr PWM API:高层抽象接口,跨平台兼容
nrfx PWM 驱动:Nordic 专用底层驱动,性能更优但移植性差
设计哲学:除非有特殊的性能或功能需求,建议优先使用 Zephyr API。它提供了标准化的接口,使代码更易维护和移植。
三步启用 PWM 功能
第一步:启用驱动支持
Kconfig 配置(prj.conf):
CONFIG_PWM=y头文件包含:
#include <zephyr/drivers/pwm.h>第二步:设备树配置
如果目标设备未在板级设备树中定义,需要通过设备树覆盖文件进行配置。
第三步:代码初始化和操作
设备树配置的三个关键步骤
步骤一:定义设备实例
以舵机控制为例,创建一个 PWM 驱动的舵机节点:
/ {
servo: servo {
compatible = "pwm-servo";
pwms = <&pwm0 1 PWM_MSEC(20) PWM_POLARITY_NORMAL>;
min-pulse = <PWM_USEC(700)>; // 最小脉宽 700μs
max-pulse = <PWM_USEC(2500)>; // 最大脉宽 2500μs
};
};配置参数解析:
&pwm0 1:使用 PWM0 外设的通道 1PWM_MSEC(20):20ms 周期(50Hz,舵机标准频率)PWM_POLARITY_NORMAL:正极性输出
步骤二:定义引脚配置节点
创建自定义的引脚控制配置,指定 PWM 输出使用的具体 GPIO:
&pinctrl {
pwm0_default_custom: pwm0_default_custom {
group1 {
psels = <NRF_PSEL(PWM_OUT0, 0, 13)>; // P0.13 引脚
nordic,invert; // 信号反相
};
};
};步骤三:关联配置到 PWM 实例
将新的引脚配置应用到 PWM0 实例,并移除不需要的睡眠状态:
&pwm0 {
pinctrl-0 = <&pwm0_default_custom>;
/delete-property/ pinctrl-1; // 删除睡眠状态配置
pinctrl-names = "default";
};API 编程接口详解
核心数据结构:pwm_dt_spec
这个结构体包含了 PWM 设备的完整信息:
struct pwm_dt_spec {
const struct device *dev; // PWM 设备指针
uint32_t channel; // PWM 通道号
uint32_t period; // PWM 周期
pwm_flags_t flags; // PWM 标志位
};设备初始化方法
基础初始化
static const struct pwm_dt_spec pwm_servo = PWM_DT_SPEC_GET(DT_NODELABEL(servo));其他初始化选项
按名称初始化:
PWM_DT_SPEC_GET_BY_NAME(node, name)按索引初始化:
PWM_DT_SPEC_GET_BY_IDX(node, idx)
设备就绪验证
在使用 PWM 设备前,必须验证其初始化状态:
if (!pwm_is_ready_dt(&pwm_servo)) {
printk("Error: PWM device is not ready\n");
return -ENODEV;
}PWM 控制 API 函数
完整控制:pwm_set_dt()
当需要同时设置周期和脉宽时使用:
int pwm_set_dt(const struct pwm_dt_spec *spec,
uint32_t period,
uint32_t pulse);应用场景:
需要动态改变 PWM 频率的应用
音频信号生成(不同音调需要不同频率)
脉宽控制:pwm_set_pulse_dt()
当周期固定,只需调整脉宽时使用:
int pwm_set_pulse_dt(const struct pwm_dt_spec *spec,
uint32_t pulse);应用场景:
LED 调光(频率固定,只调节亮度)
舵机控制(50Hz 固定,调节角度)
实际应用示例
舵机角度控制
// 舵机通常使用 50Hz(20ms 周期)
// 脉宽范围:700μs(0°) 到 2500μs(180°)
static const struct pwm_dt_spec servo = PWM_DT_SPEC_GET(DT_NODELABEL(servo));
void set_servo_angle(uint16_t angle_degrees) {
if (angle_degrees > 180) angle_degrees = 180;
// 线性映射:0°-180° -> 700μs-2500μs
uint32_t pulse_width = 700 + (angle_degrees * 1800) / 180;
int ret = pwm_set_pulse_dt(&servo, PWM_USEC(pulse_width));
if (ret < 0) {
printk("Error setting servo angle: %d\n", ret);
}
}LED 呼吸灯效果
static const struct pwm_dt_spec pwm_led = PWM_DT_SPEC_GET(DT_NODELABEL(pwm_led0));
void breathing_led_effect(void) {
uint32_t period = PWM_MSEC(20); // 50Hz
// 渐亮
for (uint32_t pulse = 0; pulse <= period; pulse += period/100) {
pwm_set_dt(&pwm_led, period, pulse);
k_msleep(10);
}
// 渐暗
for (uint32_t pulse = period; pulse > 0; pulse -= period/100) {
pwm_set_dt(&pwm_led, period, pulse);
k_msleep(10);
}
}串行外设接口(SPI)
串行外设接口(SPI)是一种用于板级短距离通信的串行协议,特别适用于嵌入式系统。SPI 通信采用主从模式,多个从设备可连接在同一总线上,主设备可随时启用任一从设备进行通信。该接口因高速传输特性而广受欢迎,仅需 4 根线即可实现全双工通信。本课程将讲解 SPI 通信基础原理,并深入探讨 Zephyr SPI API 的应用。
SPI 接口
SPI(Serial Peripheral Interface,串行外设接口)是嵌入式系统中一种重要的短距离串行通信协议。相比 I2C,SPI 采用了更高的时钟频率,因此能够支持更快的数据传输速率,这使得它在需要高速数据交换的场景中备受青睐。
SPI 的四线架构:各司其职的信号线
标准的 SPI 接口采用四线制设计,每根线都有其特定的职责:
SCLK(Serial Clock,串行时钟):这是由主设备产生的同步时钟信号,就像乐队指挥的节拍器一样,确保所有设备按照统一的节奏进行数据传输
MOSI(Master-Out-Slave-In,主出从入):从主设备流向从设备的数据线,可以理解为主设备的"发言通道"
MISO(Master-In-Slave-Out,主入从出):从从设备流向主设备的数据线,这是从设备的"回应通道"
CS(Chip Select,片选信号):主设备用来选择特定从设备的控制信号,通常为低电平有效
需要注意的是,不同厂商的器件可能会使用不同的信号名称,但功能本质相同。在实际应用中,务必查阅具体器件的数据手册来确认片选信号的有效电平。
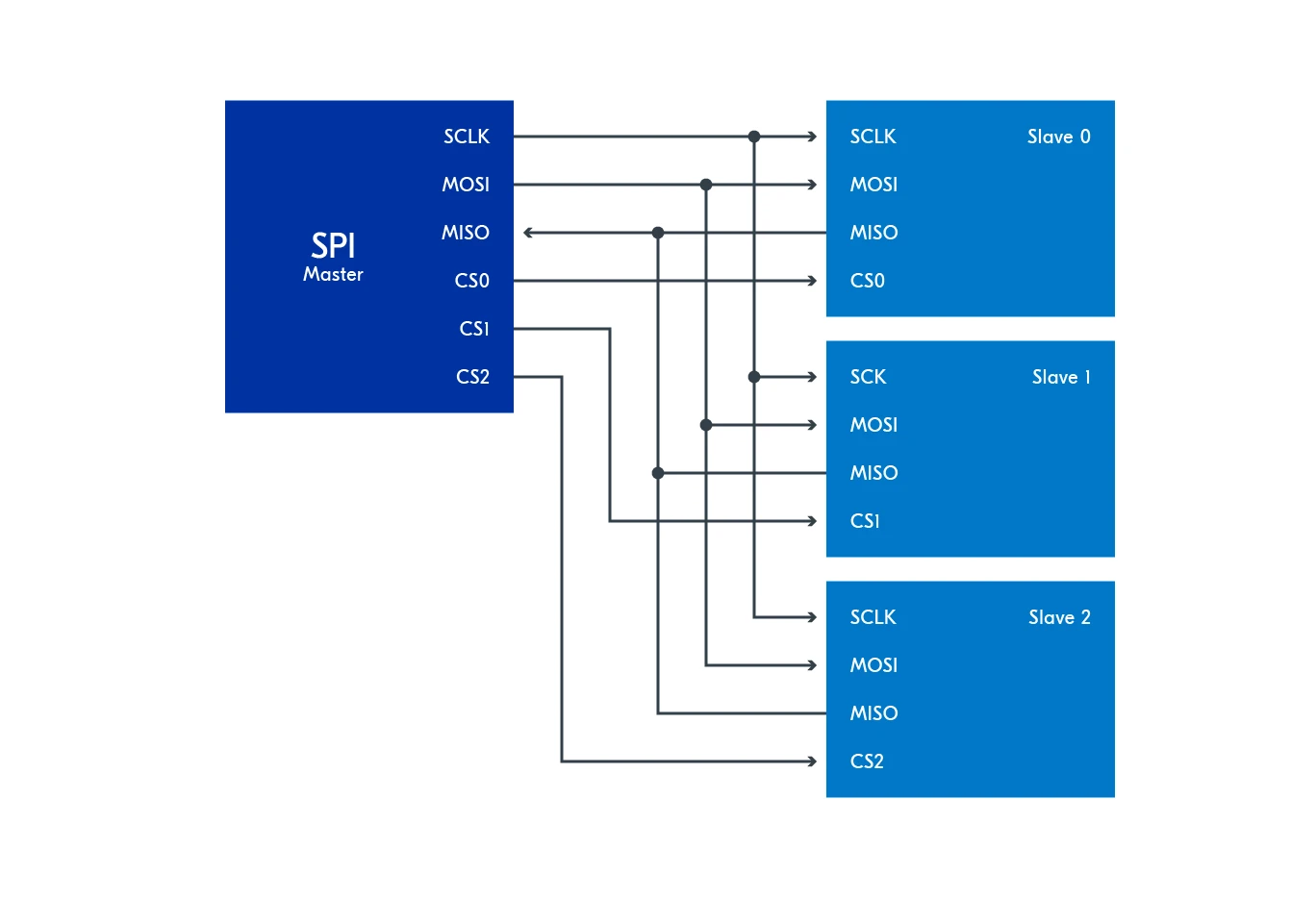
主从架构:一对多的通信模式
SPI 采用主从(Master-Slave)架构,一个主设备可以连接多个从设备。在这种架构中:
SCLK、MOSI 和 MISO 三条线在所有设备间共享,形成一条公共的数据总线
每个从设备都有独立的 CS 信号线,这样主设备就能精确地选择与哪个从设备通信
任何时刻只能有一个从设备处于活跃状态,这是通过激活对应的 CS 信号来实现的
这种设计就像一个会议室,所有人都能听到发言(共享的数据线),但只有被点名的人才能发言(通过 CS 选择)。
Nordic 芯片的 SPI 实现:多种接口选择
Nordic 系列芯片提供了多种 SPI 接口实现,每种都有其特定的应用场景:
SPI 接口类型
SPI:基础的 SPI 主设备接口,适用于简单的通信需求
SPIM:集成了 EasyDMA 功能的 SPI 主设备接口,这是一个亮点功能
SPIS:SPI 从设备接口(本文暂不涉及)
EasyDMA 的优势
EasyDMA(直接内存访问) 是 SPIM 接口的核心特性。它的作用类似于一个专职的数据搬运工:
解放 CPU:数据传输过程中,CPU 无需持续监督,可以去处理其他任务
提高效率:特别适合大批量数据传输场景
减少中断负担:降低了频繁中断对系统性能的影响
内部架构:缓冲机制与引脚配置
在 nRF 系列芯片中,SPI 的内部实现有以下特点:
双缓冲机制
SPI 从设备使用 TXD(发送) 和 RXD(接收) 缓冲区,并且这些缓冲区都采用了双缓冲设计。这种设计的好处在于:
减少数据中断:当一个缓冲区在传输数据时,另一个可以准备下一批数据
提高传输连续性:最大程度地保证数据流的平滑性
片选信号的独立控制
有一个重要的实现细节需要注意:SPI 主设备不直接支持片选信号的自动控制。这意味着:
CPU 必须使用独立的 GPIO 引脚来控制 CS 信号
开发者需要在软件中手动管理片选的时序
这种设计提供了更大的灵活性,但也增加了编程的复杂性
SPI 模式:时钟极性与相位的四种组合
SPI 支持四种不同的工作模式(模式 0-3),这些模式由两个关键参数决定:
核心参数
CPOL(Clock Polarity,时钟极性):决定片选激活时时钟信号的初始状态
CPOL=0:时钟起始于逻辑低电平
CPOL=1:时钟起始于逻辑高电平
CPHA(Clock Phase,时钟相位):决定数据在哪个时钟边沿被采样
当 CPOL=0 时:CPHA=0 表示上升沿采样,CPHA=1 表示下降沿采样
当 CPOL=1 时:CPHA=0 表示下降沿采样,CPHA=1 表示上升沿采样
实际应用考虑
在选择 SPI 模式时,从设备的规格说明书是唯一的权威依据。不同的传感器或外设可能支持不同的 SPI 模式,主设备必须配置为与从设备兼容的模式才能确保正常通信。
这就像两个人对话时需要使用相同的语言和语调一样,SPI 的主从设备也必须在时钟时序上"说同一种语言"。
通过理解这些基础概念和实现细节,开发者就能更好地在实际项目中配置和使用 SPI 接口,实现可靠的高速数据通信。
Zephyr SPI API
在实际开发中,nRF Connect SDK 集成了 Zephyr SPI API,为我们提供了操作 SPI 外设的标准接口。虽然针对特定外设(如传感器、TFT 屏幕)通常有专门的高级 API 和图形库(如 LVGL),但理解底层的 SPI 原始事务处理对于深入掌握嵌入式通信至关重要。
这些高级 API 最终都会调用底层的 SPI 通信接口,因此掌握 Zephyr SPI API 将为我们打下坚实的基础。
驱动程序启用配置
Kconfig 配置
首先需要在 prj.conf 文件中启用 SPI 驱动:
CONFIG_SPI=y头文件包含
在源代码中包含 SPI API 的头文件:
#include <zephyr/drivers/spi.h>设备树配置详解
设备树(Devicetree)的配置是 SPI 通信的基础,我们需要通过 overlay 文件来定义 SPI 从设备的各种属性。
Overlay 文件的作用
Overlay 文件就像是硬件连接的"蓝图",它定义了:
使用哪个 SPI 控制器
设备绑定信息
设备状态
MOSI、MISO 和 SCLK 引脚配置
从设备的特殊属性(如最大时钟频率)
基础 Overlay 示例
以下是一个典型的 overlay 配置示例:
&spi1 {
compatible = "nordic,nrf-spi";
status = "okay";
cs-gpios = <&gpio0 18 GPIO_ACTIVE_LOW>;
pinctrl-0 = <&spi1_default>;
pinctrl-1 = <&spi1_sleep>;
pinctrl-names = "default", "sleep";
gendev: gendev@0 {
compatible = "vnd,spi-device";
reg = <0>;
spi-max-frequency = <1600000>;
label = "GenDev";
};
};配置要素解析
SPI 控制器配置
compatible = "nordic,nrf-spi":指定使用 Nordic 的 SPI 驱动status = "okay":激活该 SPI 接口cs-gpios = <&gpio0 18 GPIO_ACTIVE_LOW>:定义片选信号使用 GPIO0 的第 18 号引脚,且为低电平有效
引脚控制配置
pinctrl-0和pinctrl-1:分别定义活动模式和睡眠模式下的引脚配置这里的具体引脚映射配置在实际项目中会在完整的 overlay 文件中详细定义
从设备节点配置
gendev: gendev@0:定义了一个名为gendev的通用 SPI 设备reg = <0>:该设备在 SPI 总线上的地址spi-max-frequency = <1600000>:设置最大通信频率为 1.6MHz
设备初始化流程
SPI 设备结构体
Zephyr SPI API 使用专门的结构体 spi_dt_spec 来管理 SPI 设备:
struct spi_dt_spec {
const struct device *bus; // SPI 设备指针
struct spi_config config; // 从设备特定配置
};其中 spi_config 结构体包含:
frequency:SPI 通信的时钟频率
operation:操作标志位(具体标志位定义请参考 API 文档)
slave:从设备在总线上的编号
cs:GPIO 片选线配置
设备结构体获取
使用 SPI_DT_SPEC_GET() 函数来获取设备结构体:
#define SPIOP SPI_WORD_SET(8) | SPI_TRANSFER_MSB
struct spi_dt_spec spispec = SPI_DT_SPEC_GET(DT_NODELABEL(gendev), SPIOP, 0);这里的操作配置 SPIOP 定义了:
SPI_WORD_SET(8):设置 SPI 字长为 8 位SPI_TRANSFER_MSB:指定最高位优先传输(MSB First)
设备就绪检查
在使用 SPI 设备之前,必须检查设备是否就绪:
err = spi_is_ready_dt(&spispec);
if (!err) {
LOG_ERR("Error: SPI device is not ready, err: %d", err);
return 0;
}SPI 数据读写操作
Zephyr SPI API 提供了三个核心函数用于数据传输:
函数功能对比
spi_read_dt():仅执行读操作spi_write_dt():仅执行写操作spi_transceive_dt():同时执行读写操作
这三个函数的签名都很相似,主要区别在于缓冲区参数的数量。
双向传输示例
以下是使用 spi_transceive_dt() 进行双向数据传输的完整示例:
uint8_t tx_buffer = 0x88;
struct spi_buf tx_spi_buf = {.buf = (void *)&tx_buffer, .len = 1};
struct spi_buf_set tx_spi_buf_set = {.buffers = &tx_spi_buf, .count = 1};
struct spi_buf rx_spi_bufs = {.buf = data, .len = size};
struct spi_buf_set rx_spi_buf_set = {.buffers = &rx_spi_bufs, .count = 1};
err = spi_transceive_dt(&spispec, &tx_spi_buf_set, &rx_spi_buf_set);
if (err < 0) {
LOG_ERR("spi_transceive_dt() failed, err: %d", err);
return err;
}缓冲区结构解析
单个缓冲区(struct spi_buf)
buf:指向数据缓冲区的指针len:缓冲区长度
缓冲区集合(struct spi_buf_set)
buffers:指向缓冲区数组的指针count:缓冲区的数量
这种设计允许我们在一次传输中使用多个不连续的缓冲区,提供了很大的灵活性。
使用建议:对于简单的单缓冲区传输,只需要设置
count = 1;对于复杂的多缓冲区场景,可以构建缓冲区数组来实现更高效的数据传输。
通过这种结构化的 API 设计,Zephyr 为 SPI 通信提供了既灵活又易用的编程接口,无论是简单的传感器读取还是复杂的多设备通信,都能得到良好的支持。
BME280 传感器 SPI 通信实战
本实验将通过实际操作 BME280 环境传感器,深入理解 SPI 通信的工作原理和编程实现。BME280 是一款能够同时测量温度、压力和湿度的高精度传感器,支持 I2C 和 SPI 两种通信方式。我们选择 SPI 方式进行通信,以便更好地掌握这种高速串行接口的使用技巧。
BME280 传感器硬件连接
引脚功能说明
BME280 分线板提供了六个硬件连接引脚:
| 引脚名称 | 功能描述 |
|---|---|
| VCC | 电源正极 |
| GND | 电源负极 |
| SCL (SCK) | SPI 时钟信号 |
| SDA (SDI) | 串行数据输入(主设备到从设备) |
| CSB | 片选信号(低电平有效) |
| SDO | 串行数据输出(从设备到主设备) |
重要警告:当 VDD 未连接或关闭时,SPI 接口引脚绝不能处于逻辑高电平,否则可能永久损坏设备。在配置 SPI 从设备时,务必确保引脚连接正确、连接牢固,设备功能正常且供电稳定。
传感器工作模式
BME280 提供三种工作模式:
睡眠模式:上电后的默认模式,功耗最低
强制模式:执行一次测量后返回睡眠模式
正常模式:连续测量模式
传感器上电后默认处于睡眠模式,因此在读取数据前必须配置模式位,将其切换到正常模式或强制模式。
寄存器映射与通信协议
寄存器结构
BME280 的所有通信都通过读写 8 位宽寄存器 来完成。其内存映射包含以下几类寄存器:
保留寄存器:不应修改
校准数据寄存器:只读,出厂时固化的校准参数
控制寄存器:读写,用于控制传感器设置
数据寄存器:只读,存储传感器测量结果
状态和芯片 ID 寄存器:只读
复位寄存器:只写
数据格式与读取策略
传感器提供的原始数据格式:
压力值:20 位无符号数据
温度值:20 位无符号数据
湿度值:16 位无符号数据
由于寄存器都是 8 位宽度,需要进行多字节读取操作,然后将字节正确组合成完整的数值。
推荐做法:使用突发读取模式而非逐个寄存器读取。温度和压力数据可从 0xF7 读取到 0xFC;如需包含湿度数据,则从 0xF7 读取到 0xFE。
补偿算法机制
从寄存器读取的是未补偿的原始数据,需要使用出厂校准参数进行补偿计算,才能得到实际的温度、压力和湿度值。这些校准参数存储在传感器的非易失性存储器中,每个传感器都有唯一的校准数据。
校准参数的读取和组合示例:
从 0x88 读取字节 a,从 0x89 读取字节 b
dig_T1 = (b << 8) | aSPI 兼容性
BME280 兼容 SPI 模式 0(CPOL=0, CPHA=0)和 SPI 模式 3(CPOL=1, CPHA=1)。
项目实现步骤
步骤 1:驱动程序启用
1.1 Kconfig 配置
在 prj.conf 文件中添加必要的配置:
CONFIG_GPIO=y
CONFIG_SPI=yTF-M 构建目标注意事项:如果使用包含 TF-M 的构建目标(如 nrfxxxxdk_nrfxxxx_ns),需要禁用 TF-M 的日志功能,因为某些 SoC 中 UART 和 SPIM 外设可能共享相同的基地址。添加以下配置:
CONFIG_TFM_SECURE_UART=n
CONFIG_TFM_LOG_LEVEL_SILENCE=y
1.2 头文件包含
在 main.c 顶部添加必要的头文件:
#include <zephyr/device.h>
#include <zephyr/devicetree.h>
#include <zephyr/drivers/gpio.h>
#include <zephyr/drivers/spi.h>步骤 2:设备树 Overlay 配置
2.1 SPI 从设备配置
在 boards 目录中创建对应开发板的 overlay 文件(如 nrf54l15dk_nrf54l15.overlay):
/* uart20 is being used for serial communication, so use spi21*/
&spi21 {
compatible = "nordic,nrf-spim";
status = "okay";
pinctrl-0 = <&spi21_default>;
pinctrl-1 = <&spi21_sleep>;
pinctrl-names = "default", "sleep";
cs-gpios = <&gpio1 8 GPIO_ACTIVE_LOW>;
bme280: bme280@0 {
compatible = "bosch,bme280";
reg = <0>;
spi-max-frequency = <1000000>;
};
};配置说明:
compatible = "nordic,nrf-spim":指定使用 Nordic 的 SPIM 驱动(nRF52 除外,由于勘误表 58 的限制)cs-gpios:配置片选引脚为低电平有效spi-max-frequency:设置最大通信频率为 1MHzcompatible = "bosch,bme280":指定设备类型,对应bosch,bme280-spi.yaml绑定文件
2.2 引脚控制配置
定义 SPI 引脚的具体映射:
&pinctrl {
spi21_default: spi21_default {
group1 {
psels = <NRF_PSEL(SPIM_SCK, 1, 11)>,
<NRF_PSEL(SPIM_MOSI, 1, 13)>,
<NRF_PSEL(SPIM_MISO, 1, 14)>;
};
};
spi21_sleep: spi21_sleep {
group1 {
psels = <NRF_PSEL(SPIM_SCK, 1, 11)>,
<NRF_PSEL(SPIM_MOSI, 1, 13)>,
<NRF_PSEL(SPIM_MISO, 1, 14)>;
low-power-enable;
};
};
};步骤 3:设备结构体获取
使用 Zephyr API 获取 SPI 设备结构体:
#define SPIOP SPI_WORD_SET(8) | SPI_TRANSFER_MSB
struct spi_dt_spec spispec = SPI_DT_SPEC_GET(DT_NODELABEL(bme280), SPIOP, 0);这里的操作配置指定:
SPI_WORD_SET(8):8 位数据宽度
SPI_TRANSFER_MSB:最高位优先传输
步骤 4:寄存器读取函数实现
4.1 缓冲区配置
uint8_t tx_buffer = reg;
struct spi_buf tx_spi_buf = {.buf = (void *)&tx_buffer, .len = 1};
struct spi_buf_set tx_spi_buf_set = {.buffers = &tx_spi_buf, .count = 1};
struct spi_buf rx_spi_bufs = {.buf = data, .len = size};
struct spi_buf_set rx_spi_buf_set = {.buffers = &rx_spi_bufs, .count = 1};4.2 SPI 事务处理
err = spi_transceive_dt(&spispec, &tx_spi_buf_set, &rx_spi_buf_set);
if (err < 0) {
LOG_ERR("spi_transceive_dt() failed, err: %d", err);
return err;
}重要细节:
spi_transceive_dt()先写后读,第一个接收字节是虚拟字节。因此读取 N 个字节需要设置size = N+1,并忽略data[0]。
步骤 5:寄存器写入函数实现
5.1 写入缓冲区配置
uint8_t tx_buf[] = {(reg & 0x7F), value}; // MSB=0 表示写操作
struct spi_buf tx_spi_buf = {.buf = tx_buf, .len = sizeof(tx_buf)};
struct spi_buf_set tx_spi_buf_set = {.buffers = &tx_spi_buf, .count = 1};5.2 执行写入操作
err = spi_write_dt(&spispec, &tx_spi_buf_set);
if (err < 0) {
LOG_ERR("spi_write_dt() failed, err %d", err);
return err;
}步骤 6-8:数据处理函数分析
项目中包含三个关键的数据处理函数:
bme_calibrationdata():读取校准参数,构建补偿算法所需的参数表bme_print_registers():逐个读取并打印寄存器内容,用于调试验证补偿函数:
bme280_compensate_temp()、bme280_compensate_press()、bme280_compensate_humidity()使用校准参数将原始数据转换为实际物理量
步骤 9:传感器数据采样
9.1 突发读取配置
uint8_t regs[] = {PRESSMSB, PRESSLSB, PRESSXLSB,
TEMPMSB, TEMPLSB, TEMPXLSB,
HUMMSB, HUMLSB, DUMMY};
uint8_t readbuf[sizeof(regs)];9.2 缓冲区设置与数据传输
struct spi_buf tx_spi_buf = {.buf = (void *)®s, .len = sizeof(regs)};
struct spi_buf_set tx_spi_buf_set = {.buffers = &tx_spi_buf, .count = 1};
struct spi_buf rx_spi_bufs = {.buf = readbuf, .len = sizeof(regs)};
struct spi_buf_set rx_spi_buffer_set = {.buffers = &rx_spi_bufs, .count = 1};
err = spi_transceive_dt(&spispec, &tx_spi_buf_set, &rx_spi_buffer_set);步骤 10:主函数实现
10.1 设备就绪检查
err = spi_is_ready_dt(&spispec);
if (!err) {
LOG_ERR("Error: SPI device is not ready, err: %d", err);
return 0;
}10.2 校准数据读取
bme_calibrationdata();10.3 传感器配置
bme_write_reg(CTRLHUM, 0x04); // 湿度控制:4x 过采样
bme_write_reg(CTRLMEAS, 0x93); // 测量控制:正常模式,8x 过采样
bme_print_registers();10.4 连续采样循环
while (1) {
bme_read_sample();
gpio_pin_toggle_dt(&ledspec);
k_msleep(DELAY_VALUES);
}硬件连接与测试
连接方案
以 nRF52840 DK 为例的连接映射:
| 传感器引脚 | DK 引脚 | 颜色标识 |
|---|---|---|
| SCL (时钟) | P0.28 | 橙色 |
| SDA (MOSI) | P0.29 | 黄色 |
| CSB (片选) | P0.30 | 绿色 |
| SDO (MISO) | P0.31 | 蓝色 |
| VCC | VDD | 红色 |
| GND | GND | 黑色 |
预期输出结果
成功运行后,终端将显示:
*** Booting nRF Connect SDK ***
<inf> Lesson5_Exercise1: Reading from calibration registers:
<inf> Lesson5_Exercise1: Reg[0x88] 2 Bytes read: Param T1 = 28784
<inf> Lesson5_Exercise1: Reg[0x8a] 2 Bytes read: Param T2 = 26968
...
<inf> Lesson5_Exercise1: Continuously read sensor samples:
<inf> Lesson5_Exercise1: Temperature: comp = 23.85 C
<inf> Lesson5_Exercise1: Pressure: comp = 93709.79 Pa
<inf> Lesson5_Exercise1: Humidity: comp = 23.92 %RH数据单位转换
根据数据手册,补偿后的数值需要进行单位换算:
温度:补偿值 ÷ 100(如 2462 = 24.62°C)
压力:补偿值 ÷ 256(如 25634778 = 100,135 Pa)
湿度:补偿值 ÷ 1024(如 2023 = 1.97% RH)
通过这个完整的实验项目,我们不仅掌握了 SPI 通信的编程技巧,还深入理解了传感器校准、数据补偿等嵌入式系统中的重要概念。这为后续更复杂的 SPI 设备开发奠定了坚实基础。
模数转换器(ADC)
ADC 代表模数转换器。模数转换器用于将模拟信号(如连续的模拟电压)转换为数字格式,使处理器能够读取该信号,并根据读取的数值采取相应操作。
嵌入式系统经常需要测量物理参数,这些参数通常以连续(模拟)形式而非数字形式呈现。常见的物理参数包括温度、光强和压力等。通常传感器内部会集成模数转换器,可直接输出物理参数的数字形式,但并非所有传感器都具备这一功能。在这种情况下,我们就需要使用 SoC 和 SiP 内部的模数转换器,将物理参数从模拟形式转换为数字形式。
Nordic 设备中的 ADC 模拟数字转换器
模拟数字转换器(ADC)是现代嵌入式系统中不可或缺的组件,它的作用就像一位"翻译官",将连续变化的模拟信号(如电压、温度、光强等)转换成处理器能够理解的数字信号。这使得微控制器能够基于来自传感器的模拟输入做出智能决策。
Nordic 芯片中的 SAADC 架构
Nordic 设备采用的是 逐次逼近型 ADC(SAADC),这种设计在微控制器和嵌入式系统中广受欢迎,主要得益于其高效的设计和低功耗特性。
SAADC 的核心组成
SAADC 的心脏是 SAR 核心,它包含三个关键组件:
数模转换器(DAC):生成参考电压
逐次逼近寄存器(SAR):控制转换过程的逻辑
比较器:比较输入信号与参考电压
除了 SAR 核心,还有采样保持电路和其他系统接口电路,共同构成完整的 ADC 系统。
工作原理:二分查找的艺术
SAADC 采用二分查找算法来确定模拟信号的数字表示。它通过逐步逼近的方式,在所有可能的量化级别中进行二分搜索,最终收敛到准确的数字输出值。
想象一下猜数字游戏:如果要在 1-16 之间猜一个数字,最高效的方法就是先猜 8,根据"大了"或"小了"的反馈,再猜 4 或 12,如此反复。4 位 ADC 正是用这种方式工作的。
SAADC 核心概念深度解析
采样率(采样频率)
采样率是 ADC 性能的重要指标,它决定了系统捕获模拟信号变化的能力。
模拟信号在固定时间间隔(采样间隔)内被采样,采样间隔的倒数就是采样率。采样将连续时间信号转换为离散时间信号,这意味着数字值只在特定时刻更新,记录的值本质上是"历史数据"(即使可能只有 2μs 的延迟)。
奈奎斯特-香农采样定理:为了准确重构原始信号,采样率必须至少是被采样模拟信号最高频率分量的两倍。
最大采样频率的限制:
fSAMPLE < 1/(tACQ + tconv)其中:
tACQ:采集时间
tconv:转换时间
不同 Nordic 芯片系列的性能对比:
nRF52/nRF53/nRF91 系列:最大采样率 200ksps(5μs 采样间隔)
nRF54 系列:更高性能
12 位分辨率:250ksps
10 位分辨率:2Msps
转换时间(tconv)
转换时间是指将采样保持电路中的样本转换为数字值所需的时间。SAADC 通过逐次逼近算法工作,转换时间就是完成这个逼近过程所需的时间。
转换时间与选择的分辨率直接相关:
更高分辨率 = 更长转换时间
更低分辨率 = 更短转换时间
典型转换时间:
nRF52/nRF53/nRF91 系列:约 2 微秒
nRF54 系列:最短 0.5 微秒起
采集时间(tACQ)
采集时间(约 3-30 微秒)直接影响采样频率,是系统性能优化的关键参数。
采样保持电路负责捕获连续变化的模拟信号电压,并在指定的最短时间内将其保持在恒定水平。可以将其理解为内部电容器连接到输入模拟信号所需的时间。
准确捕获和保持输入模拟信号所需的时间取决于源输入阻抗。输入阻抗越高,需要的采集时间越长。
分辨率:精度的衡量标准
分辨率是指 SAADC 能够检测并表示为离散数字值的输入信号最小可分辨变化,通常以位数表示。
支持的分辨率:
nRF52/nRF53/nRF91 系列:
基础:8/10/12 位
过采样:可达 14 位
nRF54 系列:10/12/14 位
过采样技术:
优点:提高信噪比(SNR)
限制:不能改善积分非线性(INL)或差分非线性(DNL)
性能权衡:更高分辨率意味着更精确的测量,但代价是更长的转换时间。
输入模式:单端 vs 差分
内部结构说明
值得注意的是,ADC 内部始终是差分模拟数字转换器。默认配置为单端模式时,负输入在内部短接到地。
单端模式(SE)
在单端模式下,假设 ADC 的内部地与被测电压所参考的外部地相同。这种模式实现简单,适用于大多数基础应用。
差分模式(Diff)
差分模式虽然增加了接口电路的复杂性,但使 SAADC 对地弹跳和噪声更具抗性,适用于高精度或强干扰环境的应用。
灵活的通道配置
模拟输入可以配置为:
8 个单端输入
4 个差分输入
单端和差分的组合
每个通道可以选择以下输入源:
AIN0 到 AIN7 引脚:外部模拟输入
VDD 引脚:电源电压监测
VDDHDIV5:高电压监测(如果芯片支持)
增益控制:扩展测量范围
Nordic 芯片的 SAADC 支持以下增益选项:1/6、1/5、1/4、1/3、1/2、1、2、4。
增益可以改变 ADC 的有效输入范围,为不同应用场景提供灵活性。
参考电压:定义测量基准
两种参考电压选项
内部参考电压
- ADC 核心输入范围:±0.6V
VDD 作为参考电压
- ADC 核心输入范围:±VDD/4
输入范围计算
通过增益块可以改变 ADC 的有效输入范围:
输入范围 = (±0.6V 或 ±VDD/4) / 增益实际应用示例
示例 1:VDD 参考 + 单端输入 + 1/4 增益
输入范围 = (VDD/4) / (1/4) = VDD这种配置允许测量 0 到 VDD 的电压范围。
示例 2:内部参考 + 单端输入 + 1/6 增益
输入范围 = (0.6V) / (1/6) = 3.6V这种配置允许测量 0 到 3.6V 的电压范围。
重要限制:AIN0-AIN7 输入不能超过 VDD 电压。
总结
通过对 Nordic 芯片 SAADC 外设核心特性的深入理解,我们掌握了模拟数字转换的基本原理和关键参数。这些概念为后续的实际应用开发奠定了坚实的理论基础。
在实际项目中,需要根据具体的应用需求,在采样速度、分辨率、功耗和精度之间找到最佳平衡点。更详细的技术规格和配置参数可以在相应 SoC/SiP 的产品规格书(数据手册)中找到。
ADC API 选择指南:Zephyr API vs nrfx SAADC 驱动
在 nRF Connect SDK 中,与 SAADC 外设交互有两种方式,这就像选择不同的"工具箱"来完成同一项工作。每种方式都有其独特的优势和适用场景。
API 选择的核心原则
Zephyr ADC API 是官方推荐的首选方案,适用于大多数标准应用场景。只有当 Zephyr API 无法满足特殊需求时,才考虑使用 nrfx SAADC API。
这种设计哲学体现了嵌入式开发中一个重要的权衡:通用性与专用性的平衡。
Zephyr API 的核心优势
高度可移植性:一次编写,处处运行
Zephyr 驱动程序的设计理念是平台无关性。这意味着你的代码就像是用"通用语言"编写的,无论切换到不同的芯片型号、芯片系列,甚至不同的芯片厂商,Zephyr API 都能无缝工作。
相比之下,nrfx SAADC 驱动 API 是 Nordic 专有的,移植到新平台时可能需要大幅修改代码。这就像使用专用工具与通用工具的区别——专用工具功能强大但局限性大,通用工具虽然可能不那么精细,但适应性强。
集成 Zephyr 电源管理:自动化的智能省电
nrfx 驱动设计为操作系统无关,这是其优势也是局限。它们不集成任何特定 RTOS 的电源管理功能,这意味着如果使用 nrfx 驱动,电源管理必须在应用层手动处理。
而 Zephyr 驱动已经深度集成了 Zephyr 的自动电源管理功能。系统会智能地管理外设的电源状态,开发者无需手动干预,大大降低了开发复杂度和出错概率。
nrfx SAADC 的特殊用途
虽然 Zephyr API 适用于大多数场景,但在某些高性能或精确控制的应用中,nrfx SAADC API 成为必要的选择。
高采样率应用:突破软件触发的瓶颈
性能挑战
某些应用需要对模拟输入进行极高速采样。Nordic 芯片支持的最大采样率为:
nRF52/nRF53/nRF91 系列:200ksps(5μs 间隔)
未来芯片:可能支持更高采样率
如果每个样本都通过软件触发,将导致 CPU 频繁中断和唤醒,严重影响系统性能。在如此高的采样率下,软件触发变得不现实,因为它会占用大量 CPU 时间,影响其他任务的执行。
精确采样间隔:硬件级时序保证
时序精度要求
在单核 SoC 上运行协议栈等高优先级任务时,如果需要在非常精确的时间间隔或特定时刻采样模拟输入,软件触发可能无法提供足够的精度。
当其他中断或线程具有比 ADC 采样线程更高的优先级时,采样触发会被延迟,直到高优先级任务完成。这种不确定性在要求严格时序的应用中是不可接受的。
硬件解决方案:(D)PPI 的威力
(D)PPI:无 CPU 干预的硬件连接
数字可编程外设互连(DPPI/PPI)是 Nordic 芯片的独有硬件特性,它实现了纯硬件级的外设间信号传递。当事件发生时,可以直接触发任务,完全无需 CPU 参与。
由于信号传递在硬件层面实现,不存在中断延迟,也不会被其他高优先级任务干扰。这种机制为高性能 ADC 应用提供了完美的解决方案。
重要提示:(D)PPI 是 Nordic 半导体的专有硬件特性,目前 Zephyr 驱动 API 中尚未提供支持。这是选择 nrfx SAADC API 的一个重要技术原因。
组合使用策略
在 nRF Connect SDK 中,可以将 nrfx SAADC 驱动与 nrfx (D)PPI 驱动结合使用,完美解决上述高性能应用场景的需求。
nrfx SAADC 驱动的工作模式
简单模式:基础采样需求
简单模式允许从每个请求的通道获取单个样本,支持:
阻塞方式:函数调用直到转换完成才返回
非阻塞方式:函数立即返回,通过回调处理结果
软件触发:通过函数调用启动采样
这种模式适用于偶发性的测量需求,如定期检查电池电压或温度。
高级模式:连续高性能采样
高级模式支持任意长度的双缓冲转换,提供更强大的功能:
触发方式:
内部定时器触发:精确控制采样间隔
外部触发:通过 TIMER 和 PPI/DPPI 实现硬件触发
缓冲机制:
双缓冲支持:一个缓冲区在采集数据时,另一个可以被处理
外部缓冲区切换:通过 PPI 通道控制,实现真正的连续采样,无 CPU 延迟
这种模式特别适合需要连续、高速数据采集的应用,如音频处理或高频信号监测。
实际应用的决策框架
何时选择 Zephyr API
标准采样需求:采样率适中,时序要求不严格
跨平台兼容性:项目可能迁移到其他平台
开发效率优先:希望减少底层硬件管理的复杂度
电源管理重要:需要自动化的电源优化
何时选择 nrfx SAADC API
高采样率应用:接近或达到硬件极限的采样速度
精确时序控制:毫秒级甚至微秒级的时序精度要求
连续采样需求:需要无间断的数据流
硬件特性利用:需要使用 (D)PPI 等 Nordic 专有功能
开发建议:在项目初期,优先尝试 Zephyr API。只有当遇到性能瓶颈或特殊功能需求时,再考虑切换到 nrfx API。这种渐进式的方法既保证了开发效率,又确保了最终的性能要求。
学习路径规划
在后续的练习中,我们将深入探索 nrfx SAADC API 的具体使用方法,学习如何在 nRF Connect SDK 中充分发挥硬件的潜力,为高性能 ADC 应用打下坚实基础。
Zephyr ADC API 实战:电压测量的完整实现
本实验将带您深入学习如何使用 Zephyr ADC API 与 Nordic 设备的 SAADC 外设进行交互,实现精确的模拟电压测量功能。
项目配置与环境准备
步骤 1:ADC 驱动启用
在 prj.conf 文件中启用 ADC 功能:
CONFIG_ADC=y这一行配置告诉编译系统包含 ADC 相关的驱动代码和 API 接口。
设备树配置:定义硬件连接
设备树配置是整个项目的核心,它定义了软件如何与硬件进行交互。
步骤 2.1:创建 Overlay 文件
在 l6_e1/boards 目录中,将 overlay 文件重命名为对应开发板的名称,例如 nrf52840dk_nrf52840.overlay。
步骤 2.2:定义用户节点
在设备树 overlay 文件中创建用户节点,指定要使用的 ADC 通道:
/ {
zephyr,user {
io-channels = <&adc 0>;
};
};配置说明:
zephyr,user:Zephyr 系统的用户自定义节点io-channels = <&adc 0>:引用 ADC 的第 0 通道
多通道扩展:如需使用多个通道,可以用逗号分隔:
<&adc 0>, <&adc 1>, <&adc 2>, <&adc 7>
步骤 2.3:详细的 ADC 通道配置
在根节点外部添加完整的 ADC 配置:
&adc {
#address-cells = <1>;
#size-cells = <0>;
status = "okay";
channel@0 {
reg = <0>;
zephyr,gain = "ADC_GAIN_1_6";
zephyr,reference = "ADC_REF_INTERNAL";
zephyr,acquisition-time = <ADC_ACQ_TIME_DEFAULT>;
zephyr,input-positive = <NRF_SAADC_AIN0>;
zephyr,resolution = <12>;
};
};关键配置参数详解
增益设置(zephyr,gain)
ADC_GAIN_1_6 表示读取值将乘以 1/6 的增益。Nordic SAADC 支持的增益选项:1/6、1/5、1/4、1/3、1/2、1、2、4。
nRF54L15 特殊配置:该 SoC 使用
ADC_GAIN_1_4增益和 14 位分辨率。
参考电压(zephyr,reference)
ADC_REF_INTERNAL 指定使用内部 +0.6V 参考电压,这是最常用的配置选择。
采集时间(zephyr,acquisition-time)
ADC_ACQ_TIME_DEFAULT 使用硬件默认值(10μs),适用于大多数应用场景。
模拟输入(zephyr,input-positive)
NRF_SAADC_AIN0 选择 AIN0 作为正输入。由于未指定 input-negative 属性,系统自动配置为单端模式(负端内部连接到 GND)。
重要的引脚映射表
不同 Nordic SoC 的 AIN 引脚映射:
| SoC/SiP | AIN0 | AIN1 | AIN2 | AIN3 | AIN4 | AIN5 | AIN6 | AIN7 |
|---|---|---|---|---|---|---|---|---|
| nRF52833 | P0.02 | P0.03 | P0.04 | P0.05 | P0.28 | P0.29 | P0.30 | P0.31 |
| nRF5340 | P0.04 | P0.05 | P0.06 | P0.07 | P0.25 | P0.26 | P0.27 | P0.28 |
| nRF9160 | P0.13 | P0.14 | P0.15 | P0.16 | P0.17 | P0.18 | P0.19 | P0.20 |
注意事项:不要将开发板 PCB 上标记的 Arduino 模拟输入(A0-A5)与 SAADC 输入(AIN0-AIN7)混淆,它们是完全不同的概念。
内部电压测量选项
除了外部模拟输入,还可以测量内部电压:
NRF_SAADC_VDD:测量 VDD 电压NRF_SAADC_VDDHDIV5:测量 VDDH/5 电压
软件实现:ADC 操作的核心代码
步骤 3:设备结构体获取
3.1 包含头文件
#include <zephyr/drivers/adc.h>3.2 定义 ADC 通道变量
static const struct adc_dt_spec adc_channel = ADC_DT_SPEC_GET(DT_PATH(zephyr_user));ADC_DT_SPEC_GET() 宏从设备树中获取在索引 0 位置定义的 io-channels 配置。
3.3 设备就绪验证
if (!adc_is_ready_dt(&adc_channel)) {
LOG_ERR("ADC controller device %s not ready", adc_channel.dev->name);
return 0;
}这一步确保 SAADC 外设在使用前已经正确初始化。
3.4 通道设置
err = adc_channel_setup_dt(&adc_channel);
if (err < 0) {
LOG_ERR("Could not setup channel #%d (%d)", 0, err);
return 0;
}根据设备树 overlay 文件中的配置参数设置 ADC 通道。
步骤 4:采样序列配置
4.1 定义采样缓冲区和序列结构
int16_t buf;
struct adc_sequence sequence = {
.buffer = &buf,
.buffer_size = sizeof(buf), // 注意:这是字节大小,不是样本数量
// .calibrate = true, // 可选的校准功能
};缓冲区设计说明:
buffer:指向存储 ADC 采样结果的缓冲区buffer_size:缓冲区的字节大小,而非样本数量calibrate:可选的自动校准功能
4.2 序列初始化
err = adc_sequence_init_dt(&adc_channel, &sequence);
if (err < 0) {
LOG_ERR("Could not initialize sequence");
return 0;
}这个函数根据设备树配置自动填充序列结构的其他参数。
数据采集与处理
步骤 5:执行 ADC 读取
err = adc_read(adc_channel.dev, &sequence);
if (err < 0) {
LOG_ERR("Could not read (%d)", err);
continue;
}adc_read() 函数执行实际的模拟数字转换,将结果存储在预定义的缓冲区中。
步骤 6:原始值到电压的转换
int32_t val_mv = buf; // 从缓冲区获取原始值
err = adc_raw_to_millivolts_dt(&adc_channel, &val_mv);
if (err < 0) {
LOG_WRN(" (value in mV not available)\n");
} else {
LOG_INF(" = %d mV", val_mv);
}转换机制解析:
adc_raw_to_millivolts_dt()基于设备树中的参数(增益、参考电压、分辨率)自动计算实际电压值如果转换不支持,函数会返回错误,但这并不影响原始数据的有效性
测试与验证
步骤 7-8:硬件连接
连接方案选择:
专用电源:使用实验室电源或电池
PPK II 套件:精确的可变电压源
简单连线:将 AIN0 连接到 VDD 或 GND
nRF54L15 DK 特殊说明:连接 P1.11 到 GND/VDDIO。默认 VDDIO 电压为 1.8V,可通过 nRF Connect for Desktop 中的 Board Configurator 调整。
预期测试结果
连接到 VDD 时:
[00:00:00.252,075] <inf> Lesson6_Exercise1: ADC reading[0]: Raw: 3401 = 2989 mV
[00:00:01.252,227] <inf> Lesson6_Exercise1: ADC reading[1]: Raw: 3404 = 2991 mV连接到 GND 时:
[00:00:00.252,075] <inf> Lesson6_Exercise1: ADC reading[0]: Raw: 2 = 1 mV
[00:00:01.252,227] <inf> Lesson6_Exercise1: ADC reading[1]: Raw: -1 = -1 mV测量精度分析
连接到 GND 时出现的小电压值(1-7mV)和偶发负值是单端模式下的正常现象,主要由以下因素造成:
噪声干扰:环境电磁干扰和电路噪声
单端模式特性:负端接地但仍受噪声影响
量化误差:ADC 固有的数字化误差
高级应用技巧
PPK II 作为可变电压源
如果您拥有 PPK II,可以将其用作精密可变电压源:
连接 PPK II 的 VOUT 到模拟输入引脚
连接 PPK II 的 GND 到 DK GND
在 nRF Connect for Desktop 中打开 Power Profiler 应用
使用 Source meter 功能设置所需的供电电压
安全注意事项
电压限制:模拟输入不得超过 SoC/SiP 的内部电压
高电压测量:如需测量超过内部电压的信号,必须使用适当的分压电路
共地要求:确保被测模拟输入与 DK 共享相同的地
通过这个完整的实验,您不仅掌握了 Zephyr ADC API 的使用方法,还深入理解了 ADC 配置、数据处理和测量精度等关键概念,为后续更复杂的模拟信号处理项目奠定了坚实基础。
nrfx SAADC 简单模式实战:软件定时器驱动的电压监测
本实验将深入探索 nrfx SAADC 驱动的简单模式,学习如何使用软件定时器定期测量电压源(如电池)。这种方法在需要精确控制 SAADC 底层功能时特别有用。
项目配置基础
步骤 1:启用 SAADC 驱动
在 prj.conf 配置文件中启用 nrfx SAADC 驱动:
CONFIG_NRFX_SAADC=y这与之前使用的 Zephyr ADC API 不同,直接启用了 Nordic 的底层硬件抽象层驱动。
步骤 2:包含头文件
#include <nrfx_saadc.h>这个头文件提供了对 SAADC 外设的直接访问接口。
核心对象声明与配置
步骤 3:关键数据结构定义
3.1 SAADC 通道配置结构
针对不同芯片的引脚配置方式:
// nRF54L15 特殊配置
#define NRF_SAADC_INPUT_AIN4 NRF_PIN_PORT_TO_PIN_NUMBER(11U, 1)
#define SAADC_INPUT_PIN NRF_SAADC_INPUT_AIN4
// 通用配置(其他 Nordic 芯片)
// #define SAADC_INPUT_PIN NRF_SAADC_INPUT_AIN0
static nrfx_saadc_channel_t channel = NRFX_SAADC_DEFAULT_CHANNEL_SE(SAADC_INPUT_PIN, 0);配置说明:
NRFX_SAADC_DEFAULT_CHANNEL_SE:创建单端输入的默认通道配置nRF54L15 使用 AIN4:因为 AIN0 对应的 GPIO 默认被 UARTE 实例占用
其他芯片使用 AIN0:传统的模拟输入引脚
硬件连接提示:将电池正极连接到指定的模拟输入引脚(AIN0 或 AIN4),负极连接到 GND。如果没有电池,也可以用跳线将模拟输入连接到 VDD。
3.2 采样缓冲区声明
static int16_t sample;定义存储 SAADC 采样值的缓冲区变量。
软件定时器系统
步骤 4:定时采样机制
4.1 定义采样间隔
#define BATTERY_SAMPLE_INTERVAL_MS 2000设置每 2 秒进行一次电池电压采样。
4.2 定时器实例定义
static void battery_sample_timer_handler(struct k_timer * timer); // 前向声明
K_TIMER_DEFINE(battery_sample_timer, battery_sample_timer_handler, NULL);设计模式解析:
K_TIMER_DEFINE:Zephyr 的定时器定义宏battery_sample_timer_handler:定时器到期时的回调函数前向声明:确保编译器在定义定时器时能找到回调函数
SAADC 驱动详细配置
步骤 5:完整的驱动初始化流程
5.1 中断连接配置
IRQ_CONNECT(DT_IRQN(DT_NODELABEL(adc)),
DT_IRQ(DT_NODELABEL(adc), priority),
nrfx_isr, nrfx_saadc_irq_handler, 0);代码解析:
DT_IRQN:从设备树获取 ADC 中断号DT_IRQ:从设备树获取 ADC 中断优先级nrfx_saadc_irq_handler:Nordic 官方的 SAADC 中断处理函数
这种方法提高了代码的可移植性,因为中断配置参数来自设备树而非硬编码。
5.2 驱动实例初始化
nrfx_err_t err = nrfx_saadc_init(DT_IRQ(DT_NODELABEL(adc), priority));
if (err != NRFX_SUCCESS) {
printk("nrfx_saadc_init error: %08x", err);
return;
}使用设备树中定义的优先级初始化 SAADC 驱动实例。
5.3 通道增益调整
channel.channel_config.gain = NRF_SAADC_GAIN1_4;
err = nrfx_saadc_channels_config(&channel, 1);
if (err != NRFX_SUCCESS) {
printk("nrfx_saadc_channels_config error: %08x", err);
return;
}增益配置说明:
默认增益(GAIN=1):对于电源电压测量来说太高
NRF_SAADC_GAIN1_4:1/4 增益,适合测量接近 VDD 的电压
nRF54L15 差异:该芯片的增益步进与之前的 SoC 不同
5.4 简单模式配置
err = nrfx_saadc_simple_mode_set(BIT(0),
NRF_SAADC_RESOLUTION_12BIT,
NRF_SAADC_OVERSAMPLE_DISABLED,
NULL);
if (err != NRFX_SUCCESS) {
printk("nrfx_saadc_simple_mode_set error: %08x", err);
return;
}参数详解:
BIT(0):启用通道 0NRF_SAADC_RESOLUTION_12BIT:12 位分辨率NRF_SAADC_OVERSAMPLE_DISABLED:关闭过采样NULL:阻塞模式(同步操作)
温度补偿提示:SAADC 具有温度相关的偏移。建议在第一次采样前进行偏移校准,然后在环境温度变化超过 5-10°C 时定期校准。使用
nrfx_saadc_offset_calibrate()函数进行校准。
5.5 缓冲区设置
err = nrfx_saadc_buffer_set(&sample, 1);
if (err != NRFX_SUCCESS) {
printk("nrfx_saadc_buffer_set error: %08x", err);
return;
}由于采样间隔较长且只采样一个通道,单样本缓冲区足够使用。
步骤 6:启动定期采样
k_timer_start(&battery_sample_timer, K_NO_WAIT, K_MSEC(BATTERY_SAMPLE_INTERVAL_MS));在 configure_saadc() 函数末尾启动定时器,开始周期性采样。
采样处理实现
步骤 7:定时器回调函数
7.1 函数框架
void battery_sample_timer_handler(struct k_timer *timer)
{
/* Step 7.2 - 触发采样 */
/* STEP 7.3 - 计算并打印电压 */
}7.2 触发采样操作
nrfx_err_t err = nrfx_saadc_mode_trigger();
if (err != NRFX_SUCCESS) {
printk("nrfx_saadc_mode_trigger error: %08x", err);
return;
}由于之前配置为阻塞模式,当函数返回时采样已经完成。
7.3 电压计算与显示
针对不同芯片的计算公式:
// nRF54L15 专用公式
int battery_voltage = ((900*4) * sample) / ((1<<12));
// 其他 Nordic 芯片公式(基于 0.6V 内部参考)
// int battery_voltage = ((600*6) * sample) / ((1<<12));
printk("SAADC sample: %d\n", sample);
printk("Battery Voltage: %d mV\n", battery_voltage);公式推导说明:
对于 nRF54L15:
内部参考电压:0.9V
增益:1/4
分辨率:12 位(4096 个级别)
计算:
(0.9V × 4 × sample) / 4096 × 1000mV
对于 其他芯片:
内部参考电压:0.6V
增益:1/6
计算:
(0.6V × 6 × sample) / 4096 × 1000mV
测试与验证
步骤 8-9:硬件连接与测试
连接选项:
专用电池:直接连接电池正负极
可变电源:如 PPK2 或实验室电源
VDD 连接:用跳线连接模拟输入到 VDD
安全提醒:确保施加到模拟输入的电压不超过 VDD。如果电池电压高于 VDD,需要使用分压电路。
内部电压测量选项:
如需直接测量 VDD 电压,可以将 NRF_SAADC_INPUT_AIN0 替换为 NRF_SAADC_INPUT_VDD。
预期输出结果
*** Booting nRF Connect SDK ***
SAADC sample: 3245
Battery Voltage: 2852 mV
SAADC sample: 3237
Battery Voltage: 2845 mV
SAADC sample: 3252
Battery Voltage: 2858 mV结果分析:
原始采样值:3245 左右,接近 12 位 ADC 的满量程(4096)
计算电压:2850mV 左右,符合 VDD 电压预期
数值波动:小幅波动是正常的,反映了 ADC 的噪声特性
关键技术优势
使用 nrfx SAADC API 的主要优势:
精确控制:对 SAADC 硬件的完全访问
高性能:适合高速或精确时序要求的应用
硬件特性:可以利用 Nordic 专有的硬件功能
灵活配置:支持复杂的采样配置和缓冲管理
通过这个实验,您掌握了 nrfx SAADC 驱动的基础使用方法,为后续更高级的 ADC 应用(如连续采样、硬件触发等)打下了坚实基础。
nrfx SAADC 高级模式:硬件驱动的高速连续采样系统
本实验将探索 nrfx SAADC 驱动的高级模式,通过硬件定时器和 DPPI/PPI 实现高采样率的电压测量,完全无需 CPU 干预。这是一个展示 Nordic 芯片硬件特性强大能力的典型应用。
项目配置与驱动启用
步骤 1:多外设驱动配置
在 prj.conf 中启用必要的驱动:
CONFIG_NRFX_SAADC=y
CONFIG_NRFX_GPPI=y
CONFIG_NRFX_TIMER22=y配置解析:
CONFIG_NRFX_SAADC=y:启用 SAADC 底层驱动CONFIG_NRFX_GPPI=y:启用通用 PPI 接口,兼容 PPI 和 DPPICONFIG_NRFX_TIMER22=y:启用 TIMER22(nRF54L15)或 TIMER2(其他芯片)
芯片差异说明:不同 Nordic 芯片系列的可用 TIMER 实例不同。nRF52/nRF53/nRF91 使用 TIMER2,nRF54L15 使用 TIMER22。
步骤 2:头文件体系架构
#include <nrfx_saadc.h>
#include <nrfx_timer.h>
#include <helpers/nrfx_gppi.h>
#if defined(DPPI_PRESENT)
#include <nrfx_dppi.h>
#else
#include <nrfx_ppi.h>
#endif架构设计思想:
条件编译:自动适配不同芯片的 PPI/DPPI 外设
nrfx_gppi 抽象层:提供统一的 API 接口,屏蔽底层硬件差异
模块化设计:每个外设都有独立的头文件和驱动接口
硬件定时器配置:精确的采样时钟源
步骤 3:定时器系统设计
3.1 采样间隔定义
#define SAADC_SAMPLE_INTERVAL_US 5050 微秒的采样间隔意味着 20kHz 的采样频率,这是一个相当高的采样率,适合捕获快速变化的信号。
3.2 定时器实例声明
#define TIMER_INSTANCE_NUMBER 22
const nrfx_timer_t timer_instance = NRFX_TIMER_INSTANCE(TIMER_INSTANCE_NUMBER);这种宏定义方式提供了良好的可移植性,便于在不同芯片间切换。
3.3 定时器初始化与配置
nrfx_timer_config_t timer_config = NRFX_TIMER_DEFAULT_CONFIG(1000000);
err = nrfx_timer_init(&timer_instance, &timer_config, NULL);
if (err != NRFX_SUCCESS) {
LOG_ERR("nrfx_timer_init error: %08x", err);
return;
}配置参数解析:
1000000:定时器频率设置为 1MHz,提供微秒级精度NULL:不使用中断处理函数,因为将通过硬件 PPI 触发采样
3.4 比较事件配置
uint32_t timer_ticks = nrfx_timer_us_to_ticks(&timer_instance, SAADC_SAMPLE_INTERVAL_US);
nrfx_timer_extended_compare(&timer_instance, NRF_TIMER_CC_CHANNEL0, timer_ticks, NRF_TIMER_SHORT_COMPARE0_CLEAR_MASK, false);工作机制:
自动时钟转换:
nrfx_timer_us_to_ticks()将微秒转换为定时器滴答数自动清零:
NRF_TIMER_SHORT_COMPARE0_CLEAR_MASK使定时器在比较匹配后自动清零周期性触发:创建持续的 50μs 间隔脉冲
SAADC 高级模式配置:双缓冲的艺术
步骤 4:双缓冲系统设计
4.1 缓冲区大小策略
#define SAADC_BUFFER_SIZE 80008000 个样本的缓冲区在 50μs 采样间隔下可以存储 400ms 的数据。这个大小确保 CPU 有足够时间处理前一个缓冲区,而不会丢失新的采样数据。
4.2 双缓冲区声明
static int16_t saadc_sample_buffer[2][SAADC_BUFFER_SIZE];
static uint32_t saadc_current_buffer = 0;双缓冲工作原理:
乒乓操作:一个缓冲区接收新数据,另一个缓冲区被处理
索引管理:
saadc_current_buffer跟踪当前活动缓冲区无缝切换:硬件自动在缓冲区满时切换到备用缓冲区
SAADC 驱动详细配置
4.4-4.5 基础初始化
IRQ_CONNECT(DT_IRQN(DT_NODELABEL(adc)),
DT_IRQ(DT_NODELABEL(adc), priority),
nrfx_isr, nrfx_saadc_irq_handler, 0);
err = nrfx_saadc_init(DT_IRQ(DT_NODELABEL(adc), priority));使用设备树信息配置中断,提高代码的可移植性。
4.6 通道配置策略
#define NRF_SAADC_INPUT_AIN4 NRF_PIN_PORT_TO_PIN_NUMBER(11U, 1)
#define SAADC_INPUT_PIN NRF_SAADC_INPUT_AIN4
static nrfx_saadc_channel_t channel = NRFX_SAADC_DEFAULT_CHANNEL_SE(SAADC_INPUT_PIN, 0);nRF54L15 使用 AIN4 而非 AIN0,避免与 UART 功能冲突。
4.7 增益调整
channel.channel_config.gain = NRF_SAADC_GAIN1_4;
err = nrfx_saadc_channels_config(&channel, 1);1/4 增益适合测量接近 VDD 电压的信号。
4.8 高级模式配置
nrfx_saadc_adv_config_t saadc_adv_config = NRFX_SAADC_DEFAULT_ADV_CONFIG;
err = nrfx_saadc_advanced_mode_set(BIT(0),
NRF_SAADC_RESOLUTION_12BIT,
&saadc_adv_config,
saadc_event_handler);高级配置特性:
禁用过采样:提高采样速度
禁用内部定时器:使用外部硬件定时器
硬件触发:通过 PPI 触发 START 任务,避免软件延迟
4.9 双缓冲区设置
err = nrfx_saadc_buffer_set(saadc_sample_buffer[0], SAADC_BUFFER_SIZE);
err = nrfx_saadc_buffer_set(saadc_sample_buffer[1], SAADC_BUFFER_SIZE);预配置两个缓冲区,SAADC 外设将自动在它们之间切换。
事件处理系统:智能的数据流管理
步骤 5:事件驱动架构
5.1 就绪事件处理
case NRFX_SAADC_EVT_READY:
nrfx_timer_enable(&timer_instance);
break;当第一个缓冲区初始化完成时启动定时器,开始整个采样序列。
5.2 缓冲区请求处理
case NRFX_SAADC_EVT_BUF_REQ:
err = nrfx_saadc_buffer_set(saadc_sample_buffer[(saadc_current_buffer++)%2], SAADC_BUFFER_SIZE);
break;智能缓冲区管理:
模运算切换:
(saadc_current_buffer++)%2在 0 和 1 之间交替即时响应:当驱动获取缓冲区时立即提供新缓冲区
连续操作:确保采样不会因缓冲区不足而中断
5.3 数据处理事件
case NRFX_SAADC_EVT_DONE:
// 统计分析代码
int64_t average = 0;
int16_t max = INT16_MIN;
int16_t min = INT16_MAX;
for (int i = 0; i < p_event->data.done.size; i++) {
current_value = ((int16_t *)(p_event->data.done.p_buffer))[i];
average += current_value;
if (current_value > max) max = current_value;
if (current_value < min) min = current_value;
}
average = average / p_event->data.done.size;
LOG_INF("SAADC buffer at 0x%x filled with %d samples",
(uint32_t)p_event->data.done.p_buffer, p_event->data.done.size);
LOG_INF("AVG=%d, MIN=%d, MAX=%d", (int16_t)average, min, max);
break;数据分析功能:
实时统计:计算平均值、最大值、最小值
缓冲区标识:显示当前处理的缓冲区地址
数据验证:通过统计信息验证采样质量
硬件互连系统:(D)PPI 的威力
步骤 6:零延迟硬件触发链
6.1-6.2 通道分配
uint8_t m_saadc_sample_ppi_channel;
uint8_t m_saadc_start_ppi_channel;
err = nrfx_gppi_channel_alloc(&m_saadc_sample_ppi_channel);
err = nrfx_gppi_channel_alloc(&m_saadc_start_ppi_channel);分配两个 PPI 通道来实现完全的硬件自动化。
6.3 采样触发链路
nrfx_gppi_channel_endpoints_setup(m_saadc_sample_ppi_channel,
nrfx_timer_compare_event_address_get(&timer_instance, NRF_TIMER_CC_CHANNEL0),
nrf_saadc_task_address_get(NRF_SAADC, NRF_SAADC_TASK_SAMPLE));硬件触发链:TIMER COMPARE0 事件 → SAADC SAMPLE 任务
6.4 缓冲区切换链路
nrfx_gppi_channel_endpoints_setup(m_saadc_start_ppi_channel,
nrf_saadc_event_address_get(NRF_SAADC, NRF_SAADC_EVENT_END),
nrf_saadc_task_address_get(NRF_SAADC, NRF_SAADC_TASK_START));自动重启链:SAADC END 事件 → SAADC START 任务
6.5 通道激活
nrfx_gppi_channels_enable(BIT(m_saadc_sample_ppi_channel));
nrfx_gppi_channels_enable(BIT(m_saadc_start_ppi_channel));启用两个 PPI 通道,建立完整的硬件自动化系统。
系统工作流程:硬件协同的交响乐
整个系统的工作流程体现了精妙的硬件协同设计:
定时器启动:以 1MHz 频率运行,每 50μs 产生 COMPARE0 事件
自动采样:PPI 通道将 COMPARE0 事件连接到 SAADC SAMPLE 任务
连续采样:SAADC 连续采样 8000 个数据点填满缓冲区
自动重启:缓冲区满时,END 事件通过 PPI 触发 START 任务
缓冲区切换:驱动自动切换到备用缓冲区,软件处理已满缓冲区
测试与性能分析
预期输出结果
*** Booting nRF Connect SDK ***
[00:00:00.653,900] <inf> main: SAADC buffer at 0x20001150 filled with 8000 samples
[00:00:00.653,900] <inf> main: AVG=2064, MIN=2029, MAX=2099
[00:00:01.052,673] <inf> main: SAADC buffer at 0x20004fd0 filled with 8000 samples
[00:00:01.052,673] <inf> main: AVG=2064, MIN=2025, MAX=2097性能指标分析:
缓冲区交替:地址在
0x20001150和0x20004fd0之间交替,证明双缓冲机制正常工作采样稳定性:平均值稳定在 2064 左右,显示系统稳定性良好
噪声水平:最大值和最小值的差异反映了系统的噪声水平
时间间隔:约 400ms 的间隔(8000 样本 × 50μs = 400ms)
技术优势与应用价值
这个高级模式实现展示了几个重要的技术优势:
零 CPU 干预:采样过程完全由硬件自动化,CPU 可专注于数据处理或其他任务
精确时序:硬件定时器和 PPI 保证了严格的采样间隔,不受软件任务调度影响
高吞吐量:20kHz 采样率配合双缓冲,实现了高速连续数据采集
实时性能:适合需要实时信号处理的应用,如音频处理、振动监测等
通过这个实验,您深入理解了 Nordic 芯片硬件外设协同工作的强大能力,掌握了构建高性能数据采集系统的核心技术。
设备驱动开发
设备驱动是内核中维护的一组静态分配结构,这些结构包含关于设备实例的信息。其中值得关注的设备信息包括配置(config)、数据(data)、状态(state),以及用于访问该特定设备所支持全部功能的设备专属实现的 API 接口。
本课程将讲解设备驱动模型、API 接口、实例化及实现方法。随后我们将探讨 nRF Connect SDK 中提供的传感器驱动 API,以及如何为其添加自定义传感器。在使用传感器 API 实现自定义驱动后,我们将通过电源管理例程来扩展该驱动功能。最后我们将自主设计 API 并实现覆盖该 API 的驱动程序。
Zephyr 设备驱动模型:统一抽象与灵活实现的完美结合
设备驱动模型是 Zephyr RTOS 的核心架构之一,为嵌入式系统开发提供了强大的硬件抽象能力。这种设计理念体现了"高内聚、低耦合"的软件工程原则,为开发者带来了前所未有的便利性和可移植性。
驱动模型的核心设计理念
Zephyr 设备驱动模型最显著的特征是API 与实现的高度解耦。这种架构设计使得开发者可以在不修改应用层代码的情况下,轻松切换底层驱动实现。这就像使用**"标准化接口"**——无论底层硬件如何变化,上层应用都能通过相同的接口进行交互。
架构优势:这种解耦设计带来了极高的代码可移植性,使得同一份应用代码可以在不同的开发板上运行,而无需手动修改底层驱动实现。
三层架构:清晰的职责分离
Zephyr 设备驱动模型采用三层架构设计,每一层都有明确的职责和功能:
设备驱动 API 层:标准化的抽象接口
设备驱动 API 是整个架构的**"合约层"**,定义了应用程序与硬件设备交互的标准接口。这些 API 提供了硬件抽象,使应用层能够以统一的方式访问各种硬件设备。
标准化的威力:正因为有了标准化的 API,开发者可以选择任何支持该 API 的设备,更换不同的硬件设备时无需修改应用程序代码。
实际应用价值:在练习 1 中,我们将创建一个实现现有传感器 API 的驱动程序,直观体验标准 API 的强大功能。
设备驱动实例层:具体的设备对象
设备驱动实例 是连接抽象 API 和具体实现的**"桥梁"**,代表系统中的具体硬件设备对象。每个实例都包含了设备的配置信息、状态数据和操作方法。
设备驱动实现层:硬件特定的底层逻辑
设备驱动实现 是真正与硬件打交道的底层代码,包含了特定硬件的操作逻辑和寄存器访问代码。这一层负责将抽象的 API 调用转换为具体的硬件操作。
扩展能力:自定义 API 的灵活性
虽然 Zephyr 提供了丰富的标准设备驱动 API,但在某些特殊应用场景中,现有的 API 可能无法满足特定需求。此时,Zephyr 的架构灵活性就体现出来了。
自定义 API 的实现路径
当现有 API 无法满足特定需求时,开发者可以引入自定义 API 并与 Zephyr 构建系统集成。这种设计让驱动程序能够实现自定义功能,同时为应用层提供清晰的抽象接口。
可扩展性考虑:通过实现更多覆盖自定义 API 的驱动程序,可以进一步扩展应用程序的可移植性。这种设计为复杂应用需求提供了完美的解决方案。
学习路径:练习 3 将详细介绍如何实现自定义 API 驱动程序的完整过程。
电源管理集成:智能的功耗优化
无论是标准 API 驱动还是自定义 API 驱动,都可以集成电源管理功能。这是 Zephyr 系统的一个重要特性,体现了对现代嵌入式设备功耗敏感性的深度理解。
标准化的电源管理子系统
电源管理 是 Zephyr 的标准化子系统,负责将设备驱动置于挂起模式以降低功耗。每个设备驱动都可以定义自己在低功耗模式下的行为策略。
智能化管理:系统能够根据应用需求和硬件状态,智能地管理各个设备的电源状态,实现最佳的功耗平衡。
实践指导:本课程的设备电源管理主题将深入探讨这一技术,练习 2 将演示在自定义驱动中实现电源管理的所有必要步骤。
架构价值与应用前景
Zephyr 设备驱动模型的设计体现了现代嵌入式系统开发的几个重要趋势:
可移植性优先:通过标准化 API,实现了"一次编写,处处运行"的理想目标
模块化设计:清晰的分层架构使得系统更易于维护和扩展
功耗意识:内置的电源管理支持体现了对现代嵌入式应用功耗敏感性的重视
灵活扩展:支持自定义 API 的架构为特殊需求提供了完美的解决方案
通过深入理解和掌握 Zephyr 设备驱动模型,开发者能够构建更加健壮、可移植和高效的嵌入式应用系统,为复杂的 IoT 和嵌入式项目奠定坚实的技术基础。
设备驱动实现:深入核心的结构化设计艺术
设备驱动实现是 Zephyr 系统的技术核心,其精妙之处在于围绕驱动数据结构构建的完整生态系统。理解这些关键组件对于掌握嵌入式系统开发至关重要。
Zephyr 设备的核心抽象
struct device:设备的数字化身份
在 Zephyr 中,每个硬件设备都由 struct device 结构体表示,这个结构体就像设备的**"身份证"**,记录了设备的所有关键信息:
struct device {
const char *name; // 设备名称(唯一标识)
const void *config; // 只读配置数据
void * const data; // 运行时可修改数据
const void *api; // 设备 API 操作接口
...
};字段功能解析:
name:设备的唯一名称,对应设备树中的
label属性,是设备在系统中的**"身份标识"**config:编译时设置的只读配置引用,通常存储设备树属性,就像设备的**"出厂配置"**
data:运行时需要修改的设备数据引用,如计数器、状态等,是设备的**"工作记忆"**
api:设备 API 操作的引用,定义了与该设备交互的**"操作手册"**
设备定义:从代码到硬件的映射
Zephyr 提供了两种设备定义方式,对应不同的使用场景:
DEVICE_DEFINE():用于非设备树设备,适合简单的静态设备
DEVICE_DT_DEFINE() 或 DEVICE_DT_INST_DEFINE():用于基于设备树的设备,是现代驱动开发的主流方式
自动化优势:设备在启动时自动初始化,在
main函数执行前完成,初始化顺序由级别和手动定义的优先级决定。
多实例驱动设计:可扩展性的典范
实例化宏设计模式
让我们深入分析一个典型的多实例设备驱动定义:
#define DT_DRV_COMPAT vendor_mysensor
#define MYSENSOR_DEFINE(inst) \
static struct mysensor_data data_##inst; \
static const struct mysensor_config config_##inst \
= { .spi = SPI_DT_SPEC_INST_GET(inst, SPIOP, 0),}; \
\
DEVICE_DT_INST_DEFINE(inst, \
mysensor_init, \
NULL, \
&data_##inst, \
&config_##inst, \
POST_KERNEL, \
CONFIG_SENSOR_INIT_PRIORITY, \
&mysensor_api);
DT_INST_FOREACH_STATUS_OKAY(MYSENSOR_DEFINE)DT_DRV_COMPAT:兼容性声明
#define DT_DRV_COMPAT vendor_mysensor这个定义是整个实例化系统的**"起点"**。它告诉 Zephyr 构建系统,当前驱动支持哪种设备树兼容字符串。
命名规则:兼容字符串 "vendor,mysensor" 转换为 vendor_mysensor(逗号变下划线,连字符变下划线)
MYSENSOR_DEFINE 宏:模板化的设备创建
MYSENSOR_DEFINE(inst) 宏是一个**"设备工厂"**,通过模板化的方式为每个设备实例创建必要的数据结构:
数据结构实例化:
static struct mysensor_data data_##inst;为每个实例创建独立的数据结构,## 是 C 预处理器的连接操作符,data_##inst 会展开为 data_0、data_1 等。
配置结构实例化:
static const struct mysensor_config config_##inst = {
.spi = SPI_DT_SPEC_INST_GET(inst, SPIOP, 0),
};为每个实例创建独立的配置结构,其中 SPI_DT_SPEC_INST_GET 从设备树中获取该实例的 SPI 总线配置。
DEVICE_DT_INST_DEFINE:设备对象的诞生
这个宏是设备驱动实现的**"灵魂"**,它将所有组件组合成一个完整的设备对象:
DEVICE_DT_INST_DEFINE(inst, // 实例编号
mysensor_init, // 初始化函数
NULL, // 电源管理回调
&data_##inst, // 设备数据指针
&config_##inst, // 设备配置指针
POST_KERNEL, // 初始化级别
CONFIG_SENSOR_INIT_PRIORITY, // 初始化优先级
&mysensor_api); // API 结构指针参数详解:每个参数的深层含义
inst(实例编号):设备树中兼容节点的索引号,使系统能够区分同类型的多个设备
mysensor_init(初始化函数):设备的**"启动程序"**,负责设置必要资源(电源、安全性、引脚和内存的初始状态)
NULL(电源管理):某些驱动支持电源管理功能以优化电池供电设备的能耗。如果驱动不使用电源管理,可以传入 NULL
电源管理扩展:在本课程的练习 2 中,我们将学习如何在自定义驱动中实现电源管理功能。
&data_##inst(设备数据):指向设备数据结构实例的指针,确保每个设备对象都有自己独立的数据空间
&config_##inst(设备配置):存储设备的只读配置数据,在驱动初始化时填充,每个设备实例都有独立的配置结构
初始化级别:启动序列的精确控制
POST_KERNEL:最常用的初始化级别,适用于需要内核服务的设备
Zephyr 提供三个初始化级别,体现了精细的启动时序控制:
PRE_KERNEL_1:用于无依赖关系的设备,如仅依赖处理器/SoC 硬件的设备。这些设备在配置期间无法使用内核服务,但可以设置中断。初始化函数在中断栈上运行。
PRE_KERNEL_2:用于依赖 PRE_KERNEL_1 级别设备初始化的设备。同样无法使用内核服务,初始化函数在中断栈上运行。
POST_KERNEL:用于在配置期间需要内核服务的设备。初始化函数在内核主任务上下文中运行。
CONFIG_SENSOR_INIT_PRIORITY(优先级):在同一初始化级别内,驱动可以指定相对于其他设备的优先级,范围 0-999,数值越小初始化越早
&mysensor_api(API 结构):驱动程序公开的 API 结构,允许应用代码与硬件设备交互。这个 API 是函数指针结构,包含所有必要的 API 函数实现。
DT_INST_FOREACH_STATUS_OKAY:批量实例化的魔法
DT_INST_FOREACH_STATUS_OKAY(MYSENSOR_DEFINE)这行代码是整个多实例系统的**"启动器"**。它的工作机制:
扫描设备树:查找所有与
DT_DRV_COMPAT兼容且状态为"okay"的节点提取实例号:为每个找到的节点分配实例编号(0, 1, 2, …)
批量创建:对每个实例调用
MYSENSOR_DEFINE宏,创建完整的设备对象
自动化价值:这种设计使得添加新的设备实例只需要在设备树中添加节点,无需修改驱动代码,体现了声明式编程的优雅。
架构优势:现代嵌入式开发的最佳实践
这种设备驱动实现方式体现了几个重要的设计原则:
数据驱动:通过设备树描述硬件配置,实现硬件和软件的解耦
模板化设计:通过宏模板实现代码复用,减少重复编码
类型安全:编译时创建所有必要的数据结构,避免运行时错误
可扩展性:支持任意数量的设备实例,无需手动管理设备列表
资源隔离:每个设备实例都有独立的数据和配置空间,避免相互干扰
通过深入理解这些实现细节,开发者能够创建更加健壮、可维护和可扩展的嵌入式系统驱动程序,为复杂的硬件系统提供强大的软件支撑。
设备电源管理:智能功耗控制的系统化实现
设备电源管理是现代嵌入式系统的核心技术之一,特别是在电池供电设备日益普及的今天。Zephyr 的电源管理(PM)子系统提供了一个完整的框架,通过禁用或挂起当前未使用的子系统或设备来显著降低整体功耗。
电源管理框架的设计哲学
Zephyr 电源管理系统体现了"分层自治"的设计理念。每个组件都可以独立运行,无需了解其他组件的内部工作机制。进入或退出低功耗模式的具体行为是供应商特定的,设备驱动作者可以自由决定在各种状态下采取的具体行动。
架构优势:这种设计使得电源管理既具有标准化的接口,又保持了足够的灵活性来适应不同硬件的特殊需求。
设备电源状态体系
Zephyr 定义了四种基本的设备电源状态,形成了完整的状态管理体系:
enum pm_device_state {
PM_DEVICE_STATE_ACTIVE, // 活跃状态
PM_DEVICE_STATE_SUSPENDED, // 挂起状态
PM_DEVICE_STATE_SUSPENDING, // 挂起中状态
PM_DEVICE_STATE_OFF // 关闭状态
};状态转换逻辑:
ACTIVE:设备正常工作状态,所有功能完全可用
SUSPENDING:设备正在从活跃状态转向挂起状态的过渡阶段
SUSPENDED:设备处于低功耗模式,保持基本状态但停止主要功能
OFF:设备完全关闭,功耗最低但需要重新初始化才能使用
责任分离:Zephyr 系统仅提供状态转换的通知机制,具体的状态处理动作完全由设备驱动负责实现。
实战案例:nRF SPI 驱动的电源管理
让我们通过 nRF SPI 驱动的实现来深入理解电源管理的工作机制:
static int spim_nrfx_pm_action(const struct device *dev,
enum pm_device_action action)
{
switch (action) {
case PM_DEVICE_ACTION_TURN_ON:
ret = 0;
break;
case PM_DEVICE_ACTION_RESUME:
ret = pinctrl_apply_state(dev_config->pcfg,
PINCTRL_STATE_DEFAULT);
// 恢复引脚配置到默认工作状态
break;
case PM_DEVICE_ACTION_SUSPEND:
if (dev_data->initialized) {
nrfx_spim_uninit(&dev_config->spim);
dev_data->initialized = false;
}
// 反初始化 SPI 外设
ret = pinctrl_apply_state(dev_config->pcfg,
PINCTRL_STATE_SLEEP);
// 配置引脚到低功耗状态
break;
default:
break;
}
return ret;
}动作类型解析
PM_DEVICE_ACTION_TURN_ON:开启设备,通常用于从完全关闭状态启动设备
PM_DEVICE_ACTION_RESUME:从挂起状态恢复设备,重新配置引脚到默认工作状态
PM_DEVICE_ACTION_SUSPEND:将设备置于挂起状态,包括:
反初始化硬件外设以释放资源
将引脚配置切换到低功耗睡眠状态
引脚控制重要性:引脚状态的正确管理是功耗优化的关键环节,不当的引脚配置可能导致意外的漏电流。
电源管理回调的集成
电源管理回调是设备定义中的可选参数,体现了 Zephyr 系统的灵活性:
PM_DEVICE_DT_DEFINE(SPIM(idx), spim_nrfx_pm_action);
DEVICE_DT_DEFINE(SPIM(idx),
spi_nrfx_init,
PM_DEVICE_DT_GET(SPIM(idx)), // 电源管理资源引用
&spi_##idx##_data,
&spi_##idx##z_config,
POST_KERNEL, CONFIG_SPI_INIT_PRIORITY,
&spi_nrfx_driver_api)集成模式解析:
PM_DEVICE_DT_DEFINE():将电源管理回调与设备树节点关联
PM_DEVICE_DT_GET():在设备定义中获取电源管理资源的引用
间接引用:回调函数不直接包含在设备定义中,而是通过宏助手间接关联
运行时电源管理:智能的需求驱动模式
策略工作机制
设备运行时电源管理策略采用"按需激活"的智能模式:
初始挂起:设备在初始化过程中进入挂起状态
需求激活:当需要使用设备时,驱动通知电源管理子系统
自动挂起:设备使用完毕后,自动返回挂起状态
API 接口设计
设备激活接口:
pm_device_runtime_get(const struct device *dev)通知电源管理子系统设备即将被使用,系统随即唤醒设备并切换到工作状态。
设备释放接口:
pm_device_runtime_put(const struct device *dev)通知电源管理子系统设备使用完毕,系统将设备置于挂起状态以节省功耗。
实际应用:SPI 事务处理中的电源管理
事务开始时的电源管理
static int transceive(const struct device *dev,
const struct spi_config *spi_cfg,
const struct spi_buf_set *tx_bufs,
const struct spi_buf_set *rx_bufs,
bool asynchronous,
spi_callback_t cb,
void *userdata)
{
if (IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)) {
pm_device_runtime_get(dev); // 激活设备
}
spi_context_lock(&dev_data->ctx, asynchronous, cb, userdata, spi_cfg);
// 开始 SPI 事务处理
}事务结束时的电源管理
static inline void finalize_spi_transaction(const struct device *dev, bool deactivate_cs)
{
// SPI 事务清理工作
if (IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)) {
pm_device_runtime_put(dev); // 释放设备
}
}设计亮点:
条件编译:通过
IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)确保只在启用运行时电源管理时执行相关代码配对调用:
get和put调用严格配对,确保设备状态管理的正确性透明集成:电源管理逻辑与业务逻辑清晰分离,不影响核心功能
电源管理的实践价值
功耗优化效果
运行时电源管理策略能够带来显著的功耗优化效果:
静态功耗降低:未使用的设备保持在挂起状态,大幅减少静态电流消耗
动态功耗控制:设备仅在需要时激活,避免不必要的功耗开销
系统级优化:多个设备的协调管理实现整体功耗的最优化
应用场景适配
这种电源管理策略特别适合以下应用场景:
间歇性使用:设备使用频率不高,有明显的空闲期
电池供电:对功耗敏感的便携式或物联网设备
多外设系统:需要协调管理多个外设功耗的复杂系统
学习指导:在本课程的练习 2 中,我们将在自定义的 BME280 驱动中实现设备运行时电源管理策略,提供完整的实践经验。
通过深入理解和掌握 Zephyr 的电源管理框架,开发者能够构建更加节能高效的嵌入式系统,为现代物联网应用的可持续发展提供强有力的技术支撑。
Zephyr 外部模块实战:BME280 传感器驱动的完整开发之旅
本实验将带您完整体验使用 Zephyr 传感器 API 创建自定义 BME280 传感器驱动的全过程。这是一个典型的外部模块开发项目,展示了如何将自定义驱动集成到 Zephyr 生态系统中。
外部模块架构设计
项目结构:清晰的功能分离
本实验采用了模块化设计思想,将代码分为两个独立的目录:
l7_e1/
├─── app/ # 目标应用程序
│ ├─── boards/
│ ├─── src/main.c
│ ├─── prj.conf
│ └─── CMakeLists.txt
│
└─── custom_driver_module/ # Zephyr 外部模块
├─── drivers/sensor/custom_bme280/
├─── dts/bindings/sensor/
└─── zephyr/module.yml设计亮点:
app 目录:包含使用传感器的应用程序,负责读取数据并输出测量结果
custom_driver_module 目录:包含驱动实现的外部模块,是本实验的核心重点
外部模块价值:外部模块是位于 Zephyr 根目录之外但可与 Zephyr 集成的源代码。通过
module.yml文件,我们可以告知 Zephyr 构建系统在哪里寻找模块文件。
设备树绑定:硬件抽象的起点
步骤 1:自定义绑定文件创建
创建 zephyr,custom-bme280.yaml 绑定文件:
description: BME280 integrated environmental sensor
compatible: "zephyr,custom-bme280"
include: [sensor-device.yaml, spi-device.yaml]绑定文件要点:
description:人类可读的设备描述
compatible:唯一的兼容性字符串,用于设备树匹配
include:继承标准传感器和 SPI 设备的通用属性
文件位置策略:遵循 Zephyr 文件结构约定,将绑定文件放置在 dts/bindings/sensor/ 目录下,保持与 Zephyr 基础目录相似的结构。
驱动实现核心:兼容性与数据结构
步骤 2:驱动兼容性声明
#define DT_DRV_COMPAT zephyr_custom_bme280
#if DT_NUM_INST_STATUS_OKAY(DT_DRV_COMPAT) == 0
#warning "Custom BME280 driver enabled without any devices"
#endif设计机制:
DT_DRV_COMPAT:将绑定的
"zephyr,custom-bme280"转换为 C 宏zephyr_custom_bme280设备检查:在编译时验证设备树中是否存在相应的设备节点
步骤 3:核心数据结构设计
3.1 设备数据结构
struct custom_bme280_data {
/* 补偿参数 */
uint16_t dig_t1;
int16_t dig_t2;
int16_t dig_t3;
// ... 更多补偿参数
/* 补偿后的数值 */
int32_t comp_temp;
uint32_t comp_press;
uint32_t comp_humidity;
/* 温度与压力/湿度补偿间的传递值 */
int32_t t_fine;
uint8_t chip_id;
};这个结构体是 BME280 传感器的**"数据大脑"**,包含了传感器运行所需的所有参数和状态信息。
3.2 配置结构体
struct custom_bme280_config {
struct spi_dt_spec spi;
};配置结构体存储了与硬件通信所需的 SPI 总线信息。
3.3 传感器 API 结构
static const struct sensor_driver_api custom_bme280_api = {
.sample_fetch = &custom_bme280_sample_fetch,
.channel_get = &custom_bme280_channel_get,
};API 设计理念:利用 Zephyr 现有的传感器 API,实现标准化的接口。这种设计使得应用程序可以用统一的方式访问不同的传感器设备。
API 函数实现:数据获取与处理的艺术
步骤 4:核心 API 函数实现
4.1 采样获取函数
static int custom_bme280_sample_fetch(const struct device *dev, enum sensor_channel chan)
{
struct custom_bme280_data *data = dev->data;
uint8_t buf[8];
int32_t adc_press, adc_temp, adc_humidity;
int err;
__ASSERT_NO_MSG(chan == SENSOR_CHAN_ALL);
err = bme280_wait_until_ready(dev);
if (err < 0) return err;
err = bme280_reg_read(dev, PRESSMSB, buf, 8);
if (err < 0) return err;
// ADC 数据解析
adc_press = (buf[0] << 12) | (buf[1] << 4) | (buf[2] >> 4);
adc_temp = (buf[3] << 12) | (buf[4] << 4) | (buf[5] >> 4);
adc_humidity = (buf[6] << 8) | buf[7];
// 数据补偿处理
bme280_compensate_temp(data, adc_temp);
bme280_compensate_press(data, adc_press);
bme280_compensate_humidity(data, adc_humidity);
return 0;
}数据处理流程:
等待就绪:确保传感器准备好进行数据读取
批量读取:一次性读取 8 字节的原始传感器数据
数据解析:将读取的字节数据重新组合成 ADC 值
补偿计算:使用校准参数对原始数据进行补偿
4.2 通道数据获取函数
static int custom_bme280_channel_get(const struct device *dev,
enum sensor_channel chan,
struct sensor_value *val)
{
struct custom_bme280_data *data = dev->data;
switch (chan) {
case SENSOR_CHAN_AMBIENT_TEMP:
val->val1 = data->comp_temp / 100;
val->val2 = data->comp_temp % 100 * 10000;
break;
case SENSOR_CHAN_PRESS:
val->val1 = (data->comp_press >> 8) / 1000U;
val->val2 = (data->comp_press >> 8) % 1000 * 1000U +
(((data->comp_press & 0xff) * 1000U) >> 8);
break;
case SENSOR_CHAN_HUMIDITY:
val->val1 = (data->comp_humidity >> 10);
val->val2 = (((data->comp_humidity & 0x3ff) * 1000U * 1000U) >> 10);
break;
default:
return -ENOTSUP;
}
return 0;
}精度处理策略:
温度:0.01°C 分辨率(5123 = 51.23°C)
压力:256 分之一 Pa 精度(24674867/256 = 96386.2 Pa)
湿度:1024 分之一 %RH 精度(47445/1024 = 46.333 %RH)
设备定义:模板化的多实例支持
步骤 5:设备定义宏设计
#define CUSTOM_BME280_DEFINE(inst) \
static struct custom_bme280_data custom_bme280_data_##inst; \
static const struct custom_bme280_config custom_bme280_config_##inst = { \
.spi = SPI_DT_SPEC_INST_GET(inst, SPIOP, 0), \
}; \
\
DEVICE_DT_INST_DEFINE(inst, \
custom_bme280_init, \
NULL, \
&custom_bme280_data_##inst, \
&custom_bme280_config_##inst, \
POST_KERNEL, \
CONFIG_SENSOR_INIT_PRIORITY, \
&custom_bme280_api);
DT_INST_FOREACH_STATUS_OKAY(CUSTOM_BME280_DEFINE)模板化设计优势:
实例隔离:每个设备实例都有独立的数据和配置空间
自动配置:从设备树自动获取 SPI 配置信息
批量创建:
DT_INST_FOREACH_STATUS_OKAY为所有启用的设备节点创建设备对象
构建系统集成:完整的 Zephyr 生态融合
步骤 6:构建系统配置
6.1 CMake 配置
# drivers/sensor/custom_bme280/CMakeLists.txt
zephyr_library()
zephyr_library_sources(custom_bme280.c)6.2 Kconfig 配置
config CUSTOM_BME280
bool "Custom BME280 sensor"
default y
depends on DT_HAS_ZEPHYR_CUSTOM_BME280_ENABLED
select SPI
help
Enable custom BME280 driver配置机制亮点:
依赖检查:
depends on DT_HAS_ZEPHYR_CUSTOM_BME280_ENABLED确保只有在设备树中存在相应设备时才启用驱动自动选择:
select SPI自动启用 SPI 子系统支持
步骤 7:Zephyr 模块定义
7.1 模块配置文件
# zephyr/module.yml
build:
kconfig: Kconfig
cmake: .
settings:
dts_root: .模块集成机制:
dts_root:将模块的
dts目录加入设备树搜索路径构建集成:指定 Kconfig 和 CMake 文件位置
应用程序集成:从驱动到应用的完整链路
步骤 8:项目配置
8.1 模块路径配置
# app/CMakeLists.txt
list(APPEND EXTRA_ZEPHYR_MODULES ${CMAKE_CURRENT_SOURCE_DIR}/../custom_driver_module)8.2 驱动启用
# app/prj.conf
CONFIG_SENSOR=y
CONFIG_CUSTOM_BME280=y8.3 设备树节点定义
bme280: bme280@0 {
compatible = "zephyr,custom-bme280";
reg = <0>;
spi-max-frequency = <1000000>; // 1MHz
};步骤 9:应用程序实现
const struct device *dev = DEVICE_DT_GET(DT_NODELABEL(bme280));
struct sensor_value temp_val, press_val, hum_val;
while (1) {
err = sensor_sample_fetch(dev);
if (err < 0) {
LOG_ERR("Could not fetch sample (%d)", err);
return 0;
}
sensor_channel_get(dev, SENSOR_CHAN_AMBIENT_TEMP, &temp_val);
sensor_channel_get(dev, SENSOR_CHAN_PRESS, &press_val);
sensor_channel_get(dev, SENSOR_CHAN_HUMIDITY, &hum_val);
LOG_INF("Temperature: %d°C", temp_val.val1);
LOG_INF("Pressure: %d hPa", press_val.val1);
LOG_INF("Humidity: %d %%RH", hum_val.val1);
k_sleep(K_MSEC(1000));
}应用程序特点:
标准 API:使用 Zephyr 标准传感器 API,代码具有良好的可移植性
错误处理:包含完整的错误检查和处理机制
周期采样:每秒采样一次,适合大多数环境监测应用
系统验证:完整功能测试
预期输出结果
[00:00:00.291,290] <dbg> custom_bme280: custom_bme280_init: ID OK
[00:00:00.303,253] <dbg> custom_bme280: custom_bme280_init: "bme280@0" OK
*** Booting nRF Connect SDK ***
*** Using Zephyr OS ***
[00:00:00.303,314] <inf> Lesson7_Exercise1: Lesson 7 - Exercise 1 started
[00:00:00.404,052] <inf> Lesson7_Exercise1: Compensated temperature value: 25
[00:00:00.404,052] <inf> Lesson7_Exercise1: Compensated pressure value: 98
[00:00:00.404,052] <inf> Lesson7_Exercise1: Compensated humidity value: 37验证要点:
初始化成功:驱动正确识别传感器 ID 并完成初始化
数据有效性:温度、压力、湿度数据在合理范围内
系统稳定性:持续稳定的数据输出
自定义驱动电源管理集成:智能功耗控制的实践之旅
本实验将在练习 1 创建的自定义驱动基础上,添加设备运行时电源管理功能。我们将实现一个完整的层次化电源管理系统,其中 BME280 驱动和 SPI 总线驱动都会在不活跃时自动进入挂起状态。
电源管理回调:状态转换的智能处理
步骤 1:电源状态回调函数定义
static int custom_bme280_pm_action(const struct device *dev,
enum pm_device_action action)
{
int ret = 0;
switch (action) {
case PM_DEVICE_ACTION_RESUME:
LOG_INF("Resuming BME280 sensor");
/* 重新初始化芯片 */
ret = custom_bme280_init(dev);
break;
case PM_DEVICE_ACTION_SUSPEND:
LOG_INF("Suspending BME280 sensor");
/* 将芯片置于睡眠模式 */
ret = bme280_reg_write(dev, CTRLMEAS, 0x93);
if (ret < 0) {
LOG_DBG("CTRL_MEAS write failed: %d", ret);
}
break;
default:
return -ENOTSUP;
}
return ret;
}电源管理策略解析:
RESUME 操作:
完整重新初始化:调用
custom_bme280_init()确保传感器从睡眠状态完全恢复状态可观测性:通过日志输出让开发者清楚了解电源状态变化
SUSPEND 操作:
硬件睡眠模式:向 CTRLMEAS 寄存器写入 0x93,激活 BME280 的硬件睡眠功能
功耗最优化:利用传感器本身的低功耗特性,而不是简单地停止通信
设计思想:这种回调机制体现了"硬件感知"的电源管理策略,充分利用传感器芯片的原生低功耗特性。
运行时电源管理集成:按需激活的精准控制
步骤 2:采样函数的电源管理增强
static int custom_bme280_sample_fetch(const struct device *dev,
enum sensor_channel chan)
{
struct custom_bme280_data *data = dev->data;
uint8_t buf[8];
int32_t adc_press, adc_temp, adc_humidity;
int err;
__ASSERT_NO_MSG(chan == SENSOR_CHAN_ALL);
/* 通知电源管理系统驱动需要设备处于活跃状态 */
if (IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)) {
pm_device_runtime_get(dev);
}
err = bme280_wait_until_ready(dev);
if (err < 0) {
if (IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)) {
pm_device_runtime_put(dev);
}
return err;
}
err = bme280_reg_read(dev, PRESSMSB, buf, 8);
if (err < 0) {
if (IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)) {
pm_device_runtime_put(dev);
}
return err;
}
LOG_INF("Sensor Data acquired");
/* 数据处理 */
adc_press = (buf[0] << 12) | (buf[1] << 4) | (buf[2] >> 4);
adc_temp = (buf[3] << 12) | (buf[4] << 4) | (buf[5] >> 4);
adc_humidity = (buf[6] << 8) | buf[7];
bme280_compensate_temp(data, adc_temp);
bme280_compensate_press(data, adc_press);
bme280_compensate_humidity(data, adc_humidity);
/* 通知电源管理系统设备不再需要 */
if (IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)) {
pm_device_runtime_put(dev);
}
return 0;
}电源管理流程设计:
激活阶段:
条件激活:
IS_ENABLED(CONFIG_PM_DEVICE_RUNTIME)确保只在启用运行时电源管理时执行设备唤醒:
pm_device_runtime_get()通知系统需要设备处于工作状态错误处理:在任何错误情况下都确保调用
pm_device_runtime_put()释放设备
数据获取阶段:
就绪等待:等待传感器准备就绪后再进行数据读取
批量读取:一次性读取所有传感器数据,减少总线占用时间
即时处理:立即进行数据补偿计算
释放阶段:
配对释放:确保每次
get操作都有对应的put操作状态一致性:维护电源管理系统的状态一致性
层次化管理:由于
custom_bme280_sample_fetch()使用 SPI 驱动获取传感器数据,SPI 驱动也会应用运行时电源管理策略。这形成了层次化的电源管理关系,实现更低的整体功耗。
设备定义增强:电源管理的无缝集成
步骤 3:电源管理结构集成
3.1 电源管理函数绑定
PM_DEVICE_DT_INST_DEFINE(inst, custom_bme280_pm_action);这行代码将电源管理回调函数与设备树实例关联,建立了电源状态变化的处理机制。
3.2 设备定义更新
DEVICE_DT_INST_DEFINE(inst,
custom_bme280_init,
PM_DEVICE_DT_INST_GET(inst), // 电源管理资源引用
&custom_bme280_data_##inst,
&custom_bme280_config_##inst,
POST_KERNEL,
CONFIG_SENSOR_INIT_PRIORITY,
&custom_bme280_api);集成机制:
PM_DEVICE_DT_INST_GET(inst):获取与该设备实例关联的电源管理资源
无缝集成:电源管理功能透明地集成到设备定义中,不影响其他功能
设备树配置:声明式的电源管理启用
步骤 4:设备树电源管理配置
4.1 BME280 传感器电源管理启用
bme280: bme280@0 {
compatible = "zephyr,custom-bme280";
reg = <0>;
spi-max-frequency = <1000000>;
zephyr,pm-device-runtime-auto; // 启用运行时电源管理
};4.2 SPI 总线电源管理启用
&spi4 {
compatible = "nordic,nrf-spim";
status = "okay";
zephyr,pm-device-runtime-auto; // 启用运行时电源管理
pinctrl-0 = <&spi4_default>;
pinctrl-1 = <&spi4_sleep>; // 睡眠状态引脚配置
pinctrl-names = "default", "sleep";
};配置解析:
zephyr,pm-device-runtime-auto:声明式地启用设备运行时电源管理
引脚状态配置:
pinctrl-1 = <&spi4_sleep>定义睡眠状态下的引脚配置层次化管理:SPI 总线和传感器设备都启用电源管理,形成协调的功耗控制
引脚配置重要性:SPI 驱动会在电源状态变化时重新配置引脚,这对于最小化功耗至关重要。不正确的引脚配置可能导致意外的漏电流。
系统级配置:电源管理子系统启用
步骤 5:项目配置文件
CONFIG_PM_DEVICE=y
CONFIG_PM_DEVICE_RUNTIME=y配置选项解析:
CONFIG_PM_DEVICE=y:启用设备驱动的电源管理功能
CONFIG_PM_DEVICE_RUNTIME=y:启用设备运行时电源管理策略
注意事项:
CONFIG_PM选项用于启用板级额外的电源管理策略,在这个实验中我们主要关注设备级别的电源管理。
系统行为验证:电源状态的可观测性
预期输出分析
*** Booting nRF Connect SDK ***
*** Using Zephyr OS ***
[00:00:00.579,353] Lesson7_Exercise1: Lesson 7 - Exercise 1 started
[00:00:00.579,357] Lesson7_Exercise1: Sample fetching…
[00:00:00.579,364] custom_bme280: Resuming BME280 sensor
[00:00:00.766,496] custom_bme280: Sensor Data acquired
[00:00:00.766,512] custom_bme280: Suspending BME280 sensor
[00:00:00.766,881] Lesson7_Exercise1: Compensated temperature value: 23
[00:00:00.766,887] Lesson7_Exercise1: Compensated pressure value: 98
[00:00:00.766,891] Lesson7_Exercise1: Compensated humidity value: 34行为分析:
电源状态流程:
采样开始:应用程序请求采样数据
设备唤醒:传感器从挂起状态恢复,执行重新初始化
数据获取:成功读取传感器数据
设备挂起:数据获取完成后,传感器进入睡眠模式
数据输出:处理后的数据输出到应用程序
时序特征:
快速响应:从唤醒到数据获取完成仅用时约 187ms
及时挂起:数据获取后立即进入挂起状态,最大化节能效果
无缝体验:电源管理对应用程序完全透明
自定义 API 驱动开发:构建专属硬件抽象层的完整实践
在前面的实验中,我们使用现有的传感器 API 开发了自定义驱动。然而,在某些情况下,现有的子系统可能无法满足我们的特定需求。本实验将深入探讨如何创建完全自定义的 API,配置设备树的自定义参数,并在驱动和应用程序中使用这些功能。
项目需求分析:LED 闪烁控制系统
我们将创建一个用于周期性闪烁 LED 的自定义驱动系统,具备以下核心功能:
硬件需求:
LED 的 GPIO 引脚配置
可配置的闪烁周期
API 需求:
blink_set_period_ms:动态更改闪烁周期blink_off:完全关闭 LED
这个项目展示了从硬件抽象到用户接口的完整技术栈设计。
设备树绑定:自定义参数的声明式配置
步骤 1:自定义绑定文件创建
1.1 基础绑定定义
创建 blink-gpio-leds.yaml 文件:
compatible: "blink-gpio-led"
include: base.yaml1.2 GPIO 属性配置
properties:
led-gpios:
type: phandle-array
required: true
description: GPIO-controlled LED.phandle-array 类型解析:这种属性类型广泛用于 SoC 外设驱动中,用于引用其他设备树节点。在这里,它指向控制 LED 的 GPIO 控制器和引脚。
1.3 周期参数配置
blink-period-ms:
type: int
description: Initial blinking period in milliseconds.设计思想:通过设备树配置硬件参数,实现"硬件配置与软件逻辑分离"的现代嵌入式设计理念。
自定义 API 设计:子系统级抽象的艺术
步骤 2:驱动类 API 定义
2.1 API 结构体设计
在 include/blink.h 中定义:
__subsystem struct blink_driver_api {
/**
* @brief Configure the LED blink period.
* @param dev Blink device instance.
* @param period_ms Period of the LED blink in milliseconds, 0 to disable.
* @retval 0 if successful.
* @retval -EINVAL if period_ms can not be set.
* @retval -errno Other negative errno code on failure.
*/
int (*set_period_ms)(const struct device *dev, unsigned int period_ms);
};__subsystem 前缀的重要性:这个前缀告诉工具链这是一个设备驱动 API 结构,这对后续的宏助手正确工作至关重要。
2.2 公共 API 函数实现
static inline int z_impl_blink_set_period_ms(const struct device *dev,
unsigned int period_ms)
{
__ASSERT_NO_MSG(DEVICE_API_IS(blink, dev));
return DEVICE_API_GET(blink, dev)->set_period_ms(dev, period_ms);
}宏助手机制:
DEVICE_API_IS(class, device):验证设备是否属于特定类别
DEVICE_API_GET(class, device):获取设备类别的 API 实例指针
2.3 系统调用支持
__syscall int blink_set_period_ms(const struct device *dev,
unsigned int period_ms);系统调用设计价值:支持从用户模式和监督模式调用驱动 API,提高了系统的安全性和灵活性。
2.4 便利函数设计
static inline int blink_off(const struct device *dev)
{
return blink_set_period_ms(dev, 0);
}2.5 系统调用头文件包含
#include <syscalls/blink.h>任何声明系统调用的头文件都必须在文件底部包含这个特殊的生成头文件。
2.6 构建系统集成
zephyr_syscall_include_directories(include)驱动实现:自定义类别的具体化
步骤 3:GPIO LED 驱动实现
3.1 数据结构设计
struct blink_gpio_led_data {
struct k_timer timer;
};定时器驱动设计:使用 Zephyr 内核定时器实现周期性闪烁,体现了"事件驱动"的设计模式。
3.2 配置结构设计
struct blink_gpio_led_config {
struct gpio_dt_spec led;
unsigned int period_ms;
};3.3 API 结构绑定
static DEVICE_API(blink, blink_gpio_led_api) = {
.set_period_ms = &blink_gpio_led_set_period_ms,
};DEVICE_API 宏机制:这个宏将特定函数分配给特定设备驱动类别,建立了从抽象 API 到具体实现的映射关系。
设备定义:模板化的实例管理
步骤 4:设备定义模板
4.1 数据结构实例模板
static struct blink_gpio_led_data data##inst;4.2 配置结构实例模板
static const struct blink_gpio_led_config config##inst = {
.led = GPIO_DT_SPEC_INST_GET(inst, led_gpios),
.period_ms = DT_INST_PROP_OR(inst, blink_period_ms, 0U),
};设备树参数提取:
GPIO_DT_SPEC_INST_GET():解析并转换 GPIO 参数
DT_INST_PROP_OR():获取设备树属性,如果不存在则使用默认值
4.3 设备定义模板
DEVICE_DT_INST_DEFINE(inst, blink_gpio_led_init, NULL, &data##inst,
&config##inst, POST_KERNEL,
CONFIG_BLINK_INIT_PRIORITY,
&blink_gpio_led_api);4.4 初始化优先级配置
config BLINK_INIT_PRIORITY
int "Blink device drivers init priority"
default KERNEL_INIT_PRIORITY_DEVICE
help
Blink device drivers init priority.应用程序集成:完整的用户体验
步骤 5:应用程序配置与使用
5.1 设备树节点定义
/ {
blink_led: blink-led {
compatible = "blink-gpio-led";
led-gpios = <&gpio2 9 GPIO_ACTIVE_HIGH>;
blink-period-ms = <1000>;
};
};硬件抽象配置:
compatible:与绑定文件匹配的兼容字符串
led-gpios:指定 GPIO2 端口的第 9 号引脚,高电平有效
blink-period-ms:初始闪烁周期为 1000 毫秒
5.2 驱动启用配置
CONFIG_BLINK=y5.3 应用程序逻辑实现
/* 使用自定义 API 关闭 LED */
int ret = blink_off(blink);
if (ret < 0) {
LOG_ERR("Could not turn off LED (%d)", ret);
return 0;
}
while (1) {
/* 当 LED 保持常亮时,重新开始高闪烁周期 */
if (period_ms == 0U) {
period_ms = BLINK_PERIOD_MS_MAX;
} else {
period_ms -= BLINK_PERIOD_MS_STEP;
}
printk("Setting LED period to %u ms\n", period_ms);
/* 使用自定义 API 更改 LED 闪烁周期 */
blink_set_period_ms(blink, period_ms);
k_sleep(K_MSEC(2000));
}应用逻辑特点:
渐变效果:周期逐渐减少,创造视觉渐变效果
循环控制:当周期为零时重置为最大值,实现连续演示
错误处理:包含完整的错误检查机制
